GAN의 단점으로는 단방향이라는 점이다.
즉, 이미지를 latent vector로 정확하게 보낼 수 없다는 것인데 왜 이것이 단점이 될까?
우리는 단순히 이미지를 generate하는 것이 목적이 아닌가?
=> 이에 대한 이유로는 이미지 editing을 실시할 수 있어지기 때문이다.
따라서 이에 대한 양방향을 배우도록 설계된 GAN도 존재한다.
정리하자면 GAN은 Amazing empirical results와 fast inference라는 장점을 가지고 있고, 단점으로는 내재적 평가 지표 부족, 불안정한 훈련, 모델에 내제된 밀도 추정 없음, 특히 모델이 매우 크고 잠재적 인 위치를 찾기가 어려운 경우 이미지를 잠재 공간 표현으로 반전시키는 것이 어려울 수 있다는 것이 존재한다.
지금까지 GAN의 장점과 단점에 대해 봤다면, 이러한 단점 중 일부가 다른 접근 방식으로 어떻게 해결되는지 살펴보자!
우선 대체 방안으로 genenrative model들 중 유명한 VAE가 존재한다.
VAE는 아래와 같다. GAN과는 달리 Encoder와 Decoder가 존재하여, 디코더를 통해 image를 generate라게 된다.

따라서 높은 수준의 VAE에서는 생성 된 배포판과 실제 배포판 사이의 분산을 최소화하려고 한다. 그리고 이것은 종종 안정적이거나 훈련을 초래하는 약간 쉬운 최적화로 간주되며, 이는 또한 흐릿한 결과 또는 낮은 충실도 결과를 초래할 수도 있긴 하다.
그렇기에 VAE의 단점으로는 퀄리티가 낮다는 점이 존재한다.
하지만 그에 반해 장점으로는 density estimation을 가지고 있고, latent space를 구성하는 인코더가 존재하기에 invertible하며, 훈련이 안정적이라는 점이 있다.
추가적으로 VAE esque 모델을 알아보자면 VQ-VAE2 VAES에서 많은 개념을 빌렸지만, 실제로는 순수한 VAE 솔루션으로 간주되지 않는다. 사실, auto regressive network에 의존하는데, 이는 다음 픽셀을 결정하기 위해 이전 픽셀만 보는 모델이다. 그래서 여기에 몇 픽셀을 보게되면 그 이미지의 나머지 픽셀을 결정할 수 있다. 그리고 이것은 또 다른 유형의 generative model이며, 이전 픽셀을 기준으로 픽셀 단위로 이동한다. 그렇기에 다음 픽셀이 무엇인지 생각할 수 있는데, 마치 RNN 또는 언어 및 음성 모델에 익숙하다면, 미래를 볼 수 있는 개념과 매우 유사하다. 그리고 이 모델은 이전 픽셀에 의존하기 때문에 fully unsupervised라고는 할 수 없다.
다른 generative model을 또 확인해보자면, Flow Model이 존재한다.
학습시키기에는 어렵지만, invertible mapping이 가능하다는 큰 장점이 존재한다.
Machine bias에 관하여
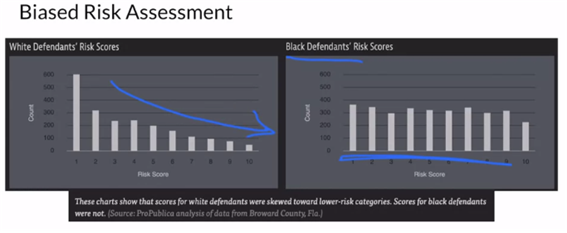
범죄 추정과 관련하여 기계가 추정했을 때, 이와 같이 흑인들의 risk score값이 훨씬 높다는 것을 확인할 수 있다. 이러한 부정확한 bias가 첨가되어 있는 판단들은 이로 인한 피해가 막연하기에 절대적으로 공정하다고 할 수 없다. 그렇기에 단순히 모델의 성능 뿐 아니라 Machine bias와 같이 실질적으로 누구에게 도움이 되며, 피해를 받게 되는 경우는 어떤 것 들이 있는 지 잘 확인해 보아야 한다.
