Balanced Multimodal Learning via On-the-fly Gradient Modulation
1. 논문의 Preview
멀티모달 학습은 다양한 감각 정보를 통합하여 세상을 더 종합적으로 이해하는 데 도움을 줍니다.
여러 입력 모달리티를 활용하면 모델의 성능이 향상될 것으로 기대되지만, 실제로는 멀티모달 모델이 단일 모달 모델보다 성능이 우수하더라도 모든 모달리티가 제대로 활용되지 않는 경우가 많습니다.
본 논문에서는 기존의 멀티모달 classification 모델들이 각 모달리티에 대해 균일한 목표를 설정함으로써, 특정 모달리티가 다른 모달리티의 학습을 억제할 수 있다는 점을 지적합니다. 예를 들어, 바람이 부는 상황에서는 소리, 그림을 그리는 상황에서는 시각이 우세할 수 있습니다.
이러한 최적화 불균형을 해결하기 위해, 본 논문에서는 'On-the-fly Gradient Modulation, OGM' 기법을 제안합니다. 이 기법은 각 모달리티의 학습 기여도를 모니터링하여 학습 과정을 동적으로 조절합니다. 또한, 그래디언트 조절로 인한 일반화 성능 저하를 방지하기 위해 동적으로 변하는 추가적인 가우시안 노이즈를 도입합니다.
본 논문에서 제안하는 OGM 기법은 멀티모달 학습 작업에서 기존의 융합 방법들보다 상당한 성능 향상을 보여주며, 다양한 멀티모달 작업에서도 효과적임을 입증합니다.
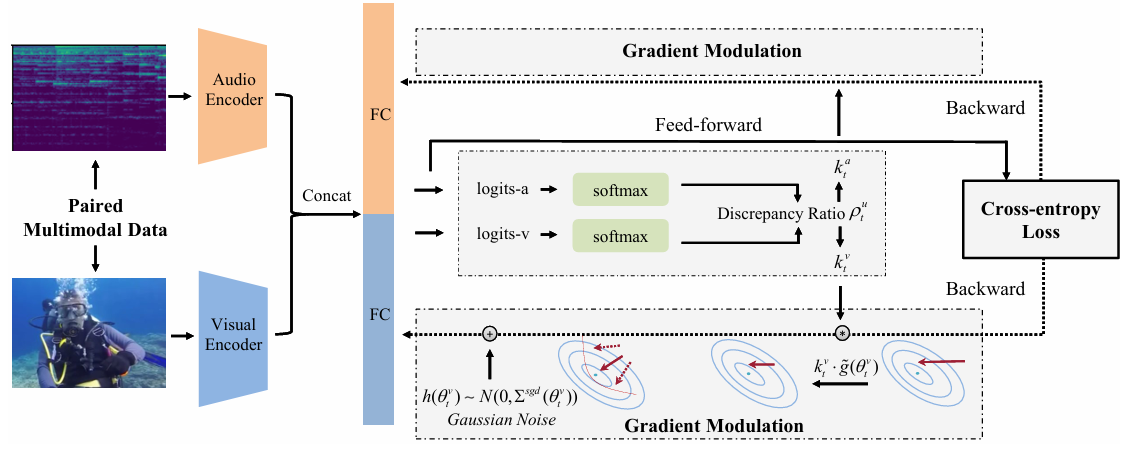
- 그렇다면 그래디언트 조절의 필요성은 무엇일까요?
기존 멀티모달 모델은 모든 모달리티에 대해 동일한 학습 목표를 설정합니다. 하지만 이는 모든 모달리티가 균등하게 기여하지 않도록 만들 수 있습니다. 위에서 언급한 예시와 같이 바람 소리가 중요한 상황에서는 시각적 정보가 덜 중요해질 수 있으며, 이런 상황에서는 시각 모달리티의 학습이 억제될 수 있습니다.
본 논문에서는 이러한 문제를 해결하기 위해, 각 모달리티의 기여도를 실시간으로 모니터링하고, 학습 과정에서 이 기여도에 따라 그래디언트를 조절하는 방식을 제안합니다.
