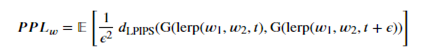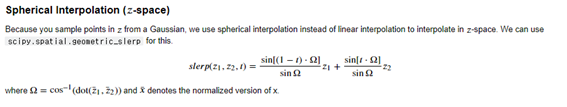GAN의 평가가 어려운 이유
random noise를 통해 genenrate했는데, 어떻게 평가할 것인가?
마치 명작을 그리는 법을 배우는 고급 예술가와 같다.
옳고 그름이 명확히 없다.
그렇다면 어떤 관점으로 평가하는 것이 좋을까?
1) Fidelity
생성 된 이미지의 품질, 그리고 그들이 얼마나 사실적인지
2) Diversity
단순히 특정 하나만 잘 생성하는 것은 GAN의 목적성에 부합하지 않다. 다양한 실제로 있을 법한 이미지들을 만들어 내는 것 또한 중요하다.
what exactly should you be comparing?
-
Pixel Distance : 픽셀간의 값을 비교하는 것인데, absolute error를 보면 실질적으로 이미지가 비슷해 보이더라도 error값의 크기가 엄청날 수 있다.
-
Feature Distance : 쉽게 말해서 눈 코 입 등의 feature간 비교를 하는 것이다. 이렇게 하면 배경이 다르더라도 각 이미지의 class를 잘 구분할 수 있다.
Feature Distnace를 구하기 위해 우선적으로 Feature extraction을 실시한다.
pretrained classifie model을 가져와 각 눈 코 입에 맞는 특징(물론 이런 정확한 특징이 아닌 추상적 특징)을 추출하고, 이를 이용해서 비교를 진행하는 것이다. 물론 뒷 단 layer들은 자르고 우리의 정보에 맞게 구성한다.
많은 Pre-trained model들이 있겠지만, 차후 Frechet Inception Distance(FID)를 알아보기 위해 Inception-v3를 알아보자.
input 229x229x3 -> output8x8x2048 –Pooling layer(8x8)-> 1D 2048로 압축 가능
이 압축된 저차원의 벡터를 비교!
예를 들어 아래와 같은 그림을 보면, fake쪽에 있는 이미지는 밝은 털, 코를 가지고 있기에 2048 vector가 유사하게 나올 것이다. 반면 real쪽에 있는 이미지는 검정 코를 가지고 있기에 fake와 다른 값을 갖는 벡터로 표현된다. 이를 pixel간 차이로 봤다면!? 값의 차이가 너무 커 비교하기에 쉽지 않을 것이다.
다시 말해 real 임베딩 값과 fake 임베딩 값의 차이를 계산하는 것이다. 이를 많은 샘플들을 통해 FID로 score를 낸다.

이제 실제 이미지와 생성된 이미지 사이의 형상 거리를 측정하는 데 가장 많이 사용되는 지표인 Frechet Inception distance를 알아보자.
우선 Frechet Distance에서 쉽게 정규분포로 생각한다.
평균은 중심에 대한 감각, 표준편차는 확산의 감각
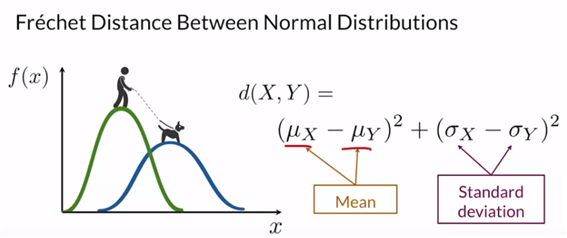
당연히 다변량 정규분포에 대해서도 생각 가능하다. 쉽게 생각하면 각 차원에 대해서 일변량 정규분포를 가지고 있다고 생각하면 된다.
자연스럽게 공분산 행렬을 생각해볼 수 있는데, diagonal에 있는 값은 각 차원에서의 분산이다. 그렇기에 값이 클수록 좁고 peak가 높은 형태가 된다. 행렬의 나머지는 각 차원 사이의 상관관계를 나타낸다. 즉, 0이면 두 차원은 독립이다.
즉 다변량 정규분포에서의 Frechet Distance는 아래와 같이 일변량에서 일반화시킬 수 있다.
(Tr은 행렬의 대각합 trace : 그렇기에 다른 차원 간의 공분산은 실제 고려되지 않는다.)
그렇기에 GAN에서 사용하는 지표는 아래와 같이 작성할 수 있으며, 이 값이 작을수록 실제와 가짜 분포 사이가 가까운 것이다. 하지만 FID score는 샘플들의 수에 따라 값이 다르게 나온다. 샘플 수가 많을수록 평균적으로 점수가 낮게 나오고, 또한 정규분포를 가정해야 한다는 점, 기타 왜도와 첨도 등은 고려하지 않고 평균과 공분산만을 다룬다는 점이 아쉽다. 그럼에도 이 가정을 통해 FID의 구현과 사용이 쉽기에 GAN을 평가하는 가장 일반적인 방법이다.

