Gradient Descent Optimization Algorithms
기본적인 뉴럴 네트워크의 weight를 조정하는 과정에서 보통 Gradient Descent라는 방법을 사용합니다. 이 방법은 네트워크의 파라미터를 θ라고 했을 때, 네트워크에서 도출되는 결과값과 실제 값의 차이를 정의하는 Loss function(J(θ))의 값을 최소화하기 위해 기울기를 이용하는 방법입니다. Gradient Descent에서는 Loss ft의 값을 최소화하는 θ값을 찾는 것이 목표이며, 이를 위해 기울기의 반대 방향으로 일정한 크기만큼 이동하는 것을 반복합니다.(보통 0.01~0.001)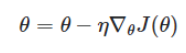
BGD / SGD
여기서 Batch Gradient Descent(BGD)와 Stochastic Gradient Descent(SGD)에 대해 말씀드리겠습니다.
우선 Loss ft을 계산할 때 전체 data set를 사용하는 것을 BGD라고 하는데, 이 방법은 한번 step을 내딛을 때 전체 data set에 대해 loss ft을 계산해야 하기에 너무 많은 계산량이 요구됩니다.
이를 방지하기 위해 나온 것이 SGD입니다. 이 방법은 loss ft을 계산할 때 전체 data set(batch) 이 아닌 일부 데이터의 모음(mini-batch)을 사용하여 loss ft을 계산합니다.
Q. 그렇다면 이에 대한 이점은 무엇일까요?
데이터의 일부만을 사용하여 계산하기 때문에, 위에서 말한 BGD의 너무 많은 계산량의 단점을 극복할 수 있습니다. 물론 SGD는 BGD보다 부정확할 수 있지만, 훨씬 빠른 계산 속도로 인해 같은 시간에 더 많은 step을 이동할 수 있습니다. 또한 더욱 좋은 이점은 Local minimum에 빠지지 않고 더 좋은 방향으로 수렴할 가능성이 높다는 것 입니다.
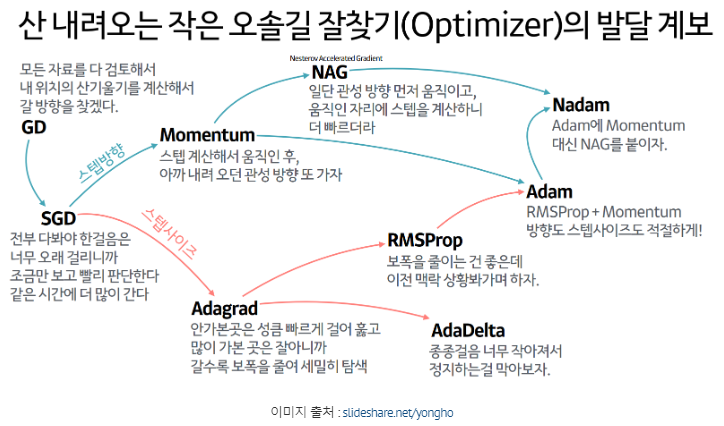
여기에 더해 이 SGD를 변형시킨 여러 알고리즘들이 있으며, 예로 Naive Stochastic Gradient Descent, Momentum, NAG, Adagrad, AdaDelta, RMSprop 등이 있습니다.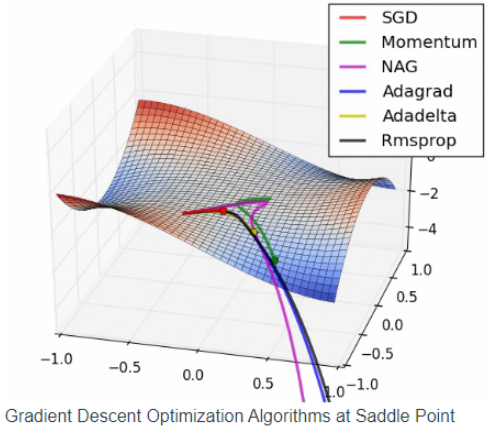
Momentum
Momentum 방식은 말 그대로 Gradient Descent를 통해 이동하는 과정에 일종의 '관성'을 주는 것 입니다. 현재 미분 Gradient를 통해 이동하는 방향과는 별개로, 과거에 이동했던 방식을 기억하며 그 관성을 가지고 일정 정도를 추가적으로 이동하는 방식입니다. 수식은 아래와 같습니다.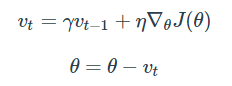
θ를 업데이트할 때 vt를 이용하는데, 이는 time step t에서의 이동벡터입니다. γ를 이용하여 얼마나 momentum을 줄지 정하고, 이전 vector에 γ를 붙여 θ에서 일정부분을 이동시켜 주는 역할을 합니다. (γ는 보통 0.9로 설정합니다)
γv(t-1)을 쭉 풀어쓴다면 vt는 아래와 같이 표현 가능하며, 'Gradient들의 지수평균을 이용하여 이동한다' 라고 해석할 수 있습니다.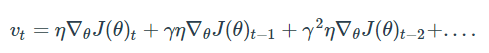
Momentum의 이점!