본 논문에서 제안하는 OGM-GE 기법은 다양한 멀티모달 데이터셋에서 성능 향상을 보여주었습니다. 예를 들어, VGGSound 데이터셋을 사용한 실험에서는 시각과 청각 모달리티 모두에서 성능이 개선되었으며, 특히 시각 모달리티의 성능이 크게 향상되었습니다. 이러한 결과는 OGM-GE 기법이 단순한 융합 전략을 넘어, 멀티모달 학습의 일반화 성능을 효과적으로 향상시킬 수 있음을 보여줍니다.
2. related work
멀티모달 학습은 딥러닝 학습 분야에서 점점 더 주목받고 있는 학습 패러다임입니다.
멀티모달 데이터는 다양한 감각 정보를 포함하고 있어 자연스럽게 풍부한 상관관계를 지니고 있습니다. 멀티모달 학습의 연구는 다양한 응용 분야에 따라 나뉩니다.
ex1) 멀티모달 데이터 간의 관계를 비지도 학습 방식으로 탐구하여 하위 작업을 위한 의미 있는 표현을 학습
ex2) 멀티모달 정보를 활용하여 모델 성능을 향상시키려는 연구. 예를 들어, 행동 인식, 오디오-비주얼 음성 인식, 시각적 질문 응답 등
하지만 대부분의 멀티모달 방법들이 공동 학습 전략을 활용할 때 모든 모달리티를 완벽하게 활용하지 못하고, 단일 모달리티의 표현이 최적화되지 않는 경우가 많습니다. 이로 인해 멀티모달 모델이 예상한 성능에 미치지 못하는 경우가 발생합니다.
- 불균형 멀티모달 학습
이는 모달리티 간의 불일치로 인한 문제입니다.
서로 다른 모달리티가 서로 다른 수렴 속도를 가지기 때문에 공동 학습된 멀티모달 모델이 단일 모달 모델과의 성능 차이를 보일 수 있다고 밝혔고, TVQA 데이터셋에서 텍스트 자막 모달리티에 대한 본질적인 편향이 존재한다고 보여주었습니다.
최근에는 이러한 문제를 해결하려는 여러 방법들이 등장했습니다.
모달리티의 과적합 행동을 기반으로 최적의 블렌딩을 얻기 위한 Gradient Blending을 제안하거나, 잘 학습된 단일 모달 모델로부터 Knowledge Distillation을 통해 unimodal encoder를 강화하는 방법을 사용했습니다. 이러한 방법들은 어느 정도 개선을 가져오지만, 추가적인 신경 모듈을 도입해야 하므로 훈련 과정이 복잡해집니다.
본 논문에서는 최적화 관점에서 이 문제를 다루기 위해 추가적인 모듈 없이 각 모달리티의 최적화를 동적으로 제어하는 방법을 제안합니다.
- Stochastic gradient noise
SGD의 그래디언트 노이즈는 딥 모델의 일반화 능력과 중요한 상관관계를 가지는 것으로 알려져 있습니다. 이러한 확률적 그래디언트 노이즈는 무작위 미니 배치 샘플링에 의해 도입되며, 정규화 역할을 하고 모델이 안장점이나 지역 최적점을 탈출하도록 돕는 것으로 여겨집니다.
확률적 그래디언트 알고리즘이 적절한 가우시안 노이즈와 함께 사용할 경우, 무작위 초기화와 함께 다항 시간 내에 전역 최적점에 수렴할 수 있다는 이론적 증거도 존재합니다.
본 논문에서는 멀티모달 모델의 일반화 능력을 향상시키기 위해, 그래디언트에 추가적인 가우시안 노이즈를 도입하고 이를 통해 상당한 개선을 달성하였습니다. 이러한 배경 지식을 통해 본 논문에서 제안하는 OGM 기법이 어떻게 멀티모달 학습의 성능을 획기적으로 향상시킬 수 있는지 뒷 내용들에서 자세하게 살펴보겠습니다.
