이번에는 Monte carlo method가 아닌 Temporal Difference Learning에 대해 알아보겠습니다!
Temporal Difference Learning는 시간차학습을 말합니다. TD라고 하며 대표적인 알고리즘으로 Sarsa와 Q-learning이 있습니다.
Q-learning은 강화학습의 대표적인 알고리즘입니다.
강화학습이기에 model-free이며, tabular updating을 사용합니다.
TD도 policy iteration을 사용하는데 GPI를 사용합니다.
MC와 가장 큰 차이점은 MC는 에프소드by에피소드였지만(하나의 에피소드가 끝나면(terminal까지 가서) 그 에피소드를 가지고 MC를 진행), one step transitions를 사용한다는 점 입니다.
(terminal까지 가지 않고 one step transition만으로 바로 학습 가능)
장점은 DP처럼 boostrapping을 사용한다는점입니다.
next state의 true value 값이 아닌 estimate로 update
MC처럼 terminal까지 가지 않더라도 next state에서만 (St+1,At+1)로 Q value값만을 구한 뒤에 계산이 가능합니다. 마지막까지 기다리지 않아도 업데이트가 가능합니다.
MC의 경우 return을 사용하기에 게임이 끝날때까지 가야 return값을 계산한다는 단점이 있었습니다. 하지만 TD는 boostrapping을 사용하기에 online에 사용가능해 큰 장점이있습니다. MC처럼 샘플링해서 얻은 데이터로 학습을 진행합니다. next state에 대한 transition probability를 알지 못해도 계산이 가능합니다.
MC, Sarsa, Q-learning의 policy evaluation(prediction)을 알아보겠습니다.
여기서는 constant a PE를 사용했습니다.
MC에서는 target을 return으로 사용했습니다.
Sarsa는 immedidate reward와 next state action pair에 대한 Q value를 사용했습니다.
Q-learning은 Sarsa와 비슷해보이지만 immedidate reward와 next state에서 highest Q값을 갖게 하는 action을 취한 값을 선택하였습니다.
Sarsa는 At+1이 ε-greedy policy를 통해 action이 정해집니다.
Q-learning은 a가 next state에서 highest Q값을 갖게 하는 action을 선택한 것 입니다. 이 차이로 Q-learning의 성능이 급격히 올라가 강화학습의 대표적인 알고리즘이 되었습니다.
on policy : 현재 policy(behavior policy)에 의해 실제 target이 결정됩니다.(Gt,Q)
off policy : Q value를 maximize시키는 action은 current policy에서 결정된 것이 아닙니다.
Sarsa의 target은 bellman expectation eq을 가져온 것 입니다.
현재 policy에 의해 계산된 Q값, 현재 current policy의 Q value값을 학습한다고 보면 됩니다.(현재 current policy에서의 Q값을 학습하는 것이기에 on-policy)
Q-learning은 bellman optimal eq를 사용한 것 입니다.(Q의 optimal값을 목표로 학습하는 것이기에 off-policy)
Q-learning의 장점은 optimal Q ft값을 직접 학습하기에 훨씬 빠른 속도로 성능이 좋아집니다.
Sarsa는 st,at을 시작으로 rt+1,st+1,at+1를 얻어 (st,at,rt+1,st+1,at+1) 로 5개 piar가 샘플데이터가 됩니다. 하나의 에피소드에 이런 샘플이 여러개 나오기에 이를 가지고 학습을 하는 것 입니다.
Q-learning은 st,at로 rt+1을 얻고, st+1을 얻은 뒤에 at+1을 사용하는 것이 아닌, 모든 action에 대해 highest Q value를 갖는 action을 선택하게 됩니다. (st,at,rt+1,st+1) 까지만 데이터로 필요로 합니다. 이 4개의 페어가 하나의 샘플 데이터가 됩니다.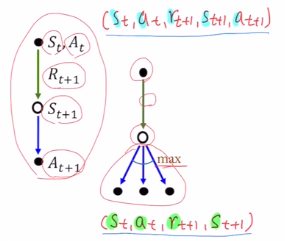
구체적으로 Sarsa와 Q-learning의 수도코드를 확인해보겠습니다.
Sarsa부터 보겠습니다.
