추천 시스템
1. 추천 시스템이란?
추천 시스템은 사용자가 관심을 가질만한 콘텐츠들을 추천하는 것입니다.
사용자의 선호도 및 과거 행동을 토대로 사용자에 적합한 콘텐츠 추천을 제공합니다.
이미 현대 사회에서 추천 시스템은 다양한 분야에서 활용되고 있습니다.
예를 들자면 흔히 사용하는 유튜브나 넷플릭스, 왓챠 등에서 시청한 영상과 관련하여 유사한 영상을 추천하고 쿠팡이나 아마존 같은 온라인 마켓에서도 사용자의 과거 구매 이력을 토대로 유사한 물건들을 주로 보여주는 것을 알 수 있습니다.
2. 그렇다면 이 추천 시스템의 필요성은 무엇인가?
과거의 각 방송사 및 플랫폼의 성향에 맞게 영상이 제작되고 독립적인 흐름이 이루어졌다면, 현재는 수 많은 다양한 콘텐츠들이 종합되어 있는 사회에 살고 있습니다.
이렇게 방대한 콘텐츠들 사이에서 각 개인에게 맞는 콘텐츠를 고르기에는 비교적 쉬운 일은 아닙니다. 이러한 소비자들의 불편함을 해결하고자 추천 시스템이 탄생하였고, 사람들에게 개인화된 서비스를 제공하고 있습니다.
이러한 서비스 제공은 소비자 뿐 아니라 이를 제공하는 기업의 매출 향상에도 도움을 주기에, 추천 시스템은 기업의 성장에 필수적이라고 할 수 있습니다.
3. 추천 시스템의 역사
초기에는 기본적으로 소비자를 위한 '연관상품 추천 방식'을 토대로 추천 시스템 방식이 시작되었습니다. 이후 2006~2009까지 넷플릭스에서 자신들의 데이터를 기반으로 추천 시스템 대회를 개최하였습니다.
이 때 우승한 머신러닝의 SVD(Single Vector Decomposition) 방식을 기반으로 한 '협업 필터링 방식' 이 우승하게 되었고, 이 알고리즘을 기반으로 추천 시스템 모델의 연구가 활발하게 진행되었습니다. 협업 필터링 방식 Collaborative Filtering은 말 그대로 집단지성의 개념(당신의 취향과 유사한 사람들 대부분이 좋아하니 당신도 좋아하겠지!)과 유사하며, 오늘 설명할 Neural Collaborative Filtering과 연관됩니다.
그 이후 구글의 알파고에 힘입어 딥러닝이 발달하면서, 기존 한계점에서 벗어나기 위한 딥러닝을 이용한 추천 시스템이 발달하게 되었습니다. 현재는 Factorization Machine, 딥러닝 방식을 이용한 초개인화 추천 시스템 등으로 발전해 나가고 있습니다.
4. 추천 시스템에서의 딥러닝 활용
추천 시스템에서 딥러닝을 활용하게 된 이유는 오늘 설명할 논문의 내용과 연관이 있습니다. 우선 딥러닝은 머신러닝과 달리 대용량 콘텐츠를 가공 없이 input data로 사용할 수 있기에 대용량 콘텐츠의 특징 추출에 유리합니다. 또한 선형 모델들과 달리 알고리즘이 가지고 있는 비선형성으로 인해 선형으로 표현하는 것에 대한 한계점들을 극복할 수 있습니다. 이를 통해 복잡한 관계들도 해결할 수 있다는 장점이 있습니다.
추천 시스템은 이러한 딥러닝의 장점들로 인해 이를 활용한 개발이 지속적으로 이루어지고 있습니다.
5. 추천 시스템 기본 알고리즘
5.1 Content-Based Recommender System : 콘텐츠 기반 추천 시스템
이는 흔히 알고 있는 소비자의 과거 Contents와 관련하여 유사한 콘텐츠를 추천해주는 방식입니다.
이를 진행하기 위해서는 우선 데이터의 벡터화 작업이 필요합니다.
- 이미지 : CNN, ResNet VGG 등 다양한 알고리즘을 적용
- 자연어 : TF-IDF, Word2Vec-CBOW, Bert 등 자연어 처리 기술을 적용
각 데이터의 벡터화를 마쳤다면, 벡터 간의 유사도를 계산하여 아이템을 추천합니다.
- 유사도 계산 방법 : 유클리디안 유사도, 코사인 유사도, 피어슨 유사도 등
이러한 콘텐츠 기반 추천 시스템의 장점과 단점을 이야기 해보겠습니다.
장점
1) 추천하는 콘텐츠에 대한 근거를 벡터화한 콘텐츠 간의 유사성을 계산하여 이를 제시할 수 있습니다.
2) 새로 추가된 콘텐츠나 유명하지 않은 콘텐츠도 각 개인에 맞게 추천이 가능합니다.
단점
1) 사용자가 과거에 흥미가 있거나 관심을 갖는 콘텐츠를 제공하지 않는다면, 추천에 어려움이 따릅니다. (이를 보완하고자 처음 가입시 과거에 시청했던 영상들에 대한 평가를 받기도 합니다)
2) 사용자의 과거 contents를 기반으로 추천이 이루어지기에 완전히 새로운 콘텐츠가 아닌, 계속해서 유사한 콘텐츠만 추천하는 문제가 발생할 수 있습니다.
