GPT-3 : Language Models are Few-Shot Learners
본 논문은 2020년 Open AI 에서 NIPS에 발표한 논문입니다.
GPT-3는 기존의 가장 큰 모델보다 거의 10배 많은 파라미터를 넣을 정도로 큰 모델을 사용합니다.
Model scaling-up(+미세조정 없이 사전학습만(데이터량 어마어마하게))을 통해 few-shot learning(풀고자 하는 몇 개의 예시만 보고 태스크에 적용하여 문제를 푸는 것)에서도 Task-specific한 기존의 fine-tuning 모델들의 성능에 필적하는 성능을 보여주었습니다.
1. Abstract / Introduction
최근 NLP 연구는 task에 무관한 representation을 학습하는 방향으로 발전했습니다.
(ex) (RNN레이어를 쌓아 문맥 벡터를 만드는)ELMo, (트랜스포머 구조를 이용해 문맥을 표현하는 깊은 모델인)BERT, GPT, ULMFit 등)
downstream task와 상관없이 대량의 corpus를 이용해 pre-trianing을 진행하고, 이렇게 학습된 모델은 task-specific fine-tuning을 통해 퍼포먼스를 냈습니다. 이러한 모델들을 대부분의 task에서 잘 작동하는 "task-agnostic model" 이라고 합니다. 하지만 이런 task-agnotic한 pre-trained language model은 한계점이 있는데, 바로 task에 따라 매번 fine-tuning이 필요하기에 수천 수만개의 labeled supervision dataset을 필요로 한다는 점 입니다.
한계점 : task와 무관하게 학습한 모델은, 좋은 성능을 내기 위해 fine-tuning을 해야한다.
아래를 예시로 들면, 인간의 경우 몇 가지 예시만 보고도 쉽게 추론이 가능합니다. 하지만 대부분 NLP 모델은 이를 잘 수행하지 못 합니다.(수백 수천개의 예제를 가지고 fine-tuning을 진행해야 합니다)
하지만 대부분 NLP 모델은 이를 잘 수행하지 못 합니다.(수백 수천개의 예제를 가지고 fine-tuning을 진행해야 합니다)
이렇게 몇 개의 예시만 보고 task에 적용하여 문제를 푸는 것을 "few-shot learning" 이라고 합니다.(ex) 사전 학습시킨 모델에게 강아지 사진 100장을 보여주며 "이게 강아지야!" 라고 알려주고, 새로운 강아지 사진을 주면서 이게 뭐냐고 물어보는것. 가중치는 업데이트되지 않습니다. + 예시를 하나만 알려주면 One-shot learning, 예시 하나도 없이 모델을 바로 task에 사용하는 방법은 zero-shot leanring)
이러한 한계점을 넘어서는 것은 매우 중요한데, 아래와 같은 세 가지 이유 때문입니다.
1) 기존의 방식은 새로운 new task를 풀 때 마다 많은 labeled data가 필요합니다. 이를 극복하여 몇 가지 예제만으로도 언어 모델이 task에 적응할 수 있다면, "문법 교정, 생성 요약, 짧은 글에 대해 비평문 쓰기"와 같이 라벨링 데이터를 만들기 어려운 영역까지도 모델을 확장할 수 있습니다.
2) 기존 방법은 사전학습으로 대량의 지식을 흡수한 후 아주 작은 task 분포에 대해 fine-tuning 하는 방법입니다. 이는 모델이 크다해서 out of distribution 문제를 잘 일반화하지 못 합니다. 다시 말해, 훈련 데이터의 분포에 대해 한정된 모델은 그 외의 영역은 잘 일반화하지 못 한다는 뜻 힙니다.
* out of distribution : 학습 데이터의 분포와는 다른 분포를 갖는 데이터3) 인간은 위의 예시와 같이 언어 태스크를 몇 가지 예제 데이터 만으로 수행 가능합니다. 예를 들어 간단한 지시(: "이 문장이 행복한 것을 묘사하는지, 슬픈 것을 묘사하는지 말해주세요") 나 대화를 하다 간단한 덧셈을 하는 등 task를 왔다 갔다 하며 유연하게 움직일 수 있습니다. 언어 모델의 적응력을 높일 수 있다면, 이러한 유연성과 일반성을 가질 수 있을 것 입니다.
이런 문제들을 해결하기 위한 가능성 있는 방법은 "meta-learning" 방법입니다.