이번에는 Inception score에 대해 알아볼 것인데, 이는 FID 이전에 나왔다. 이 score는 conditional generate와 더 관련이 깊다.
이전과 달리 모델을 자르지 않고 통째로 다 사용한다.
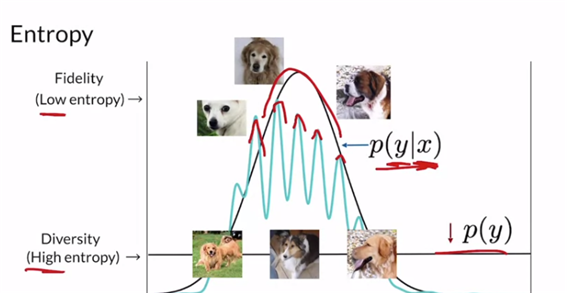
KL-div에 대해 살펴보면 두 분포간을 비교하는 것인데, 방향이 바뀌면 값이 달라지기에 distance는 아니라는 특징이 있다. p(y)가 균등분포일수록 diverse하기에 높은 엔트로피 값을 갖고, p(y|x)는 잘 뽑아서 peak가 높다면 fidelity가 높은 것으로 엔트로피가 낮을 것이다.
즉, GAN에 의해 generate된 이미지 x는 고유한 class label을 잘 가지고 있고, 생성된 이미지 전체 집합이 다양한 범위의 label을 가질 때 점수가 높은 것이다!
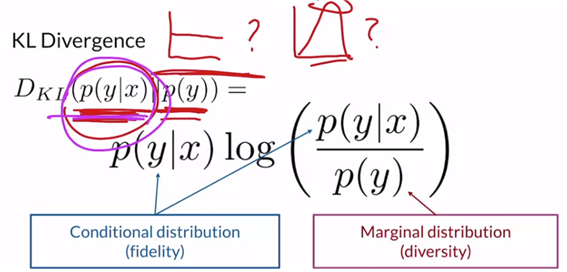

이 KL-div를 통해 inception score를 정의하며, 아래와 같다. 값이 클수록 좋은 성능을 낸다고 해석할 수 있다.
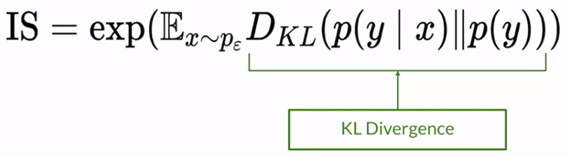
이 Inception score의 단점으로는 generate “one” realistic image of each class라는 것과 오직 fake imges만 본다는 점과 imageNet에 없는 것은 좋은 score를 내지 못 한다는 점이 존재한다.
위에서 알아본 FID의 경우 비교할 샘플들을 어떻게 뽑냐에 따라 굉장히 다른 점수가 나올 것이다. 그렇기에 샘플링이 굉장히 중요하며, 여기서 몇 가지 트릭을 알아보자.
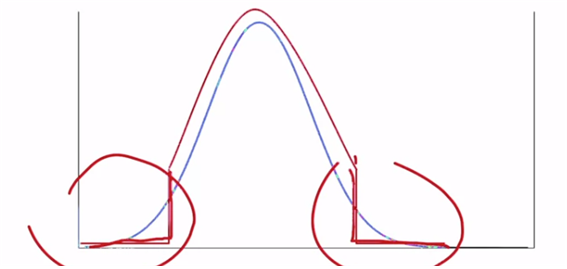
Truncation Trick
분포를 빨간색과 같이 변경하여 low quality를 없애버리는 것이다.
By sampling at test time from a normal distribution with its tails clipped.
fidelity를 집중한다면 truncate를 많이 하여 sampling을 한다.
diversity를 집중한다면 적게 truncate를 하여 sampling한다.
trade-off를 잘 고려하여 알맞은 지점을 선정할 수 있다.
HYPE : Human eYe Perceptual Evaluation
HYPE(time) 은 real image와 fake image가 있을 때, 이를 얼마나 바로 구별할 수 있는지에 대한 것이다. 실제로 맞추면 시간을 줄이고 틀리면 시간을 늘리는데 총 평균을 구하면 점수가 된다. 높은 점수를 받는다는 것은 real 과 fake를 잘 구분하지 못한다는 것이기에 좋다고 할 수 있다.
