Multimodal Representation Learning
Multi-modal?
멀티 모달은 아래와 같이 다양한 task에 대하여 정보를 추출하는 것을 의미합니다.
- Unimodal vs Multimodal
가볍게 둘을 비교하자면 Unimodal의 경우는 '하나의 modality만 활용하여 풀고자 하는 문제를 해결하는 모델'이며, Miltimodal은 '두 개 이상의 modality를 활용하여 풀고자 하는 문제를 해결하는 모델'이라고 할 수 있습니다.
예를 들어 아래와 같이 'Prediction of Alzheimer’s progression based on multimodal
Deep-Learning-based fusion and visual Explainability of time-series data' 논문에 나오는 모델 아키텍쳐를 가져와 보겠습니다.
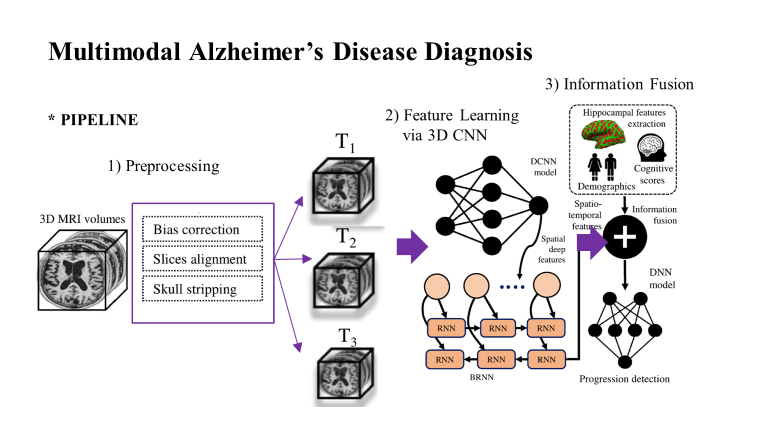
기본적으로 단순히 이미지 데이터로부터 feature를 추출 후 direct로 정보를 뽑는 것이 아닌, Information Fusion 파트를 통해 다양한 정보들과 뽑아 낸 feature와 결합하여 더욱 더 정교한 output을 낼 수 있게 만들어 냅니다.
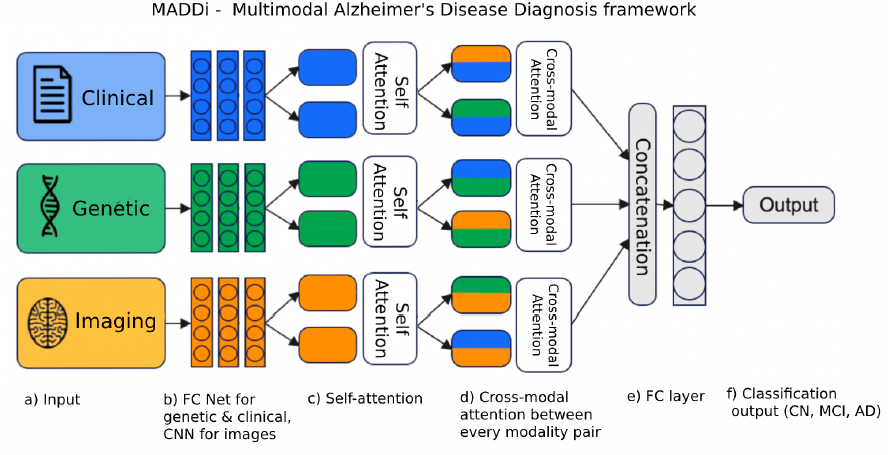
또 다른 예시로는 'Multimodal Attention-based Deep Learning for Alzheimer’s
Disease Diagnosis' 논문을 살펴보면, Clinic data, genetic data, image data 세 가지가 결합하여 classify하는 구조를 살펴볼 수 있습니다.