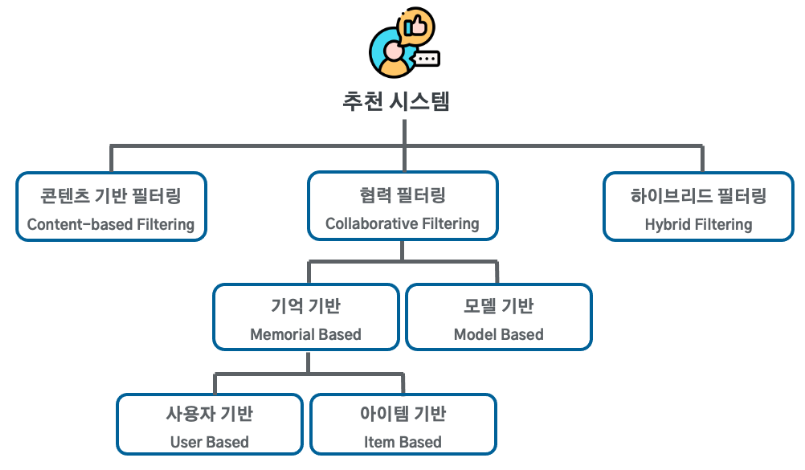
5.2 Collaborative Filtering : 협업 필터링
협업 필터링은 위에서 말했듯 '사용자의 취향과 비슷한 사람들이 선호하는 콘텐츠라면 사용자 또한 선호할 것이다' 라는 집단 지성의 개념을 이용하여 콘텐츠를 추천하게됩니다.
협업 필터링 방법에는 '메모리 기반 추천 알고리즘'과 '모델 기반 추천 알고리즘'이 존재합니다.
-
Memory-Based Algorithm : 메모리 기반 추천 알고리즘
가장 전통적인 접근 방식입니다. 이는 사용자 간 또는 콘텐츠 간의 유사도 계산 결과를 기반으로 예측이 필요할 때 새로운 사용자와 유사한 취향을 가지고 있는 다른 사용자가 선호하는 콘텐츠를 추천하거나, 특정 콘텐츠의 평점을 예측해야 하는 경우 다른 유사한 태깅이 있는 비슷한 콘텐츠의 평점 결과를 토대로 예측하는 방법입니다.
이 알고리즘은 사용자와 사용자 간의 유사도를 기준으로 추천해 주는 '사용자 기반(User-Based)' 방법과 아이템과 아이템 간의 유사도를 기준으로 추천해 주는 '아이템 기반(Item-Based)' 방법이 존재합니다. -
Model-Based Algorithm : 모델 기반 추천 알고리즘
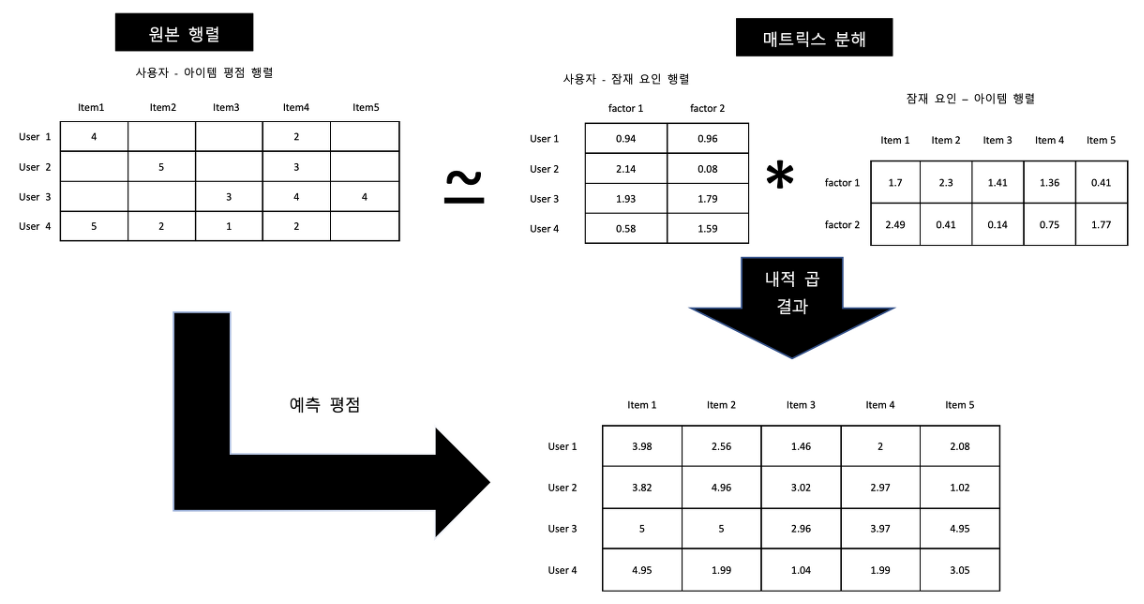
잠재 요인(Latent Factor) 협업 필터링 방법은 현재에도 자주 쓰이는 방법으로 '사용자와 아이템 간의 평점 행렬 속에 숨어 있는 잠재 요인 행렬을 추출하여 내적 곱을 통해 사용자가 평가하지 않은 항목들에 대한 평점까지 예측하여 추천하는 방법'입니다.
행렬 분해(Matrix Factorization)라는 방법을 통해 큰 다차원 행렬을 차원 감소 시키는 과정에서 행렬에 포함되어 있는 잠재 요인을 추출할 수 있습니다.