HYPE(infinity) 는 시간이 무한대일 때, fake와 real을 착각하는 비율이다. 점수가 50%가 넘는다면 그냥 찍는 것이라 해석할 수 있기에 좋다고 할 수 있다.
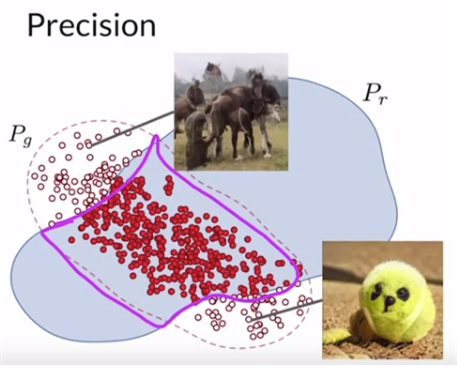
Precision and Recall
아래와 같은 경우는 Pg가 Pr에 겹치는 부분이 많고, peak가 겹칠수록 좋다고 할 수 있다.
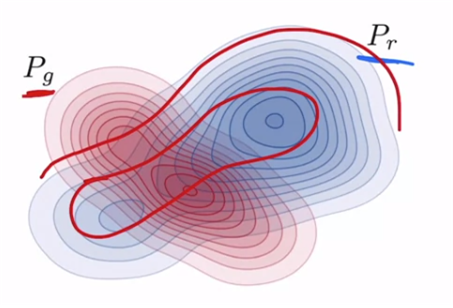
첫 번째로 Precisoin을 알아보면, overlap fake pts / all pts which is generated 이다. 이것은 fidelity와 연관되어 있다. precision이 높을수록 샘플들의 퀄리티가 높다.
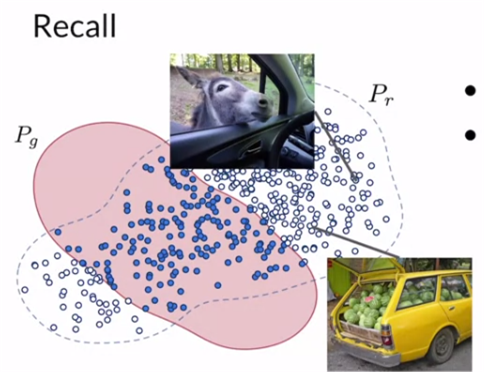
recall은 overlap real pts / real pts 이다. 이것은 diversity와 연관되어 있다. 즉, genenrator가 실제의 모든 variation을 얼마나 잘 모델링하는 지에 대한 측정값이다.
주로 recall이 precision보다 높다. 그렇기에 위에서 언급한 truncated trick을 통해 precision을 높인다.
“Improved Precision and Recall Metric for Assessing Generative Models”
본 논문에서는 특정 공간으로 mapping or embedding을 통해 이 분포에 대한 향상된 Precision과 Recall에 대해서 말한다.
아래와 같이 수식을 전개할 수 있는데, f는 특정 벡터가 해당하는 분포의 특정 클러스터에 들어가는지 여부를 KNN을 이용해서 정의한다. 즉, KNN알고리즘을 통해 real과 fake분포의 mainifold를 근사시킨다. 이렇게 특정 특징 벡터가 어떤 manifold에 들어가느냐를 확인한다. 실제 이미지 분포에 포함되는지, 생성된 분포에 해당하는지 판단한다. 이렇게 f를 통해 나온 값을 이용해 precision과 recall을 정의하여 값을 도출해내는 방법이다.

이렇게 GAN의 평가 방법에 대해 알아보았는데, 특정하게 가장 좋은 것은 없으며 각자의 특징에 따라 적합한 방법을 사용해야 한다.
추가적으로 Perceptual Similarity가 있다.
Perceptual Similarity
Perceptual path Length(PPL)라고 한다. 이전에 알아본 FID와 마찬가지로 PPL도 심층 컨볼루션 신경망의 특징 임베딩을 사용한다. 구체적으로는 “The Unreasonable Effectiveness of Deep Features as a Perceptual Metric by Zhang et al (CVPR 2018)” 논문에 나온 두 이미지 임베딩 사이의 거리를 사용한다. 이 접근 방식에서는 FID와 달리 InceptionNet 대신 VGG16 네트워크가 사용된다.
Perceptual Similarity은 두 특징 벡터 사이의 거리와 매우 유사하지만, 한 가지 중요한 차이점이 있다. 특징은 이미지 유사성에 대한 인간의 직관과 일치하도록 학습된 변환을 거친다. 특히, 기본 이미지에서 다양한 변환이 적용된 두 이미지를 보여줄 때 LPIPS("Learned Perceptual Image Patch Similarity") 메트릭은 사람들이 더 가깝다고 생각하는 이미지의 거리가 더 짧다는 것을 의미한다.