이미지는 빨강, 녹색 또는 파랑(RGB) 색상의 강도를 나타내는 0에서 256까지의 정수로 표현됩니다. 단백질도 마찬가지로 문자를 사용하여 아래와 같이 20개의 고유한 아미노산을 나타냅니다:
MKYATLLEYAFQALKNSYAPYSRFRVGAALLSDDGEVVTGCNVENASYGLSMCAERTAVFRAVAQGVKKFDAIAVVSGKVNPVYPCGACRQVLREFNPRLTVVVAGPGKKPLTTSLDKLLPKSFGKESLRRR
단백질이 기능을 유지하도록 '생화학적으로 의미 있는' 방식으로 단백질을 무작위로 변형하는 것은 매우 어렵고 실험에 많은 시간과 비용이 소요됩니다. 따라서 기능을 유지하는 자연과 같은 다양한 단백질을 생성하는 것은 생명공학 및 생물의학 응용 분야에서 매우 중요합니다.
이미지와 단백질 모두 GAN에 적합한 후보가 되는 두 가지 중요한 공통된 특징이 있습니다:
1) 아미노산이든 픽셀이든 빌딩 블록의 무작위 조합은 사실적인 결과를 생성하지 못합니다. 즉, GAN은 단순히 추측할 수 없습니다! 의미 있고 사실적인 픽셀과 아미노산 패턴을 모델링하고 생성해야 합니다.
2) 생성된 항목의 정확성을 평가하는 방법에 대한 수학 공식은 알려져 있지 않습니다. 이미지의 경우, 생성된 강아지 이미지가 얼마나 사실적으로 보이는지, 즉 정확성이 '사실성'입니다. 이에 대한 수학 공식은 없으므로 대신 다른 모델(판별자!)이 이를 평가하는 방법을 배워야 합니다. 단백질도 마찬가지이기에 GAN을 사용하기에 적합한 것 입니다.
추가적으로 차이점을 설명하자면, 이미지와 단백질의 가장 큰 차이점 중 하나는 데이터 유형입니다. 이미지는 연속적인 값으로 구성되는 반면, 단백질은 불연속적인 빌딩 블록으로 구축됩니다. 이러한 역전파 문제를 해결하기 위해 ProteinGAN은 온도와 함께 이산 데이터 샘플링에 대한 차별적인 근사치 역할을 하는 검벨-소프트맥스(Gumbel-Softmax) 트릭을 사용합니다. 이를 통해 이산 입력 공간에서 작동하면서 판별기와 생성기의 엔드투엔드 훈련이 가능합니다.
정리하자면, 단백질은 자연이 수십억 년에 걸친 진화를 통해 필수적인 생명 과정을 주도하기 위해 조정한 20개의 아미노산(AA)으로 이루어진 비임의적 서열입니다.
이러한 단백질과 같은 긴 생물학적 서열을 학습하는 데 ProteinGAN을 통해 어려운 점을 잘 설명합니다.
이 ProteinGAN을 통해 genenrator로 사이티딘 탈아미나아제 제품군에서 무작위 단백질 서열 생성하고, 서열 정렬 및 차원 축소를 사용해 생물학적 서열 시각화합니다. 그리고 잠재 공간 차원을 탐색하고 이를 생성된 단백질의 물리화학적 특성과 연결합니다.
Wasserstein GAN(WGAN) with Gradient Penalty A to Z code making
: https://github.com/KiHwanLee123/Coursera---GAN/blob/main/C1W4A_Build_a_Conditional_GAN%20(1).ipynb

InfoGAN?
지금까지는 condition을 통해 0을 만들어줘 혹은 7을 만들어줘와 같이 특정 class를 만들어낼 수 있었다.
하지만 선의 굵기를 얇게 해줘, 사람의 피부색, 눈동자색, 표정 등과 같은 특징은 첨부할 수는 없었다. 이를 적용할 수 있게 한 것이 InfoGAN이다.
그렇다면 어떻게 적용할 수 있을까?
지금까지의 GAN은 noise를 균등분포에서 임의로 샘플링하여 이미지를 생성했다. 그렇다면 이 노이즈에 해당하는 얽힌 잠재 코드를 분해된 코드로 풀어낼 수 있다면?!
(여기서 코드는 의미를 가진 벡터)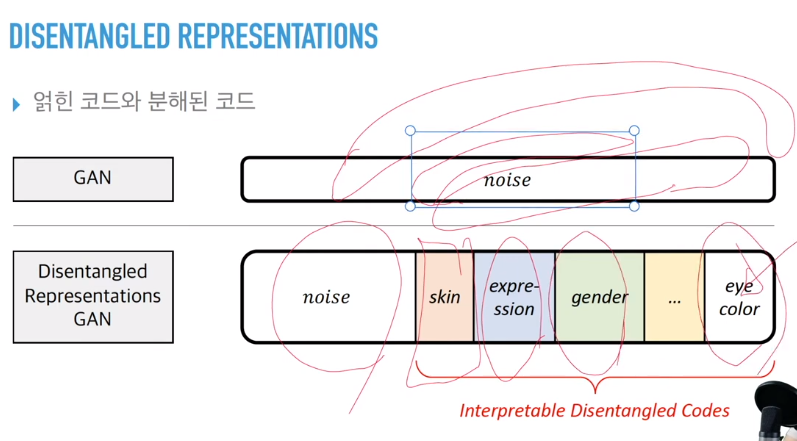
쉽게 그림을 그리면 위와 같은데
G(z) where z = (z, c) (c=c1,c2,c3,..)