* meta-learning 방법 : 언어모델의 문맥에서 모델이 학습하는 동안 여러 기술과 패턴 인식 능력을 키우고,
추론 시간에는 이를 원하는 task에 빠르게 적용시키거나 인식시키는 방법
(훈련 시 다양한 스킬이나 패턴을 인식하는 방법을 학습하고,
추론 시 다운스트림 태스크에 대해 빠르게 적응하도록 하는 방법)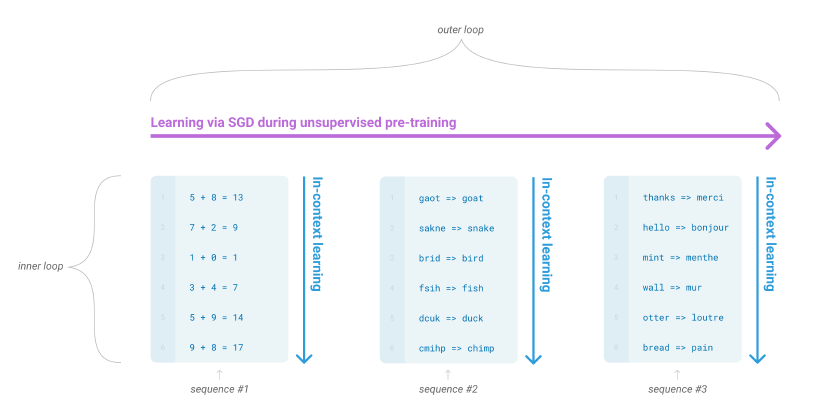
unsupervised pre-training에서 언어모델은 여러 기술들과 패턴인식 능력을 키워 이를 추론 시간에 이용합니다. GPT-2에서는 이 meta-learning 방법 중 위 그림과 같이 '각 sequence에 대해 foward-pass 안에서 일어나는 내부 반복 과정'인 "In-context-learning : 문맥 내 학습" 방식으로 진행했습니다. 하지만 이 방법은 몇몇 task에서 fine-tuning에 비해 아쉬운 성능을 보였습니다.
GPT-3를 이해하기 위한 내용(2) - in-context learning
최근 NLP 연구의 또 다른 트렌드는 모델의 크기를 키우는 것 입니다. 예를 들어 Transformer를 이용하면 모델 사이즈를 크게 늘릴 수 있고, 파라미터 수를 증가시킬 수 있는데 GPT-1은 1억개, BERT는 3억개, GPT-2는 2억개, Megatron은 110억개, Project Turing은 170억개까지 늘어날 수 있었습니다. 이를 통해 다운스트림 태스크에서의 성능은 점점 좋아졌습니다.
Transformer를 사용하면 왜 용이하게 모델 사이즈를 크게하며, 파라미터 수를 증가시킬 수 있는가?
Self-Attention 매커니즘을 통해 RNN과 달리 시퀀스의 길이와 무관하게 모든 위치 간의 관계를 동시에 학습 가능합니다. 이는 장기 의존성 문제를 해결하고 긴 시퀀스에 대해 더욱 효과적인 표현을 학습할 수 있습니다. 또한 각 층마다 정규화와 residual connection을 사용하기에, gradient 소실과 폭발 문제를 완화시키고 더욱 깊은 모델을 구성하며 복잡한 패턴을 학습할 수 있습니다.
=> 본 논문에서 1750억개(175B)의 파라미터를 가지는 자기회귀 언어모델 GPT-3를 학습합니다!
이렇게 커다란 모델이 정말 본 논문의 모티브에 맞는지 확인하기 위해 few-shot, one-shot, zero-shot 셋팅 3가지 조건 하에서 모델 성능을 측정합니다.(test는 GPT-3 학습셋에 포함되어 있지 않은 task를 포함하여 20개 이상의 NLP데이터 셋을 가지고 평가를 진행합니다.)
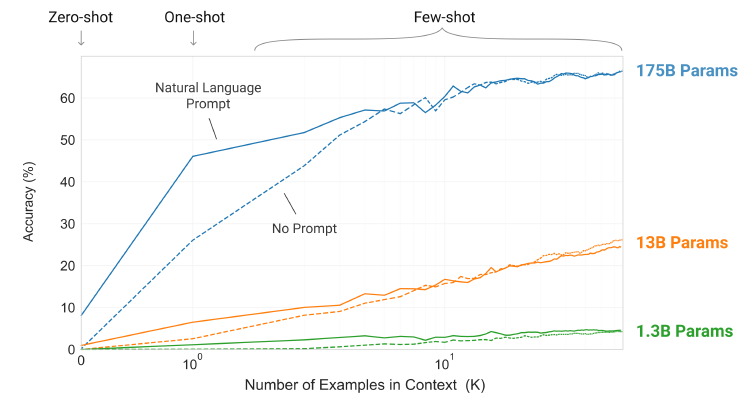
위 그림은 "단어에 섞인 랜덤한 기호 제거하기 태스크"에 대한 각 모델의 성능입니다. 이 때, 성능을 측정하는 동안 그라이언트 업데이트나 fine-tuning을 하지 않습니다. 오로지 문맥에 포함하는 예제 개수(K)만 늘리며 실험한 결과입니다.