초기화를 시켜주고(Q(terminal)=0), 하나의 에피소드에 대해 GPI(policy evaluation, policy improvement)가 진행됩니다.
starting point 초기화 S0
여기서 action을 (s,a) pair에 대한 Q 테이블이 있으면, ε-greedy policy를 통해 action을 선택합니다. a0선택 완료
이를 반복하여 s1,a1,s2,a2, ...
(st,at,rt+1,st+1,at+1) 이 필요하기에 ε-greedy policy로 at+1까지 구해줍니다.
이후 update eq를 사용하여 Q value값을 업데이트합니다. on policy
이제 st+1을 st로, at+1을 at로 변수를 바꾸고 또 여기서 나오는 5개 페어를 가지고 이를 반복합니다.
Q-learning을 보겠습니다.
마찬가지로 초기화를 시켜주고 각 에피소드마다 S를 초기화해줍니다.
여기서 ε-greedy policy로 a0를 선정합니다.
실제 환경에서 action을 취하게 되면 s0,a0를 통해 r1,s1을 얻게 됩니다.
여기서는 a1을 얻을 필요가 없습니다. a1은 Q value를 maximize하는 action을 골라주기만 하면 됩니다. 그렇기에 (st,at,rt+1,st+1)만을 가지고 사용합니다. off policy
이를 통해 업데이트를 진행하고 이를 반복합니다.
target안에서 action을 선택할 때 ε-greedy policy를 사용하는 것이 아닌 highest Q value를 갖는 action을 선택해주는 것 입니다.
이제는 on policy 와 off policy에 대해 알아보겠습니다.
DRL에서는 이 둘이 무엇인지 잘 알고 있어야 합니다.
우선 target policy와 behavior policy가 있습니다.
파란색을 target이라고 하며, 이 때 사용되는 action을 target policy라고 합니다.
현재 policy π가 있을 때, 실제 Q value ft qπ가 있을 텐데 이것의 estimate가 Qπ입니다. Qπ->qπ로 근사하기 위해 target으로 파란색을 사용하는 것 입니다.
agent가 학습하려고 하는 것이 target인데 target에 사용되는 policy가 target policy라고 합니다.
behavior policy는 action을 취할 때 policy를 말합니다. agent가 action을 선택하고 그것으로 인해 에피소드를 만들어 내는데 data를 generating하는 policy를 말합니다.
On-policy는 target policy = behavior policy 를 말합니다.
Sarsa가 대표적인 예가 되며, action을 선택할 때 현재 behavior policy인 Q에 대한 ε-greedy policy를 사용하여 next action을 선택하였습니다. 현재 policy를 따라갔다는 것 입니다.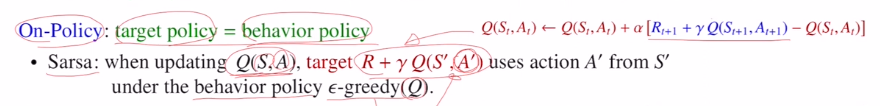
Off-policy는 target policy != behavior policy 를 말합니다.
현재의 policy를 따라가지 않는다는 것 입니다.
Q-learning이 대표적인 예이며, 업데이트 할 때 사용되는 target이 있을 때 action을 선택할 때 ε-greedy policy가 아닌 highest Q value값을 취하는 action을 선택한 것 입니다. current poliy인 behavior policy를 따른 것이 아닙니다.
target policy를 π(deterministic ex)greedy policy)라고 하며, behavior policy를 μ(stochastic ex)ε-greedy policy)라고 합니다.
Q-learning에서는 target에서 ε-greedy policy로 사용해서 action을 선택하는 것이 아니기에 π!=μ로 off policy가 됩니다.
on policy의 경우는 한 번 policy improvement를 취하면 지나간 data는 사용하지 않습니다.
off policy는 모든 action에 대한 정보를 사용합니다. 과거에 계산했던 것들을 같이 사용합니다. 또한 target에서 사용되는 것이 behavior이 아닌 다른 policy를 사용합니다. current에 얽매이지 않기에 exploration을 갖습니다. 새로운 action을 취할 확률이 높기에 궁극적으로 optimal policy를 얻을 수 있습니다.(on policy는 suboptimal policy일 가능성이 있습니다.)
고려대학교 오승상 교수님 강화학습 강의 : https://www.youtube.com/watch?v=5Vbn4XoE45w&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=13