Preview )
OGM 기법은 각 모달리티의 학습 기여도를 실시간으로 모니터링하고, 동적으로 조절하여 최적화 불균형 문제를 해결하며, 일반화 성능을 높이기 위해 그래디언트에 가우시안 노이즈를 추가하는 방식을 사용합니다.
3 Method
3.1 optimization imbalance analysis
멀티모달 학습에서 최적화 불균형 현상은 멀티모달 모델의 성능을 저해할 수 있는 중요한 문제입니다.
본 논문에서는 이 문제를 분석하여, 성능이 더 좋은 모달리티가 최적화 과정을 지배하게 되어 다른 모달리티가 충분히 최적화되지 않는 현상을 설명합니다.
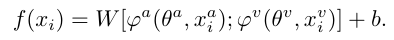 멀티모달의 전체 프레임이 위와 같다면(concat 기준), 이를 각각의 모달리티에 대해 분해하여 아래와 같이 살펴볼수 있습니다
멀티모달의 전체 프레임이 위와 같다면(concat 기준), 이를 각각의 모달리티에 대해 분해하여 아래와 같이 살펴볼수 있습니다 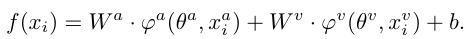 그랬을 때, weight update에 관한 식은 Gradient Descent (GD) 최적화 방법을 사용하여 아래와 같이 작성할 수 있게 됩니다.
그랬을 때, weight update에 관한 식은 Gradient Descent (GD) 최적화 방법을 사용하여 아래와 같이 작성할 수 있게 됩니다.
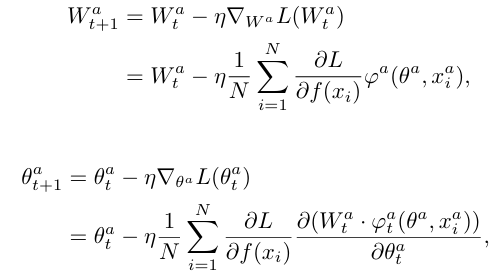
위의 식을 보면 와 의 최적화는 거의 다른 모달리티와 상관이 없음을 알 수 있습니다. 이는 단지 훈련 손실 에 의존하기 때문입니다. 따라서 단일 모달 인코더는 서로의 피드백에 따라 조정하기 어렵습니다.
그 다음, 다음과 같이 Gradient를 다시 쓸 수 있습니다:
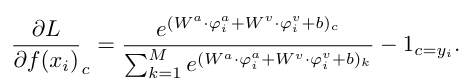
여기서 와 를 각각와 로 간단히 표현했습니다. 클래스 에 속하는 샘플 의 경우, 비주얼 모달리티가 더 나은 성능을 발휘할 때, 를 통해 에 더 많이 기여하게 되어 전반적인 손실이 낮아지게 됩니다.
=> 그에 따라 오디오 모달리티는 상대적으로 낮은 신뢰도를 가지게 되며, 그로 인해 최적화 노력이 제한적일 수 있습니다.
Visual model부문의 많은 기여로 인하여 꽤 좋은 결과를 나타내고, 그렇기에 굳이 Audio model부문의 업데이트를 많이 진행할 이유가 없어지게 됩니다.
이는 더욱 우수한 성능을 이끌 수 있는 가능성이 있음에도 불구하고 최적화가 진행되지 못 하는 결과를 초래하게 되는 것 입니다!
즉, 이 현상은 성능이 좋은 모달리티가 최적화 진행을 지배하게 되고, 결국 다른 모달리티는 여전히 최적화되지 않은 표현을 가지게 되어 추가적인 학습이 필요할 수 있음을 나타냅니다.
3.2. On-the-fly gradient modulation
멀티모달 학습에서 On-the-fly Gradient Modulation (OGM)을 통해 어떻게 최적화를 조절하는지 알아보겠습니다. 멀티모달 모델에서 각 모달리티의 성능이 다를 때, 그로 인해 최적화 과정에서 불균형이 발생할 수 있습니다. 이러한 문제를 해결하기 위해 OGM 전략을 도입하는 방법을 설명하겠습니다.