로 바뀐 것이다.(잠재 코드들 c1,2,3..L은 독립적이라 가정)
알아야 할 점 - 정보 이론
MUTUAL INFORMATION(MI) : 상호 정보량엔트로피 H에 대하여 I(H;Y) = H(X) - H(X|Y)
Y가 관측됐을 때 X로부터 사라지는 불확실성(엔트로피)의 양
InfoGAN에서 상호 정보량이 최대화되도록 한다.
I(c;G(z,c)) = H(c) - H(c|G(z,c))
즉, H(c|G(z,c))가 작은 값을 갖도록 한다. = 생성된 코드에 대해 잠재코드 c의 불확실성이 낮아야 한다.
즉, 생성된 출력 G(~) 관측에 빠른 잠재 코드(c)의 불확실성을 줄인다. : 원하는 바, 생각하는 바를 잘 만들어낸다.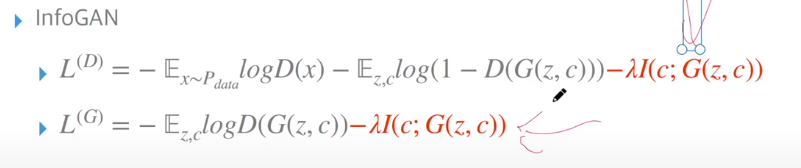
하지만 이 상호정보량 계산에서 사후분포P(c|x)의 계산이 어렵다. p(x)가 구하기 어렵기 때문
따라서 P(c|x) 대신 Q(c|x)를 사용하여 근사시키자!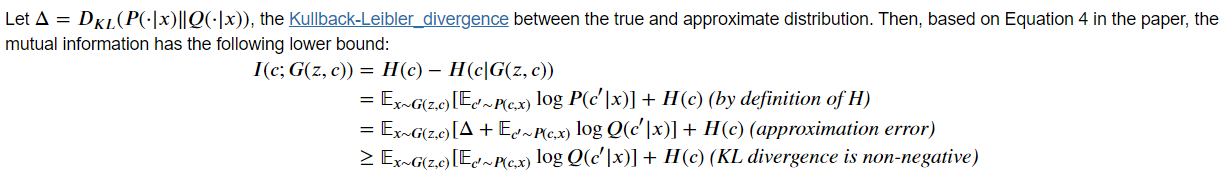
Q는 하한으로 Q(c|x;Θ)이다. 즉 보조 신경망을 통해 p를 근사시킨다.
(보조 신경망을 마지막 계층에 추가하는데 계산량은 미미하고 훈련 시간 등에 영향을 미치지 않는다고 한다. 또한 매우 빨리 수렴한다.)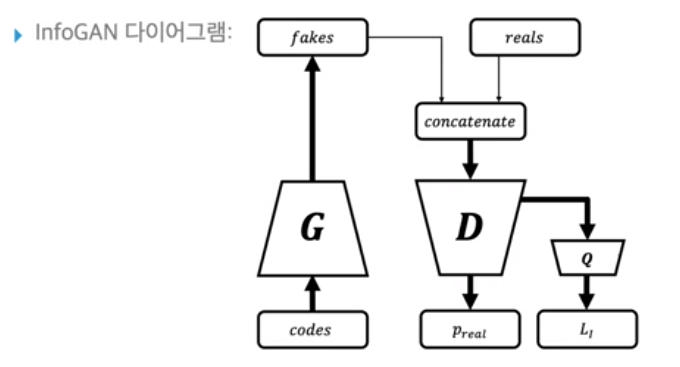
이렇게 InfoGAN은 비지도적이고 해석가능한 학습을 수행한다. 또한 GAN에서 아주 작은 정도의 추가 연산만을 요구하기에 효율적이다.(VAE에서도 사용 가능)
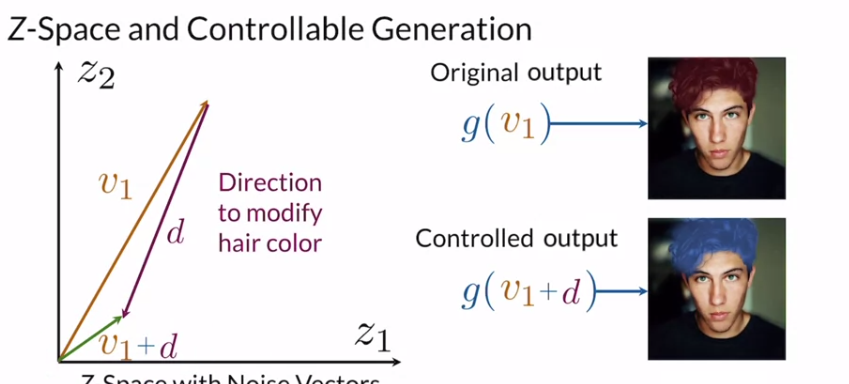
Controllable Generation은 생성기에 전달된 z 벡터를 수정하여 훈련 후에 수행되는 반면, Conditional Generation은 훈련 중에 수행되며 레이블이 지정된 데이터 세트가 필요하다!