이와 같이 단순히 이미지 데이터 혹은 텍스트 데이터만으로는 뽑아내기 어려운 정보들을 멀티모달을 통한 결합으로 추출할 수 있게 하는 것 입니다. 아래와 같이 단순히 사진만으로는 어떠한 표정을 짓고 있는 것인지 판단하기 어렵지만, 텍스트 데이터를 통해 냉소적인 표정임을 확신할 수 있게 됩니다.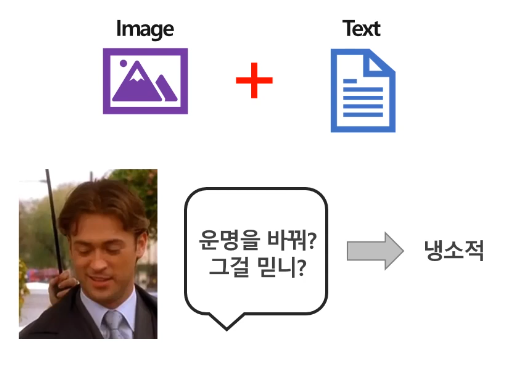
Representation Learning
이와 같이 서로 상호보완적 정보 공유를 통해 더욱 정확하고 특징점을 뽑아낼 수 있다는 것이 멀티모달의 장점입니다.
하지만 이런 멀티모달을 다룰 때는 생각해 볼 문제점이 하나 존재합니다.
- Heterogeneity gap
위의 예시들과 같이 각 modality에서 추출해 낸 feature 값은 각 space에서의 representation이 상이하다는 점 입니다.
(저희는 물론 비슷한 것들은 가까이 있기를 원합니다.)
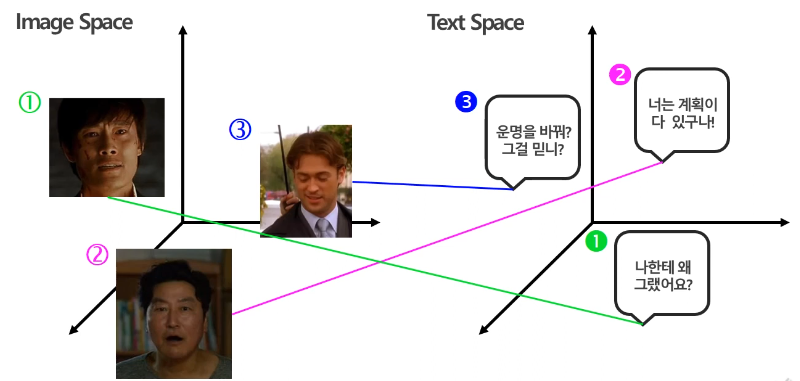
따라서 이러한 Heterogeneity gap을 줄일 수 있는 방안들에 대하여 집중적으로 살펴보겠습니다.
크게는 1) Joint Representation 2) Coordinated Representation 3) Encoder-Decoder 방법이 있습니다.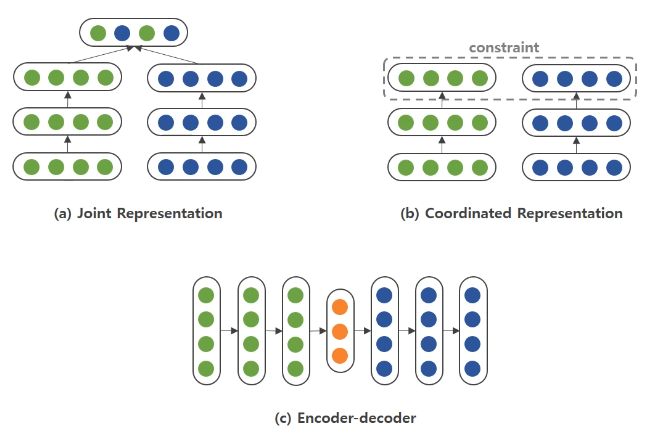
1) Joint Representation
이는 가장 간단한 방법으로 각 modality별로 특징을 학습한 후에 결합하여 common subspace에 하나의 representation으로 매핑시키는 방법입니다.
여기서 두 feature를 결합하는 방법들을 살펴보겠습니다.
우선 가장 간단한 방법은 Concatenate와 Additive Approach로 단순히 concat을 하거나 가중합을 통한 결합을 진행한 후 모델에 넣는 방법이 있습니다.