momentum 방식은 SGD가 Oscilation 현상(반복적으로 변화하는 현상)을 겪을 때 더욱 빛을 발합니다. 기존의 SGD같은 경우에는 최저점으로 이동할 때 step size의 한계로 인해 좌우로 계속 진동하며 이동에 난항을 겪기도 합니다.
하지만 Momentum은 이전의 관성으로 인해 중앙으로 가는 방향에 힘을 얻기 때문에 SGD에 비해 상대적으로 빠르게 이동할 수 있습니다. 또한 local minimum에서 빠져나올 때도 유리합니다. 위와 비슷한 말이지만, 기존의 관성으로 인해 이전 방향성을 가지고 있어 local minimum에서 빠져나와 더욱 좋은 minima로 이동할 수 있습니다.
하지만 momentum 방식을 사용할 때, 기존 변수들 θ 이외에도 과거에 이동했던 양을 변수별로 저장해야하기에 변수에 대한 메모리가 기존의 두 배로 필요하게 됩니다.
Nesterov Accelerated Gradient (NAG)
Nesterov Accelerated Gradient(NAG)는 Momentum 방식을 기초로 한 방식입니다.
하지만 Gradient를 계산하는 방법이 조금 다른데 아래의 그림을 보면, Momentum방식은 이동벡터vt를 계산할 때 현재 위치에서의 gradient와 momentum step을 독립적으로 계산하고 이를 더하여 actual step을 구합니다. 하지만 NAG는 momentum step을 우선적으로 고려합니다. momentum step을 먼저 이동했다고 생각한 후 그 자리에서의 gradient를 구해서 gradient step을 이동하여 actual step을 연속적으로 구하게 됩니다.
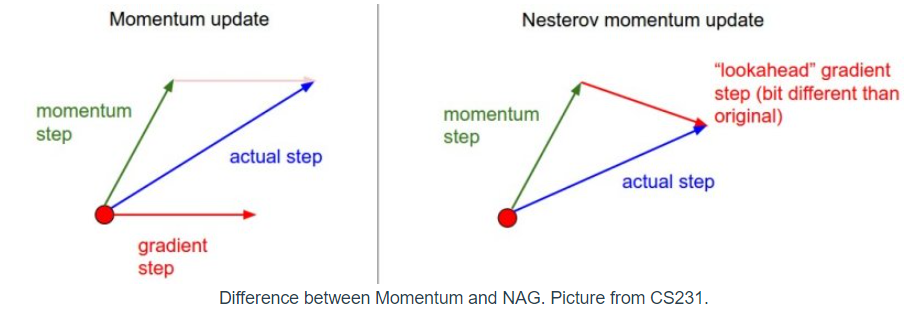
수식은 아래와 같습니다. Momentum은 vt(이전 vt-1에서 gradient를 더하고)를 구하고 θ에서 빼줬지만, 수식에서 보는 것과 같이 우선적으로 θ에서 momentum stpe을 빼고 여기서 momentum을 다시 적용시킵니다.
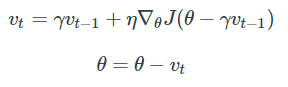
NAG 이점?