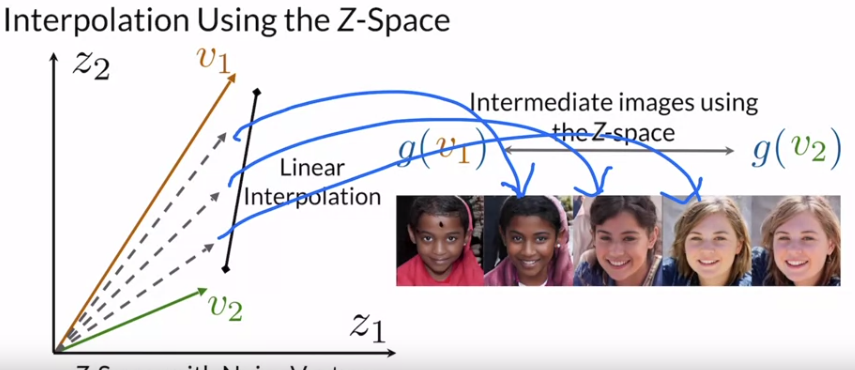
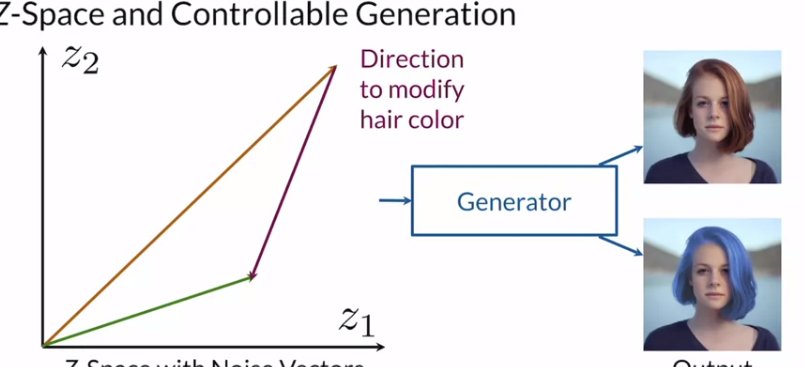
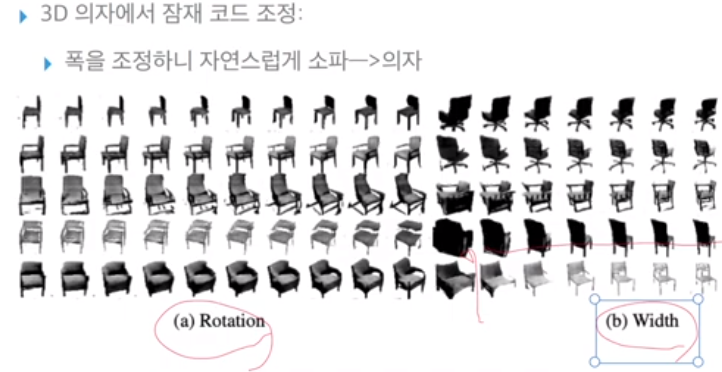
이와 같이 space내의 벡터들을 잘 조정해서 새로운 벡터를 만들어 원하는 결과를 얻을 수 있게 된다.
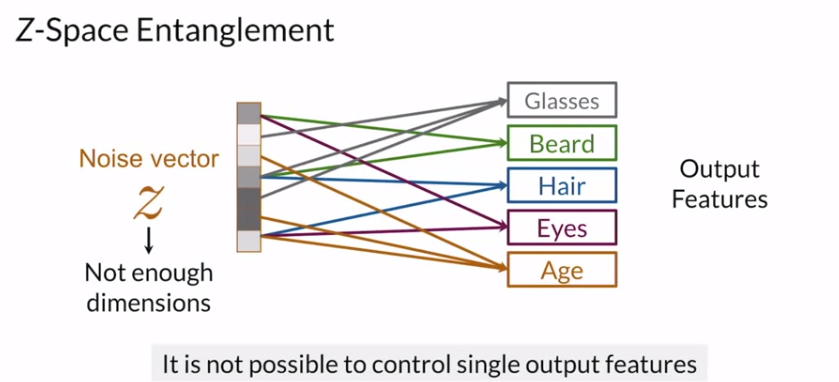
당연스럽게도 z vector의 dim이 굉장히 크지 않기에 각각의 특징 하나씩을 갖고 있지 않다. 즉, 굉장히 많은 feature에 대해 얽혀있다. 이를 잘 조절해서 특정 원하는 작업을 수행할 수 있지 않을까? 하는 것이 위에서 알아본 InfoGAN이 된다.
Controllable_Generation A to Z code making
: https://github.com/KiHwanLee123/Coursera---GAN/blob/main/C1W4B_Controllable_Generation.ipynb