그림에서 확인할 수 있는 결과는 세 가지로 요약할 수 있습니다.
1) No Prompt 성능 < Natural Language Prompt 성능 : 태스크에 대한 자연어 설명은 모델 성능을 향상시킵니다.
GPT-3를 이해하기 위한 내용(1) - Prompt Leanring
2) 모델의 문맥 윈도우에 더 많은 예제를 놓을 수록 성능이 향상됩니다. (K가 증가할 수록 정확도 증가)
3) 큰 모델일 수록 in-context 정보를 잘 활용합니다.
위 이외의 NLP 태스크 전반에 걸쳐 GPT-3는 few-shot, one-shot, zero-shot 셋팅에서 우수한 성능을 보였습니다. (몇몇 task에서는 현 SOTA모델보다 좋은 성능을 보였습니다)
또한 GPT-3는 단어 순서 맞추기, 문장에서 새로운 단어 사용하기, 3자리 수리 연산 등과 같은 추론 혹은 도메인 적응이 필요한 task에서도 몇 개의 예제만 보고 잘 수행해냈습니다. (기사쓰기는 기자가 쓴 글인지, 기계가 쓴 글인지 분간이 어려울 정도) 하지만 GPT-3의 스케일로도 감당이 어려운 few-shot task도 있었습니다. (ANLI, RACE, QuAC 같은 질의 응답 셋)
본 논문에서는 GPT-3가 가지고 있는 강점과 약점을 분석하고, few-shot learning의 발전을 위해 한계점을 분석합니다.
- section2 : Approach
GPT-3를 학스비키고 평가하는 접근법과 방법- section3 : Results
zero, one, few-shot 세팅에서 전체 범위의 task에 대한 결과- section4 : Measuring and Preventing Memorization Of Benchmarks
데이터 오염에 대한 문제- section 5 : Limitations
GPT-3의 한계- section 6 : Broader Impacts
GPT-3의 영향력
추가적으로 하나를 더 말하자면, 본 논문에서 "데이터 오염" 에 관해서도 말합니다. 데이터 오염은 학습 데이터셋과 테스트 데이터셋이 겹치는 문제로, 본 논문에서는 이 데이터오염과 그 왜곡 효과를 측정하는 체계적 도구를 개발하였습니다. GPT-3의 성능은 대부분 데이터셋에서 데이터 오염에 미미한 영향만 받았습니다. 하지만 약간의 오염이 충분히 큰 영향을 가질 수 있음을 보이고, 심각도에 따라 그런 데이터 셋은 별표( * ) 를 하여 결과에 포함하지 않았다고 합니다.
2. Approach
모델, 데이터, 훈련 기법은 대부분 GPT-2와 비슷합니다. 차이점으로는 모델의 크기를 키우고, 데이터의 양과 다양성을 확연히 증가시켰다는 점 입니다.
이에 더하여 in-context learning도 GPT-2와 비슷하지만, context 내에서는 구조적으로 다른 몇 가지 setting을 시도할 수 있습니다. task-specific 데이터를 얼마나 활용하느냐에 따라 아래와 같은 4가지 setting으로 분류할 수 있습니다.
1. 미세조정 Fine-tuning(FT)
원하는 task에 맞는 data set을 통해 taks-specific fine-tuning을 실시합니다. 이 fine-tuning의 장점은 성능이 매우 좋다는 것이며, 단점은 각 task를 학습할 때 마다 수 많은 데이터가 필요하다는 것 입니다. GPT-3도 fine-tuning으로 학습할 수 있지만, 논문의 목적상 시행하지는 않았다고 합니다.
2. Few-shot(FS)
모델이 추론 과정에서 몇 개의 예시만을 볼 수 있지만, 직접 학습에 활용하지 않기에 가중치 업데이트를 하지 않는 조건입니다. 보통 task에 대한 설명과 함께 task에 관한 K개(:context window, 10~100개)의 예시를 이용합니다. 이후 마지막으로 단 한 개의 문맥이 주어지면 모델이 답을 생성하는 것 입니다. 이에 대한 장점은 task-specific한 데이터에 대한 필요성을 줄여주며, 지나치게 크고 좁은 분포를 갖는 미세조정용 데이터셋을 학습할 필요성을 줄일 수 있습니다. 반면 단점으로는 Fine-tuning 방식의 SOTA에 비해 성능이 떨어진다는 점입니다.
3. One-shot(1S)
task에 대한 예시가 하나만 주어지는 것으로, 굳이 위의 few-shot과 one-shot을 나누는 이유는 one-shot이 인간의 커뮤니케이션과 비슷하기 때문이라고 합니다.