다음으로는 Multiplicative Approach입니다. 이 방법은 두 feature vector를 외적하는 방법입니다. 이 방식은 외적을 통해 모든 요소들의 상호작용을 할 수 있다는 장점이 존재합니다.
하지만 이러한 방식은 당연히 너무나 많은 메모리 소비를 야기하기에 현실적으로 적용하기 어렵다는 단점이 존재합니다.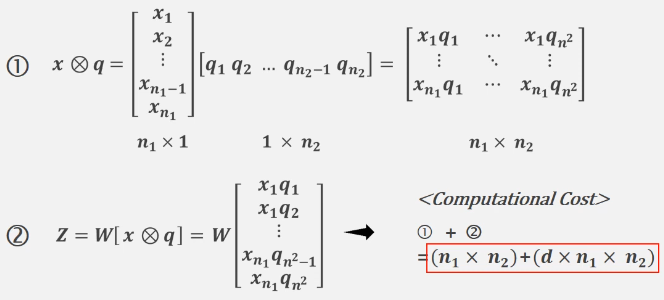
따라서 이러한 단점을 보완하기 위해 나온 Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding (이하 MCB) 논문이 나왔습니다.
MCB는 외적에 Count Sketch projection function(Ψ)을 통해 메모리 사용량과 계산 시간을 절감시킵니다. 이는 아래와 같이 "외적을 취한 후 Ψ를 씌운 것 = Ψ를 씌운 값을 convolution한 것" 임을 증명하며, convolution을 통한 단순 주파수 변환의 element-wise곱 계산식으로 변경을 통한 계산량 및 시간 감소를 보였습니다. (관련 내용은 Pham and pagh 에서 증명)
nf(FFT차원) << (n1xn2)+(dxn1xn2)

이와 같이 Joint Representation방법이 있으며, 이에 대한 장점으로는 Modality 개수와 관계없이 정보 융합이 간단하며, 단점으로는 각 Modality별로 분리된 representation을 얻을 수 있다는 한계점이 존재합니다.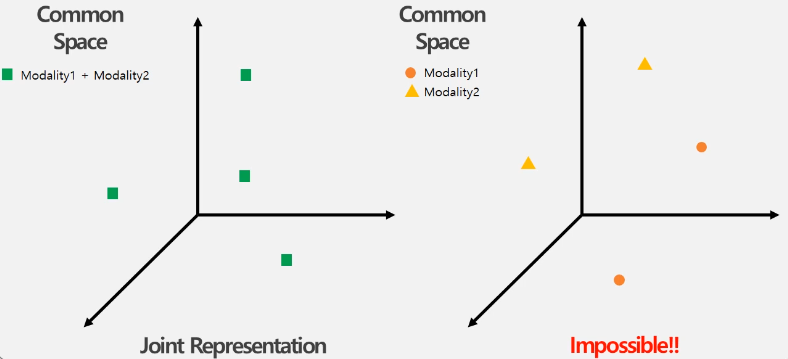
2) Coordinated Representation
다음으로는 Coordinated Representation 방법입니다.
이 방법은 제약을 통해 다른 modality임에도 같은 의미를 가지면, 가깝게 매핑하는 common space를 학습하는 방법입니다.
자세히 들여다 보면, 각 modality에서 나온 feature 값을 이전과 다르게 Cross-modal ranking으로 rankLoss를 통해 학습을 진행합니다. 이를 통해 쌍을 이루는 정보는 서로 similarity가 크도록, 쌍이 아닌 정보는 서로 similarity가 작도록 학습이 진행됩니다.
아래를 살펴보면 S(v,t)는 쌍을 이루는 사진과 텍스트 feature값의 similarity이며, -가 들어간 값은 쌍을 이루지 않는 정보들의 feature값의 similarity입니다.