먼저, 멀티모달 모델에서 하나의 모달리티가 더 나은 성능을 발휘할 경우, 위에서 다룬 바와 같이 다른 모달리티는 상대적으로 덜 최적화될 수 있습니다.
=> 이 문제를 해결하기 위해 OGM 전략에서는 각 모달리티의 기여도를 모니터링하고 그에 따라 gradient를 조절합니다.
1. 기여도 불일치 비율 계산
OGM에서는 각 모달리티의 기여도를 비교하는 지표를 사용합니다. 이를 위해 기여도 불일치 비율 를 정의합니다.
여기서 는 모달리티를 의미하며, 는 오디오, 는 비주얼을 나타냅니다.
1.1. Softmax 함수를 사용하여 각 모달리티의 기여도를 계산합니다.
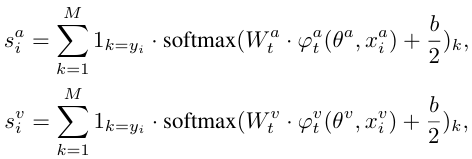 여기서 는 오디오 모달리티의 기여도, 는 비주얼 모달리티의 기여도를 나타냅니다.
여기서 는 오디오 모달리티의 기여도, 는 비주얼 모달리티의 기여도를 나타냅니다.
1.2. 기여도 비율 는 다음과 같이 정의됩니다:
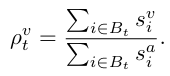 여기서 는 t번째 단계에서 선택된 미니 배치입니다.
여기서 는 t번째 단계에서 선택된 미니 배치입니다.
1.3. 기여도 비율은 서로 역수 관계를 나타냅니다.
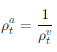
2. Gradient Modulation
기여도 비율을 기반으로 각 모달리티의 gradient를 조절합니다. 이를 통해 최적화 진행을 조절할 수 있습니다.
2.1. Modulation Coefficient는 다음과 같이 정의됩니다:
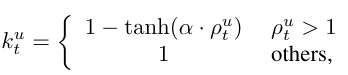
여기서 α는 조절 정도를 제어하는 하이퍼파라미터입니다. 함수는 기여도 비율 가 클 때 gradient의 조정을 줄여줍니다.
2.2. Gradient Update는 다음과 같이 이루어집니다:
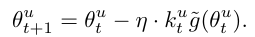
여기서 는 전체 gradient의 불편 추정치입니다.
이러한 방식으로, 성능이 더 나은 모달리티가 최적화 진행을 지배하지 않도록 하고, 다른 모달리티가 충분히 업데이트될 수 있도록 합니다.
즉, 성능이 더 나은 모달리티에 대한 최적화를 조금 줄이고, 성능이 낮은 모달리티에 대한 최적화 노력을 더 많이 부여(고정)하여 전체 모델의 균형 잡힌 학습을 유도할 수 있습니다. 이러한 OGM 전략을 통해 각 모달리티의 최적화 과정이 독립적으로 조절되어, 최적화 불균형 문제를 완화할 수 있습니다.
3.3. Generalization enhancement
본 논문에서는 멀티모달 모델의 일반화 성능을 향상시키기 위한 방법으로 "On-the-fly Gradient Modulation"(OGM) 전략을 소개합니다. 이를 통해 SGD(확률적 경사 하강법) 최적화에서 발생할 수 있는 일반화 성능의 손실을 개선하고자 합니다.
먼저, SGD의 기본 원리를 이해하는 것이 중요합니다.
SGD를 사용할 때, 배치 크기 m가 충분히 크면, 그래디언트 는 중앙 극한 정리에 따라 정규 분포를 따릅니다. 즉, 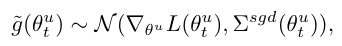
이며, 여기서 시그마는 다음과 같이 정의됩니다.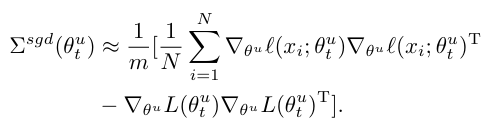
앞에서의 식 7번인 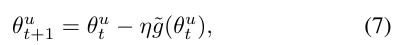
이 식은, 다음과 같이 일반화 성능을 위한 노이즈 항이 포함되어 있는 것으로 다시 작성해 볼 수 있습니다.