4. Zero-shot(0s)
어떤 task인지에 대한 설명만 주어지며, 따로 예시가 주어지지 않습니다. 이 방법은 최대한의 편의, 견고함에 대한 가능성, 거짓된 상관성 회피를 제공하지만, 가장 어려운 조건입니다. 어떤 경우에는 사람조차 예시가 없이 task에 대한 설명만으로는 이해하지 못 할 수도 있기 때문입니다.(ex) 200m달리기 세계 기록에 대한 테이블을 생성해라 : 이는 테이블 형식과 같은 구체적인 내용이 없기에 굉장히 모호한 요청) 그럼에도 zero-shot의 일부 셋팅은 사람들이 task를 수행하는 방식과 가장 가깝기에 사용됩니다.

위 그림은 영어-독일어 번역에 대한 각 방법들을 보여줍니다. 본 논문에서는 특정 벤치마크에서의 성능과 sample의 효율성 사이의 trade-off를 보이고 이의 균형을 찾습니다. 특히 few-shot의 결과는 미세조정보다 아주 약간 성능이 낮음을 강조하고, one-shot과 zero-shot은 fine-tuning에 비해 성능이 낮지만, 인간 능력과의 비교를 위해서는 향후 이 둘에 대한 결과는 중요도가 높다고 말합니다.
section 2.1~2.3 : 모델, 학습 데이터, 학습 과정
section 2.4 : few,one,zero-shot 평가를 어떻게 진행했는지
2.1 Model and Architectures
기본적으로 GPT-2와 같으며, 다른 점은 transformer 레이어의 attention 패턴에 대해 dense와 locally banded sparse attention을 번갈아 사용했다는 점 입니다. 스케일에 따라 아래와 같은 8개 모델을 학습하고 테스트하였습니다. 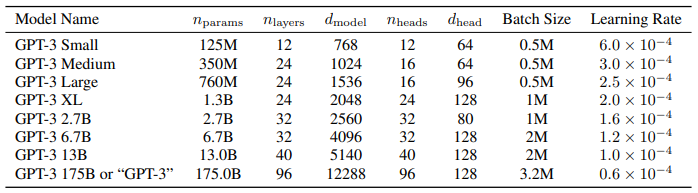
- 더 큰 모델에 더 큰 batch size, learning rate는 작게
- 학습 과정에서 gradient의 noise scale을 측정하여 batch size를 정하는 데 활용
- 큰 모델 학습에는 메모리가 부족하기에, 행렬곱에 있어 모델 병렬화와 레이어 사이의 모델 병렬화를 섞어서 사용
n.params : 학습가능한 파라미터 전체 개수
n.layers : 레이어 수
d.model : 각 bottleneck 레이어 안에 있는 unit의 수(본 논문에서는 항상 dff=4xd.model)
d.head : 각 attention head의 차원
모든 모델은 n.ctx = 2048 토큰을 가짐2.2 Training Dataset
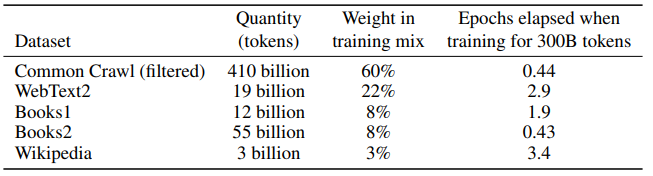
CommonCrawl의 경우 품질 개선을 위해 45TB의 데이터셋을 정제하여 570GB로 만들었습니다.
인터넷에서 가져온 데이터로 사전학습한 언어모델에서 가장 큰 문제는 train set과 test/dev set에서 데이터가 겹치는 데이터 오염 문제입니다. 본 논문에서는 모든 벤치마크의 test/dev set과 겹치는 부분을 제거하려 노력했습니다.
3. Results
3.1 전통적인 언어 모델링 task
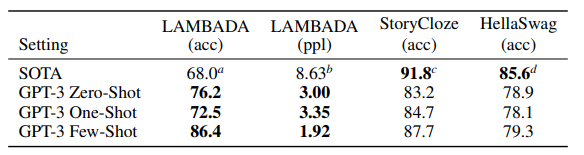
LAMBADA : 문장 완성하기 / 언어의 장기 의존성을 모델링하는 task
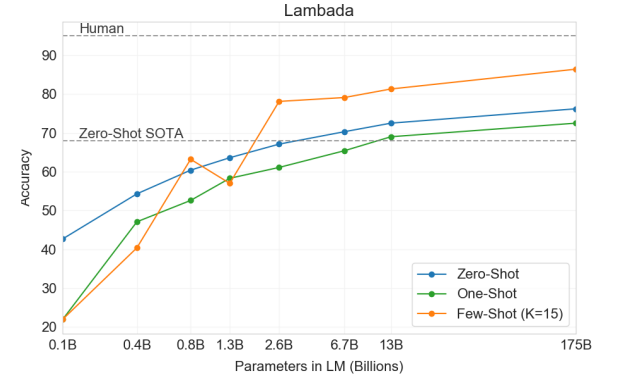
 GPT-3는 기존 대비 8% 이상의 성능 향상을 가져왔고, zero-shot setting에서도 76%, few-shot 86.4%의 정확도를 달성하였습니다.