- 인공지능의 편향과 공정성의 개념과 중요성
- 데이터 편향, 알고리즘 편향, 사용 편향의 원인
- 편향과 공정성의 평가 방법 : 차별성, 불평등성, 신뢰성
- 편향과 공정성의 완화 방법 : 데이터에 내재된 편향을 완화
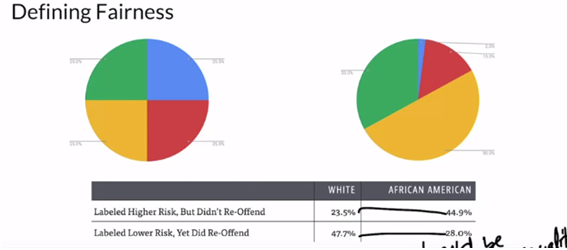
모델이 공정한 지 어떻게 구체적으로 측정할 것인가?
Does Object Recognition Work for Everyone? 은 객체 인식 시스템이 다양한 인구 집단에서 어떻게 작동하는 지 조사한 논문이다.
이 논문에서는 객체 인식 시스템은 다양한 분야에서 사용되고 있으며, 다양한 인종 및 그룹에 대해 편향을 가질 수 있음을 말하며, 아래와 같은 결과를 말했다.
- 인종: 흑인과 히스패닉에 대한 인식률이 백인에 비해 낮았습니다.
- 성별: 여성에 대한 인식률이 남성에 비해 낮았습니다.
- 연령: 청소년과 노인에 대한 인식률이 성인에 비해 낮았습니다.
즉, 이러한 편향들을 극복하기 위해서는 인식률, 정확도, 재현율 등을 잘 살펴야 하며, 다양한 그룹을 포함하는 큰 데이터셋과 다양한 알고리즘을 적용하는 객체 인식 시스템을 이용하여 평가해야 한다고 향후 연구 방향에 대해 밝혔다.
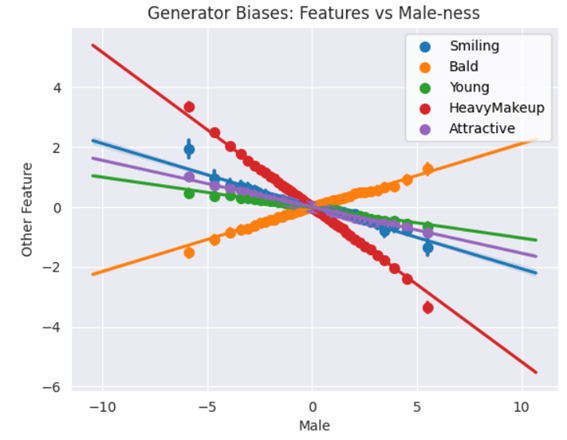
이러한 상관관계 탐지는 생성기 학습 중 손실에서 이러한 유형의 상관관계에 페널티를 부여하여 편향을 줄이는 데 사용할 수 있습니다. 하지만 현재로서는 GAN을 debiasing하기 위한 엄격하고 인정된 솔루션이 없습니다. 올바른 방향으로 나아가기 위한 첫 번째 단계는 모델을 훈련하기 전에 데이터 세트가 포괄적이고 대표성을 지니고 있는지 확인하고, 사용한 데이터 수집 방법(예: 작업에 적합한 대표 labeler 확보)으로 인한 편향성을 완화할 수 있는 방법을 고려하는 것입니다.
하지만 많은 연구자들이 강조한 것처럼, 다양한 데이터 세트만으로는 편향을 제거할 수 없다는 점에 유의해야 합니다. 다양한 데이터 세트조차도 일반적인 사회적 편견을 포착함으로써 기존의 구조적 편견을 강화할 수 있습니다. 이러한 편견을 완화하는 것은 중요하고 활발한 연구 분야입니다.
