논문 리뷰 - Physics-Informed Attention Temporal Convolutional Network for EEG-Based Motor Imagery Classification
논문리뷰
Physics-Informed Attention Temporal Convolutional Network for EEG-Based Motor Imagery Classification
1) 배경 및 목적
Brain Computer Interface 기반의 중요도에 비해, 복잡하고 많은 잡음이 존재하는 EEG데이터의 분석 및 예측 어려움이 존재
⇒ 본 논문의 ATCNet을 제시하며, 우수한 MI 분류 score를 기여
(MI 작업 종류: 왼손 상상 (1) / 오른손 상상 (2) / 양발 상상 (3) / 혀 상상 (4))
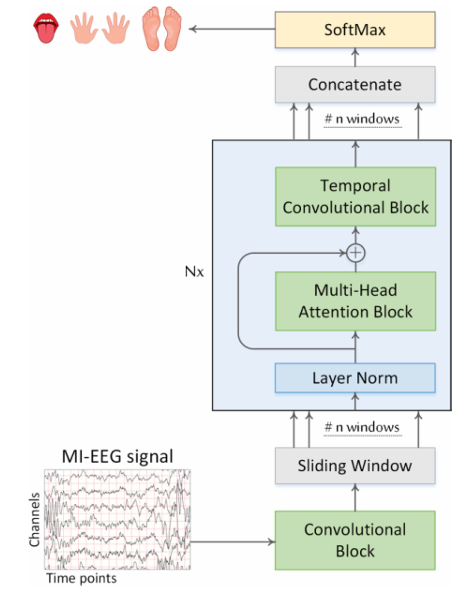
2) ATCNet model Architecture
본 모델은 세 가지 block으로 구성
① Convolutoin block ② Attention block ③ Temporal Convolution block
① Convolutoin block
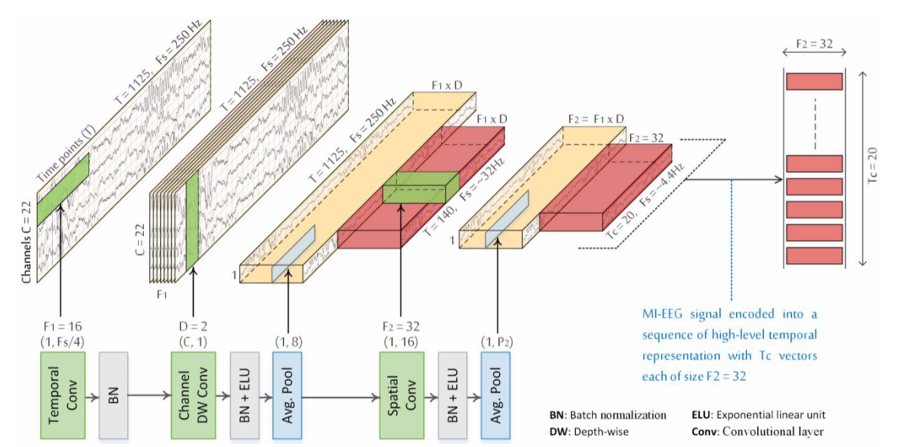
여기서도 세 가지 종류로 분할
- 시간
2D conv로 (1xkc) (kc=Fs/4) (Fs는 샘플링 속도Hz) F1=16개 사용.
- BatchNorm
- 채널
2D conv로 (Cx1) F1xD=16x2개 사용. (D=2 경험적)
- BatchNorm + ELU
- Average Pooling (1, 8)
- 공간
2D conv로 (1x16) F2=32개 사용. (F2=32 경험적)
- BatchNorm + ELU
- Average Pooling (1, P2=7)
뇌파의 시계열 분석에는 1D CNN이 용이하겠지만, EGG와 같이 공간 정보를 가져가기 위한 2D CNN 사용. (1D CNN에서 주로 사용하는 행을 Channel이라고 부른 것은 의아함이 항상 존재.)
⇒ 이 세 가지 layer를 통과하게 되면 그림과 같이 TCxF2 (20x32) 사이즈 feature가 완성
Q. 본 논문에서는 Average Pooling을 통한 각 8,7 사이즈를 통해 56 time point를 압축했다고 언급.
하지만 모델 앞 단의 시간 정보를 가져가기 위한 (1xkc) conv layer를 통해 receptive field 정보가 들어갔을 텐데? (이 부분은 미미함으로 무시했다고 생각하고 이해 )
⇒ 이후 Sliding Window를 통해 샘플링(데이터 증강) : 하나씩 밀어가며 취하는 것이 아닌 Conv layer를 통한 병렬화로 한 번에 작업.