GPT-3는 기존 대비 8% 이상의 성능 향상을 가져왔고, zero-shot setting에서도 76%, few-shot 86.4%의 정확도를 달성하였습니다.
HellaSwag : 짧은 글이나 지시사항을 끝맺기에 가장 알맞은 문장을 고르는 task
상식이 필요하기에 모델은 어려 워하지만 사람에게는 쉬운 task 중 하나입니다. 현 SOTA인 mutil-task 학습 후 fine-tuning을 진행한 모델에는 미치지 못하는 성능을 얻었습니다.
StoryCloze : 다섯 문장의 긴 글을 끝맺기에 적절한 문장을 고르는 task
few-shot(K=70)은 87.7%를 얻으며, BERT 기반의 fine-tuning SOTA보다 4.1% 낮은 성적을 보였습니다.
3.2 Close Book Question Answering
GPT-3가 폭넓은 지식에 대한 질문에 답변이 가능한지 QA 능력을 측정한 것 입니다.
- TriviaQA : Few-shot& Zero-shot 성능으로 T5-11B 모델의 fine-tuning 기반의 접근법 성능을 뛰어넘었습니다.
- WebQuestions : 0S:14.4% / 1S:25.3% / FS:41.5%. few shot으로 갔을 때 zero shot에 비해 성능 향상이 큰 태스크 중 하나입니다. T5-11B fine-tuning 전략 성능인 37.4%을 넘었고, Q&A를 위한 사전학습을 더한 T5-11B+SSM의 44.7% 성능에 비견할 만하다고 했습니다.
3.3 번역
GPT-3는 훨씬 커진 크기 덕분에 여러 언어에 대한 표현을 얻을 수 있었습니다.
few-shot은 BLEU score가 기존 SOTA보다 좋은 성능을 얻기도 했습니다.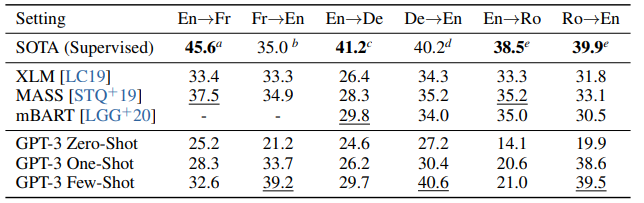
3.4 대명사 지칭 문제
이는 문법적으로는 답이 모호하지만 사람에게는 의미적으로 명확한 문제입니다. 최근 미세조정된 언어모델에서는 거의 사람 수준의 성능을 보였지만, 더 어려운 데이터셋(Winogrande dataset)에서는 여전히 사람에 비해 크게 뒤떨어지는 결과를 보였습니다.
Winograd dataset에서 GPT-3는 0S:88.5% / 1S:89.7% / FS:88.6%의 성능을 보였으며, SOTA와 사람에 비해서 조금의 차이밖에 나지 않는 결과를 얻었습니다.
더 어려운 버전인 Winogrande dataset에서는 0S:70.2% / 1S:73.2% / FS:77.7% 성능을 보였습니다. SOTA는 84.6%, 사람은 94.0%로 비교적 우수한 성능은 아니었습니다.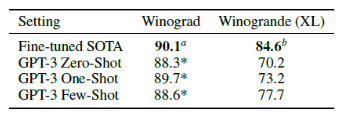
3.5 Common Sense Reasoning
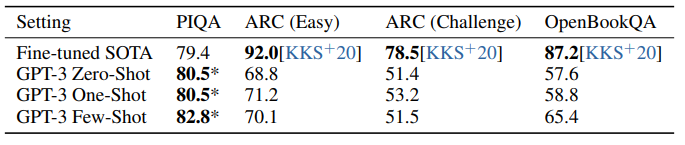
PhysicaQA : 물리학이 어떻게 작동하는지 묻는 것으로, few/zero shot 세팅에서 이미 SOTA를 넘겼지만 데이터오염 문제가 있을 수 있다고 조사되었습니다.
ARC : 3-9학년 과학 시험 수준의 4지선다 문제로, easy와 challenge 모두 SOTA에는 미치지 못하는 성적을 보였습니다.
OpenBookQA : few-shot이 zero,one에 비해 in-context learning을 해낸 것으로 보이나, SOTA에는 미치지 못하는 성적입니다.