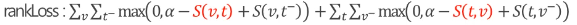
또 다른 방법으로는 Euclid distance를 통해 각 modality에서 나온 representation vector간의 거리를 최소화하는 loss를 통해 학습을 진행하는 방식 또한 존재합니다.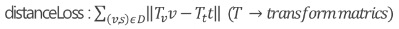
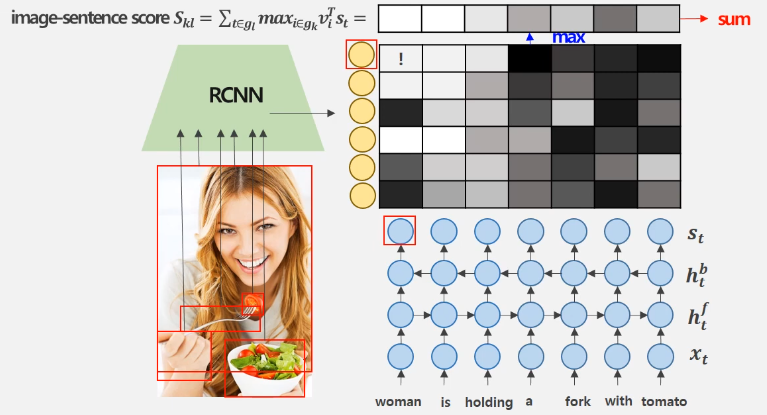
이러한 방법을 사용하여 이미지의 특정 부분과 문장의 단어들 사이의 관계를 고려한 'Deep Visual-Semantic Alignments for Generating Image Descriptions' 논문을 살펴보겠습니다.

본 논문의 핵심은 bounding box를 뽑아낸 image에 대한 representation 값을 text embedding vector와의 similarity를 통해 score를 구하게 되는 것 입니다.
이와 같이 특정 box와 특정 token과의 유사성을 따지며 이 score값으로 loss function을 구성합니다.
Loss Function
Σ [ Σ max (0, Skl - Skk + 1) + Σ max(0, Slk - Skk + 1) ]: 쌍을 이루는 image와 문장간의 image-sentence score가 크도록 설정함으로 쌍을 이루는 image와 문장 간 similarity가 큰 common space로 학습!
3) Encoder-Decoder
마지막으로 인코더 디코더 방법은 대표적으로 image captioning을 말할 수 있습니다. image를 받아 encoder를 통해 latent space로 보낸 후 이를 decoder를 통해 text를 뽑아 내는 것 입니다. 물론 반대 또한 가능합니다.
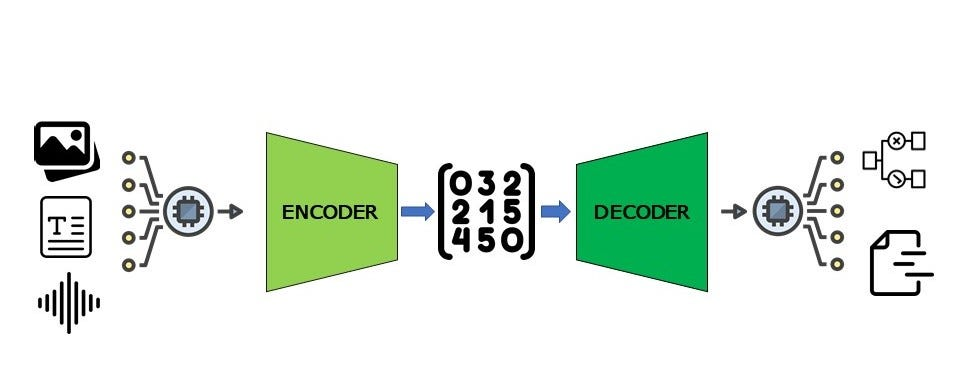
이에 대한 장점으로는 새로운 샘플들을 생성할 수 있다는 장점이 있습니다. 하지만 학습이 진행된 후 반대로는 (ex) image to text라면 text to image) 불가능하다는 단점이 존재합니다.
여기까지 Multimodal의 전반적인 내용과 멀티모달의 좋은 성능 및 효율성을 증대시키기 위한 Representation Learning 에 대하여 알아보았습니다.
참고자료 : prediction of Alzheimer’s progression based on multimodal
Deep-Learning-based fusion and visual Explainability of time-series data
Multimodal Attention-based Deep Learning for Alzheimer’s
Disease Diagnosis
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
Deep Visual-Semantic Alignments for Generating Image Descriptions
https://www.youtube.com/watch?v=PcU2oiPFDTE&t=1419s