② Attention block
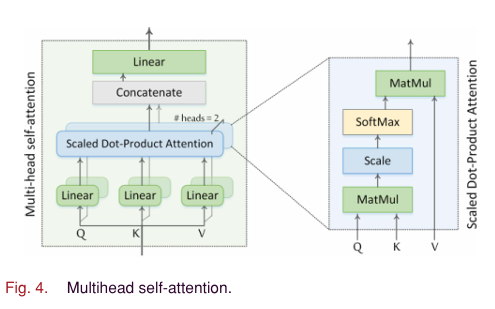
transformer의 MSA과 동일하게 사용
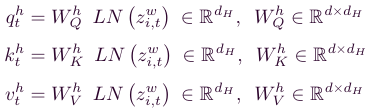
앞의 CV block에서 나온 feature를 통해 Q,K,V를 만들어 사용
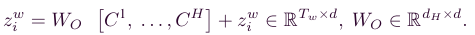
Residual connection 으로 identity shortcut을 통한 작업
- forward pass
identity shortcut을 이용해 더해주었는데, 점화식을 이용하여 풀어보면 아래와 같이 쭉 나온다. 그렇게 되면 빨간 식과 같이 초기값과 F들의 합으로 표현이 가능하다. - backward pass
cost에 대한gradient를 계산하면(초기 xk까지), K로 분해했을 때 위의 forward때 식을 가져와 미분하여 아래와 같이 (1 - ~ )로 표현 가능

③ Temporal Convolution block
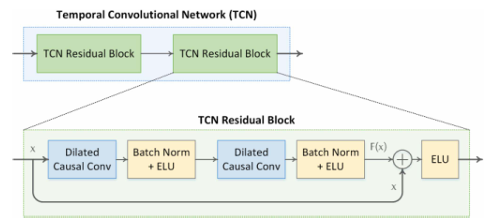
아래의 작업 실행
- 1) 3) Dilated Causal Convolution
- 2) 4) Batch Norm + ELU
- 5) Residual Connection
- 6) ELU
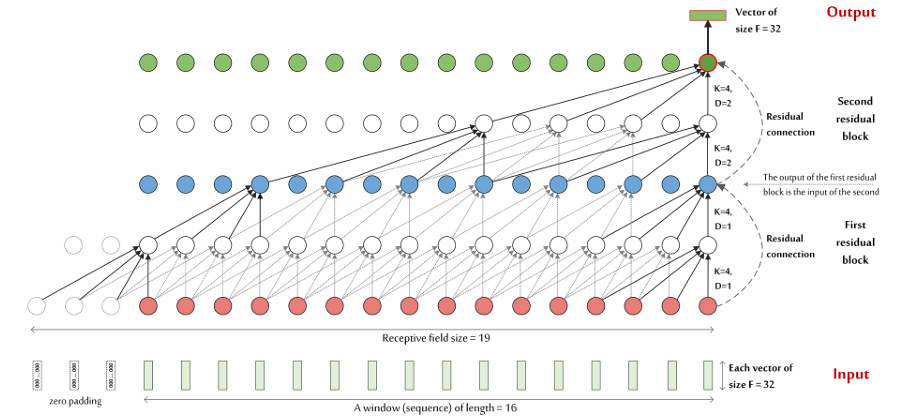
Dilated Convolution
classification은 layer가 깊어질 수록 픽셀 당 전체 이미지 정보가 들어가기에 좋지만(enlarge the receptive field), segmentation의 경우는 각 픽셀의 공간적 정보를 잃어버리기에 좋지 않다.
=> 이를 해결하기 위해 Dilated Convolution을 사용
이 Dilated Convolution를 기반으로 미래의 정보가 들어가지 않게 하는 Causal convolution을 사용
RFS = 1+2(KT −1) (2^L−1) 에 따라 receptive field는 19로 계산 가능.
Input개수로는 앞 전의 sliding window를 통한 (Tc(20) x F2(32) → 16개 (16x32)) 16개.
Output으로는 두 TCN Residual Block을 거쳐 나온 F2=Ft=32 사이즈 벡터
3) 결론 및 기여
본 논문의 ATCNet을 통해 ****EEG 기반 운동 상상 분류 모델을 제안 및 우수한 성능 기여
ATCNet은 세 가지 주요 블록으로 구성:
- Convolutional Vision Block : 원시 MI-EEG 신호를 압축된 시간적 시퀀스로 인코딩
- Multi-head Self-Attention Block : 시간적 시퀀스에서 가장 효과적인 정보를 강조
- Temporal Convolutional Block : 시간적 시퀀스에서 고수준의 시간적 특징을 추출