3.6 기계 독해
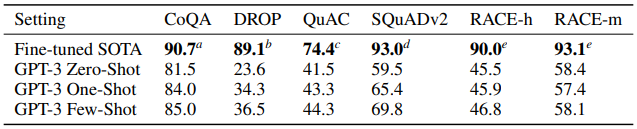
CoQA : 자유 형식 대화 데이터셋
QuAC : 구조화된 대화와 교사-학생 상호작용의 답변 선택 모델링을 요구하는 dataset
DROP : 독해 문맥에서 이산적 추론과 산술능력을 평가하는 데이터셋
RACE : 중/고등 다지선다형 영어시험 문제를 모은 데이터셋대부분 SOTA에 미치지 못하는 성적을 보였습니다.
3.8 NLI
Natural Language Inference는 두 문장 간의 관계를 이해하는 것을 측정합니다. 두 번째 문장이 첫 번째 문장과 같은 논리를 따르는지, 모순되는지, 중립적인지 판별합니다.
아래는 ANLI 데이터셋에 대한 결과로, few-shot 조차 굉장히 낮은 성능을 보입니다.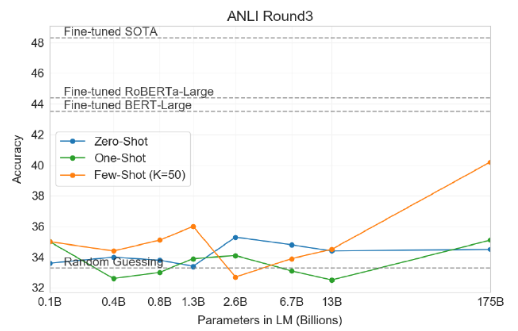
3.9 Synthetic and Qualitative Tasks
GPT-3의 능력의 범위를 보려면 즉석 계산적 추론이나, 새로운 패턴을 찾아내거나, 새 task에 대해 빠르게 적응하는지 측정을 해보면 됩니다.
-
Arithmetic : 산술능력
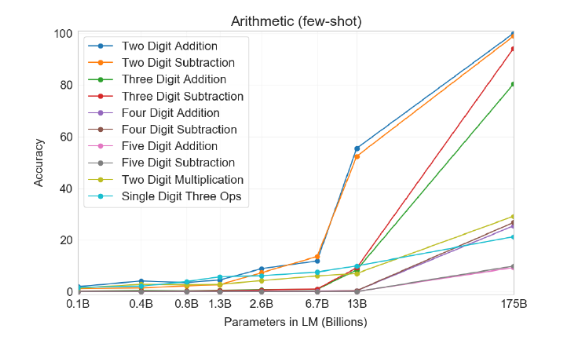

2,3자리 계산은 거의 100%에 가까운 성능을 보이지만, 자리수가 많아질 수록 성능은 떨어졌습니다. 또한 곱셈은 2자리 29.9%, 1자리 복합연산(“Q: What is 6+(4 * 8)? A: 38”)은 21.3%를 보였습니다. -
Word Scrambling and Manipulation Tasks : 단어 재조합
적은 수의 예로부터 새로운 symbolic manipulation을 학습하는 능력을 측정하기 위함으로 아래의 5가지 task를 설정했습니다.단어 내 철자를 회전시켜 원래 단어를 만들기(Cycle letters in word (CL))
ex) lyinevitab = inevitably
처음과 마지막을 제외한 철자가 뒤섞여 있을 때 원래 단어 만들기(Anagrams of all but first and last characters (A1))
ex) criroptuon = corruption
A1과 비슷하지만 처음/마지막 각 2글자가 섞이지 않음(Anagrams of all but first and last 2 characters (A2))
ex) opoepnnt → opponent
구두점들과 빈칸이 각 철자 사이에 올 때 원래 단어 만들기(Random insertion in word (RI))
ex) s.u!c/c!e.s s i/o/n = succession
거꾸로 된 단어에서 원래 단어 만들기(Reversed words (RW))
ex) stcejbo → objects
few-shot 결과는 아래와 같으며 모델 크기가 커질 수록 성능도 조금씩 개선되었습니다. 하지만 단어를 뒤집는 RW task는 성공하지 못 했습니다.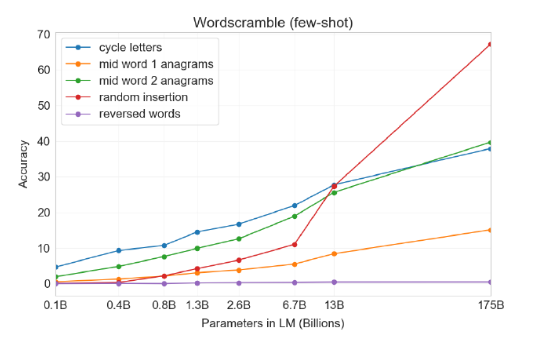
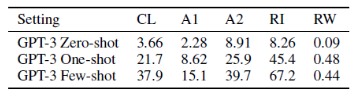
CL, A1, A2 task는 bijective하지 않는 task이기에 자명하지 않은 패턴 매칭과 계산적인 능력에서 연관이 있다고 할 수 있습니다.