NAG를 이용할 경우 Momentum에 비해 효과적으로 이동할 수 있습니다. Momentum의 경우 멈춰야 할 시점에서 관성으로 인해 훨씬 멀리갈 수 있다는 단점이 있는 반면, NAG는 우선적으로 모멘텀으로 이동을 반정도 한 후에 어떤 방식으로 이동할지 정하기에 Momentum에 비해 안정적입니다. 즉, Momentum방식의 빠른 이동에 대한 이점은 누리면서도, 멈춰야 할 적절한 시점에서 제동을 거는 데 훨씬 용이합니다.
Adagrad(Adaptive Gradient)
Adagrad는 변수들을 업데이트할 때 각각의 변수마다 step size를 다르게 설정하여 이동합니다. 기본적인 아이디어는 '지금까지 많이 변화하지 않은 변수들은 step size를 크게 하고, 많이 변화한 변수들은 작게 하자' 입니다. 이 아이디어에 대한 근거는 자주 등장하거나 변화를 많이 한 변수들의 경우 optimum에 가까이 있을 확률이 높기에 작은 크기로 이동하면서 세밀한 값을 조정하고, 적게 변화한 변수들은 optimum에 도달하기 위해 많이 이동해야할 확률이 높기 때문입니다.
특히 Word2Vec이나 Glov같이 word representation을 학습시킬 경우 단어의 등장 확률에 따라 variable 의 사용 비율이 확연하게 차이나기 때문에 Adagrad와 같은 학습 방식을 이용하면 훨씬 더 좋은 성능을 거둘 수 있습니다.
Adagrad의 한 스텝을 수식화한다면 아래와 같습니다.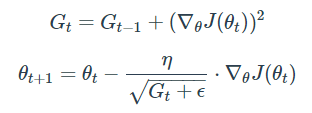
뉴럴 네트워크의 파라미터가 k개라고 할 때, Gt는 k차원 벡터로 써 time step t까지 각 변수가 이동한 gradient의 sum of squares를 저장합니다. θ를 업데이트 하는 과정에서 기존 step size η에서 Gt의 루트값에 반비례한 크기로 이동을 진행시키며, 많이 변화한 변수는 적게, 적게 변화한 변수는 많이 이동할 수 있도록 합니다. (입실로은 0을 나누는 것을 방지하기 위해 사용합니다)
Gt를 업데이트 하는 식에서 제곱은 element-wise 제곱을 의미합니다.
θ를 업데이트 하는 식에서도 ㆍ도 element-wise 곱을 의미합니다.Adagrad를 사용하면 학습을 진행하면서 굳이 step size decay(learning rate) 등을 신경써주지 않아도 알아서 조절해준다는 장점이 있습니다. (보통 adagrad에서 step size를 0.01 정도로 두고 변경하지 않습니다)
하지만 Adagrad에는 학습을 계속 진행하면 G에 계속 제곱한 값을 넣어주기에 G의 값들은 반복할 수록 증가하고, 이로 인해 step size가 너무 줄어든다는 문제점이 있습니다. 이는 결국 step size가 너무 작아져서 움직이지 않게 됩니다.
이 단점을 보완한 알고리즘이 RMSProp과 AdaDelta입니다.
RMSProp
RMSProp은 딥러닝의 대가 제프리 힌톤이 제안한 방법입니다. Adagrad의 식에서 gradient의 제곱을 더해나가면서 구한 Gt 부분을 합이 아닌 지수 평균으로 바꾸어 대체한 방법입니다. 이는 Adagrad의 단점인 Gt가 무한정으로 커지는 것을 막을 수 있습니다. 이에 더해 최근 변화량의 변수간 상대적인 크기 차이는 유지할 수 있습니다.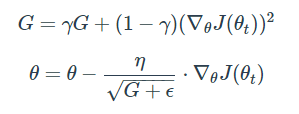
AdaDelta(Adaptive Delta)
AdaDelta는 RMSProp과 유사하게 Adagrad의 단점을 보완하기 위해 제안된 방법입니다. RMSProp과 동일하게 G를 구할 때 합을 구하는 대신 지수평균을 구합니다. 다만, 여기서는 step size를 단순하게 η가 아닌, step size의 변화값에 제곱을 취한 후 지수평균값을 이용해 아래와 같이 구합니다.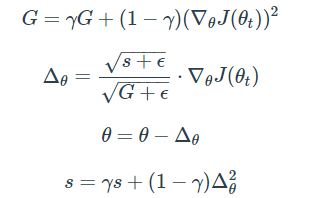
이러한 식이 도출된 이유로는 Newton method와 같이 second-order optimization을 approximate하기 위한 방법이라고 합니다. 그 이유로는 SGD, Momentum, Adagrad와 같은 식들의 경우 Δθ의 unit(단위)을 구해보면 θ의 unit이 아니라 θ의 unit의 역수를 따른다는 점을 지적합니다. u(θ) = θ의unit 이라고 하고, J는 unit이 없다고 생각할 떄, 1st order optimization에서는 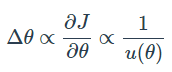 입니다.