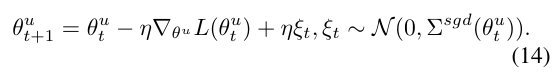
SGD의 노이즈는 모델의 일반화 능력과 밀접하게 관련되어 있으며, SGD 노이즈가 클수록 일반화 성능이 향상되는 경향이 있습니다. 일반적으로, SGD 노이즈의 공분산은 학습률과 배치 크기의 비율에 비례합니다.
그라디언트 조절과 일반화 향상
• 문제점: OGM 전략을 사용하여 그라디언트를 조절하면(수식 15) 그라디언트 노이즈의 크기 가 줄어들 수 있습니다. 이는 일반화 능력을 저하시킬 가능성이 있습니다.
• 일반화 향상 방법: 이를 해결하기 위해, 저자들은 그라디언트에 가우시안 노이즈 를 추가하는 일반화 향상 (GE) 방법을 제안합니다. 이 노이즈는 기존의 그라디언트와 동일한 공분산을 가지며, 현재의 학습 단계에 따라 동적으로 변합니다.
• 최종 업데이트: 수식 (16)에서는 이 추가 노이즈 를 포함하여 파라미터 를 업데이트하는 과정을 보여줍니다. 결과적으로 수식 (17)에서 노이즈의 공분산이 회복되며, 심지어 기존보다 더 커져 일반화 능력이 향상될 수 있습니다.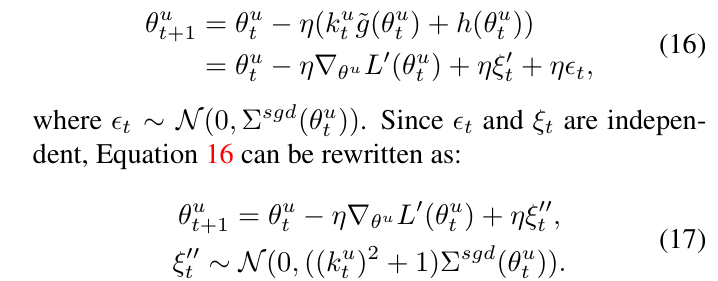
아래의 수도코드에서는 이러한 과정들을 요약하여, OGM-GE 전략을 사용하는 다중 모달 학습 방법을 제시하고 있습니다. 이 알고리즘은 데이터셋에서 미니배치를 샘플링하여 그라디언트를 계산하고, 그라디언트 노이즈를 추가하여 파라미터를 업데이트하는 절차로 구성됩니다.

정리 및 결론
논문에서는 OGM-GE (On-the-fly Gradient Modulation with Generalization Enhancement)라는 간단하지만 효과적인 멀티모달 학습 전략을 제안하고 있습니다.
이 방법은 최적화 불균형 문제를 완화시켜 두 모달리티를 모두 활용할 수 있도록 돕습니다. OGM-GE는 네 가지 대표적인 멀티모달 데이터셋에서 일관된 성능 향상을 달성하였으며, 일반적으로 기본적인 융합 방법이나 특별히 설계된 융합 방법, 기존의 멀티모달 모델에도 유연하게 적용될 수 있는 전략입니다.
하지만 몇 가지 한계점이 존재합니다. OGM-GE를 적용하더라도 멀티모달 모델의 단일 모달 성능이 가장 우수한 단일 모달 모델을 초월하지 못하는 문제가 해결되지 않은 한계점이 존재했습니다. 이는 최적화 중심의 방법만으로는 불균형 문제를 완전히 해결할 수 없다는 가설을 뒷받침하며, 따라서 더 발전된 융합 전략이나 네트워크 아키텍처와 같은 다른 접근 방식을 조사할 필요가 있습니다.
그럼에도 불구하고 OGM-GE의 다양한 변형 및 연구가 이루어진다면, 더 많은 멀티모달 시나리오에서 큰 잠재력을 시사할 수 있을 것이라 판단됩니다.