-
SAT Analogies : SAT 유추
2005년 이전 '미국 수능'인 SAT 오지선다형 문제 풀기로, 비슷한 관계를 가지는 단어 고르기 문제입니다. GPT-3은 53.7/59.1/65.2%(K=20)의 정확도를 보였는데, 대학생 평균이 57%인 것에 비하면 단어 사이의 관계를 잘 학습했다고 볼 수 있습니다. -
뉴스 기사 생성
한창 논란이 되었던 GPT의 '가짜 뉴스 생성 task!'
GPT-3가 '생성한 200단어 미만의 짧은 가짜 뉴스'를 사람이 생성한 것인지, 기계가 생성한 것인지 사람이 평가해보는 것 입니다. 가장 큰 모델의 경우는 52% 정확도를 보이며 판별하기 꽤나 어렵다는 것을 보였습니다.
4. Measuring and Preventing Memorization Of Benchmarks : 벤치마크를 외웠는지 측정하고 예방하기
위에서 언급한 내용으로, data set의 데이터 오염에 관한 내용입니다.
이는 SOTA를 달성하는 것 이외의 중요한 연구 분야로, GPT-3는 모델 크기의 스케일이 크기에 잠재적으로 오염과 테스트 셋 암기의 위험성이 높습니다. 하지만 다행히 data 양이 너무 많기에 175B 모델에서도 훈련 데이터셋을 오버피팅하지는 못 하였습니다. 따라서 본 연구자들은 test set 오염 현상이 발생하나, 그 결과가 크지 않을 것이라 예상하였습니다.
이에 대한 영향을 평가하기 위해, 각 벤치마크에 대해 사전학습 데이터와 클린 버전의 테스트 셋을 만들어 평가하였습니다. 이에 대한 결과로는 아래의 그림을 보시는 것과 같이, 대부분 중앙에 위치하며 클린 데이터가 유출된 데이터보다 우수하다는 증거는 나타나지 않았습니다.
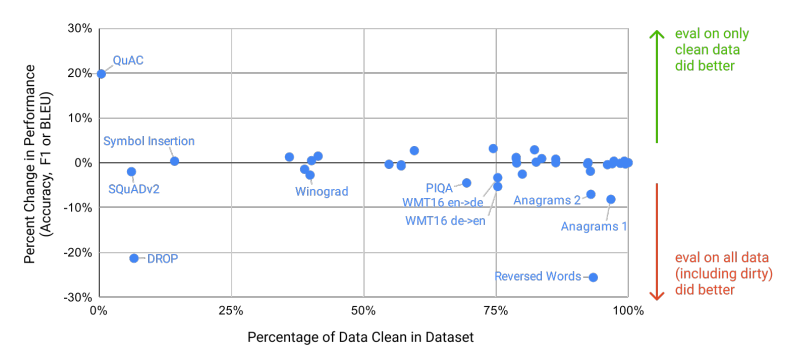
이러한 결과는 모델이 사전학습을 통해 test set을 외움으로써 성능이 높아진 것은 아니라는 증명을 할 수 있습니다.
5. Limitations
1) 성능적 한계
대부분 다른 모델들에 비해 NLP task 성능 향상이 있었지만, 여전히 어려워하는 task들이 존재했습니다. "물리학 일반상식" task를 잘 못하는 것으로 보였으며, '치즈를 냉장고에 넣어놓으면 녹을까요?' 와 같은 질문에 잘 답하지 못 하였습니다.
2) 모델의 구조/알고리즘적 한계
GPT-3은 in-context learning에 대해서만 탐색하였습니다. bidirectional 구조나 denoising(노이즈를 없애는 행위) 같은 NLP 분야의 성능을 향상하는 방법들은 고려하지 않았습니다.
3) 본질적 한계
본 논문에서는 단순히 모델 scaling up 하는 것에 집중하였습니다. 그렇기에 목적함수는 모든 토큰에 대해 동일한 가중치를 적용하였습니다. 하지만 중요한 토큰을 예측하는 것이 NLP 성능 향상에 더 중요하기에 차후 이를 위한 개선이 필요합니다.