입니다.
반면 2nd order optimization을 생각해보면 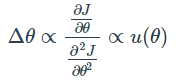 이므로 바른 unit을 갖게 됩니다. 따라서 저자는 Newton's method를 이용하여 위가 동일하다고 생각한 후,
이므로 바른 unit을 갖게 됩니다. 따라서 저자는 Newton's method를 이용하여 위가 동일하다고 생각한 후, 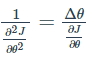 이므로, 이를 분자의 root mean square, 분모의 root mean square 값의 비율로 근사한 것 입니다. 이 부분은 더욱 자세히 공부해봐야 할 것으로 생각됩니다.
이므로, 이를 분자의 root mean square, 분모의 root mean square 값의 비율로 근사한 것 입니다. 이 부분은 더욱 자세히 공부해봐야 할 것으로 생각됩니다.
Adam(Adaptive Moment Estimation)
Adam은 RMSProp과 Momentum 방식을 합친 것과 같은 알고리즘입니다. 이 방식에서는 Momentum 방식과 유사하게 지금까지 계산해온 기울기의 지수평균을 저장하며, RMSProp과 유사하게 기울기의 제곱 값의 지수평균을 저장합니다.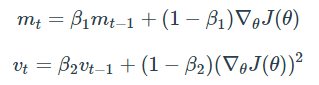
다만 Adam에서는 m과 v가 초기에 0으로 초기화되어 있기에, 학습 초반부에서는 mt, vt가 0에 가깝게 bias 되어있을 것으로 판단하여 이를 unbiased하게 만들어줍니다.
mt와 vt의 식을 ∑ 형태로 펼친 후에 양변에 expectation을 씌워 정리해보면, 아래와 같은 보정을 통해 unbiased 된 기댓값을 얻을 수 있습니다. 이 보정된 기댓값들을 가지고 gradient가 들어갈 자리에 mt hat을, Gt가 들어갈 자리에 vt hat을 넣어 계산을 진행합니다.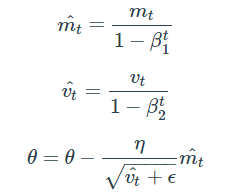
보통 β1은 0.9, β2는 0.999, ε은 10^(-8) 정도의 값을 사용한다고 합니다.
Summary
위는 모두 다양한 Gradient Descent 알고리즘의 변형 알고리즘들입니다. 어느 것이 가장 좋고 나쁘고는 없이 맨 위 첫 사진에서 보는 것과 같이, 어떤 문제를 풀고 있고 어떤 데이터셋을 사용하는지에 따라 적합하게 사용해야 합니다.
대부분 SGD 1st order optimization의 변형이지만, Newton's method 등 2nd order optimization을 기반한 알고리즘들도 있습니다. 하지만 이는 Hessian Matrix라는 2차 편미분 행렬을 계산 후 역행렬을 구해야 하기에 계산적으로 cost가 많이 들어 잘 사용하지 않는다고 합니다. 이런 계산량을 줄이기 위해 hessian matrix를 근사하거나 추정해나가면서 계산을 진행하는 BFGS / L-BFGS 등의 알고리즘, 그리고 hessian matrix를 직접 계산하지 않으면서 2nd order optimization인 Hessian-Free Optimization 등도 존재합니다. 수치해석을 들으며 배웠던 알고리즘들도 떠오르고 더욱 보완하며 공부해야할 부분도 느껴지는 것 같습니다.
참고 : http://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
