이제부터는 강화학습을 알아보겠습니다!
강화학습은 기본적으로 Markov Decision Process라는 확률 모델을 기반으로 하고 있습니다.
저희가 다루는 모형에 대한 수학적인 모델링이기 때문에 Markov Decision Process를 잘 이해할 필요가 있습니다.
두 번째로 다룰 모델은 Bellman Equation 입니다.
이것은 Markov Decision Process 문제를 해결하기 위해서 value ft이라는 가치 함수를 Bellman Equation을 통해 계산하게 되는데, 이를 통해 최적 정책이라는 optimal policy를 찾게 됩니다.
이 Bellman Equation을 풀어가는 방식은 두 가지가 있는데
1) Dynamic Programming
동적 계획법 - 모든 정보를 알고 계산하는 방법
양이 너무 많기에 효율적으로 Value iteration이나 ploicy iteration을 사용
2) Reinforcement Learning
모든 정보를 알 수 없고 샘플로만 데이터의 정보를 알기에 이것을 통해 policy라는 정책을 평가하고 업데이트 하는 방식
방법으로는 Monte Carlo, Sarsa, Q-learning이 있습니다.
그 다음은 Deep Reinforcement Learning입니다.
이것이 이번 강화학습에서 배울 핵심적인 내용입니다.
강화학습의 가장 대표적인 알고리즘 DQN과 A3C를 알아보고,
그 후 업데이트 된 모델들을 알아보게 됩니다.
이번 포스터는 Reinforcement learning, Deep Learning, Deep Reinforce learning에 대해 알아보겠습니다.
강화학습의 가장 큰 특징은 sample data가 미리 주어져 있지 않습다.
강화학습은 agent가 실제 환경속에서 상호작용을 하며 그때그때 얻어지는 데이터를 가지고 학습하는 것입니다. 강화학습의 주체는 agent이며, 이 agent는 강화학습을 통해서 스스로 학습하는 컴퓨터를 의미합니다.
이 agent가 주어진 환경 속에서 자신의 상태를 인식하는 것을 state라고 합니다.
그래서 자신의 상태를 인식하고 나서 그것에 맞게 어떤 행동을 취하게 되는데 그 행동을 action이라고 합니다.
그리고 이 action을 취한 후 reward를 받게 되는데, 그래서 agent는 state, action, reward 세 가지를 가지고 학습을 진행하게 됩니다.
예를 들어 로봇이 걸어가는 것을 training한다고 해보겠습니다.
길이 있고, 이 길을 로봇이 넘어지지 않고 잘 걸어가는 것을 목표로 할 때, 관절을 몇도 각도로 움직여야 할지가 중점입니다. 이 관절의 움직임을 action이라고 하고, 현재 노면의 상태와 관절의 상태를 state라고 합니다.
이 문제를 지도학습을 하려면 input이 state이고, label이 action이 됩니다. 하지만 관절 및 노면은 너무나 많은 조합들이 있기에 이런 종류의 데이터는 구할 수가 없습니다. 따라서 강화학습에서는 실제 환경에서 적절한 action 후 수정해가며 improve하는 방법으로 진행합니다.
넘어지면 -, 잘 가면 +로 reward를 주어 개선해갑니다.
각 state마다 이 상황이면 action을 어떻게 취할 지 미리 정해놓는데 이를 policy하고 합니다. 학습이 잘 되지 않았을 때는 이 policy가 성능이 좋지 않아 로봇이 많이 넘어질 것 입니다. 그럼에도 policy가 하나 정해지면 각 state마다 어떤 action을 취해야 할지 결정이 됩니다.