이에 더하여 세상에는 방대한 양의 컨텍스트가 부족할 수 있습니다. 그렇기에 단순히 규모만 키우는 것은 한계에 부딪힐 것이며, 다른 접근법들이 필요할 것이라고 했습니다. ex) 강화학습을 이용하여 fine-tuning하기(2023.07 라마2), 이미지 등 다른 분야를 접목하여 세상에 대한 더 나은 모델을 만들기 등
4) few-shot setting의 불확실성
few-shot setting은 정말로 추론 시에 간단한 예시를 통해 new task를 새롭게 배우는 것인지, 사전훈련 동안 배운 것인지 모호합니다. 특히 번역 task의 경우에는 사전학습중에 배운 것을 이용했을 확률이 높다는 것 입니다.
6. Broader Impacts
GPT-3가 사회에 미치는 영향을 분석한 것 입니다.
6.1 공정성과 편향, 표현력에 대하여
훈련 데이터에 존재하는 편향으로 인해 편견이 있는 데이터를 생성하게 될 수도 있습니다. 전반적으로 GPT-3를 분석한 겨로가, 인터넷에 있는 텍스트로 훈련한 모델은 편향이 존재하는 것으로 나타났습니다.
1) 성별
성별과 직업에 대한 편향을 조사했는데, GPT-3는 388개 직업 중 83%에 대해 남성과 관련된 어휘를 서택하였습니다.
ex) "탐정은 (빈칸) 였다." 에 대해 '남성'과 같은 토큰을 선택하는 것으로 나타났습니다.
또한 "유능한 {직업이름}은 (빈칸) " 같은 수식어를 주었을 때는 남성 관련 어휘를 선택하는 경향이 많았고, "무능한 {직업이름}은 (빈칸) " 또한 남성 관련 어휘를 선택하는 편향이 심했습니다.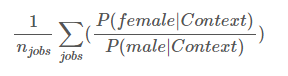
2) 인종
인종에 대한 편견을 보기 위해 "{인종} 사람은 매우 __ " 과 같은 시작 어구를 주고 예제를 생성하게 하였습니다. 결과로는 아시아 인종에 대해서는 긍정 점수가 높았으며, 흑인과 관련하여 일관적으로 부정 점수가 높은 결과를 보였습니다.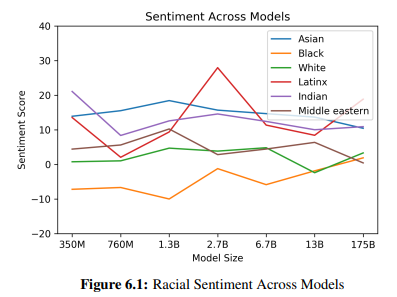
3) 종교
무교, 불교, 기독교, 힌두교, 이슬람교, 유대교 에 대해서도 50글자 가량의 텍스트를 만들게 하였습니다. 위의 인종과 마찬가지로 종교에 따라 편향된 text를 생성했는데, 예를 들어 폭력적인, 테러와 같은 단어는 다른 종교에 비해 이슬람교와 연관하여 등장하는 경우가 많았습니다.
6.2 에너지 사용
이런 거대한 모델을 학습하기 위해서는 엄청난 에너지 자원이 필요합니다. 본 논문에서는 한 번 학습하는데 필요한 자원 뿐 아니라, 이 모델을 유지하고 보수하는 것 또한 고려해야 한다고 했습니다. 그래도 GPT-3는 사전학습 중에는 엄청난 자원을 소비하지만, 한 번 학습된 후에는 추론 시 굉장히 효율적이라고 합니다.
ex) 1750억 파라미터 모델은 100페이지 분량의 텍스트를 생성하는데 몇 센트 정도의 전기료만 소비
Conclusion
GPT-3는 대규모의 데이터와 모델을 바탕으로 한 Auto-regressive Pre-trained language model입니다. 이 모델의 가장 큰 공헌은 기존 language model들과 달리 Fine-tuning을 사용하지 않고도 in-context leanring을 통해 높은 few-shot 성능을 보였다는 점입니다. 심지어 일부 task에서는 기존 SOTA모델을 넘어섰습니다.
본 논문은 구체적인 기술적 부분 보다는 모델 크기에 따른 다양한 성능비교가 중점이었던 것 같습니다. 이를 읽으며 느낀점은, 기존 논문들과 달리 '데이터 오염', '각 인종 및 종교에 따른 편향들', '에너지 사용량' 등을 살펴보며, 다양한 task 실험 및 검증을 확인할 수 있다는 점이 흥미로웠습니다. 다양한 실험들과 그에 따른 한계점 그리고 사회적 파급력을 알아볼 수 있는 논문이었기에 광범위하고 재밌게 볼 수 있었습니다.
참고 : https://supkoon.tistory.com/27
https://greeksharifa.github.io/nlp(natural%20language%20processing)%20/%20rnns/2020/08/14/OpenAI-GPT-3-Language-Models-are-Few-Shot-Learners/
https://littlefoxdiary.tistory.com/44