현재 state인 state st에서 이것이 Agent에 의해 인식이 되면 이 agent는 At라는 action을 취하게 됩니다. (예를 들어 t를 0.1초라고 한다면) At로 action을 취했더니, 그 다음 state으로 st+1이 나왔습니다. 또한 action에 대한 reward Rt+1을 얻습니다. 그리고 이렇게 나온 st+1은 policy에 의해서 action At+1이 취해지고 또 이로 인해 다음 state인 St+2가 나오게 됩니다. 이런 방식으로 동일한 policy 내에서 매 state마다 action을 취하며 다음 state를 얻고 action을 얻고 반복합니다. 또한 각 time step마다 action을 취한 후 reward를 얻게 됩니다. 이렇게 되면 특정 시퀀스가 만들어 집니다.
그럼 중요한 것은 policy가 좋으면 reward가 좋을 것이고 이 Total reward를 maximize하는 방향으로 policy를 학습하게 됩니다. 주어진 policy에 대해 Total reward를 계산하는 방법을 policy evaluation이라고 합니다. 이 Total reward를 maximize하는 방향으로 policy를 개선하는 방법을 policy improvement라고 합니다.
강화학습은 이를 반복적으로 하며 학습을 진행해 갑니다.
따라서 강화학습은 time이 중요한 문제가 됩니다. 또한 reward를 다 얻은 후에 policy update를 진행하기에 reward를 얻을 때 까지 기다려야 합니다. 이것이 강화학습의 특징입니다.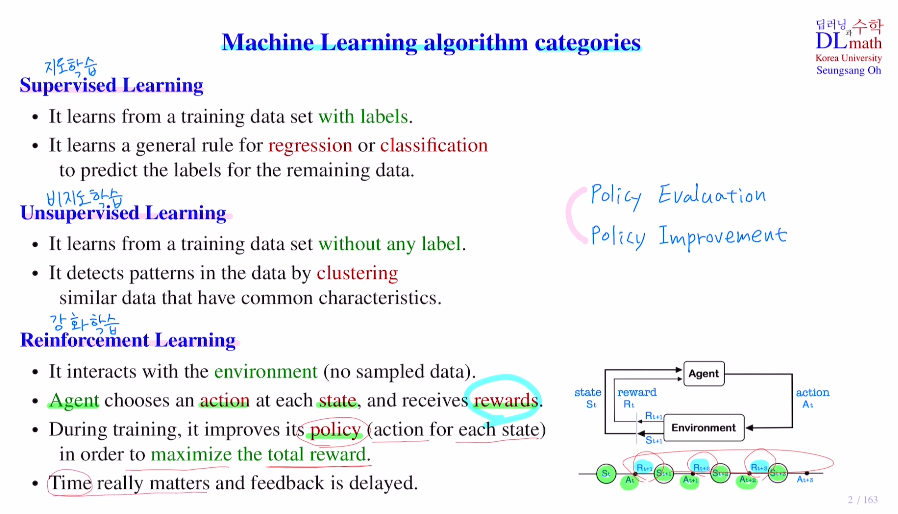
이제는 Deep Reinforcement Learning에 대해 알아보겠습니다!
이는 딥러닝과 강화학습의 학습으로 발전하게 된 계기는 Big Data와 컴퓨팅 파워의 증가 입니다. 그리고 여러가지 딥러닝 알고리즘에 의해 DRL이 많이 발전하게 됩니다.
robotics problem에서 한 관절에서 90가지 state variables가 있다면 관절이 10개만 해도 조합이 90^10이 됩니다. state set의 개수가 exponential하게 증가하므로 굉장히 많아집니다.
: 이를 디멘젼의 저주 curse of dimensionality라고 합니다.
강화학습이 이것을 잘 다룰 수 있게 딥러닝이 도와줍니다. 딥러닝이 low dim representation으로 바꿔주는 것 입니다. 예를 들어 이미지 데이터의 경우는 CNN을 통해 훨씬 작은 feature vector로 함축하여 바꿔줍니다. 이를 FC로 보내고 value ft으로 보냅니다.
마지막으로 DRL이 사람들에게 잘 알려진 계기는 DQN과 AlphGo입니다.
AI = DL + RL = DRL 
고려대학교 오승상 교수님 강화학습 강의 : https://www.youtube.com/watch?v=HXIbrL-glpU&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC
