이번 포스터부터는 DQN을 배우겠습니다!
DQN은 Q-learning과 CNN을 합쳐서 만든 것 입니다.
이제는 Q-table을 사용하지 않고 Q-network를 통해 approximate합니다.
궁극적으로 Qlearning을 적용할 때, 모든 action에 대해 Q value를 평가하고 그 중에서 가장 큰 highest Q value값을 갖는 action을 선택하여 여기에 ε-greedy policy를 적용하는 것 입니다. Q(st,a)을 Q table에서 찾아서 사용합니다.
비슷한 방식으로 Q-network를 통해 Qvalue를 approximate합니다.
Q(st,a;θ) (θ는 CNN의 weight입니다.)
present state st가 입력으로 들어오면 모든 action에 대한 q value를 output으로 출력하는 것 입니다. 그래야 Q 테이블을 대신하는 Q network가 되는 것 입니다.
Qleanring에서는 Q table에 있는 q값의 optimal값을 계속 업데이트해서 찾는다고 한다면, DQN에서는 Q-network를 통해 optimal 값을 approximate하는 네트워크의 파라미터를 찾는 것이 목표입니다.
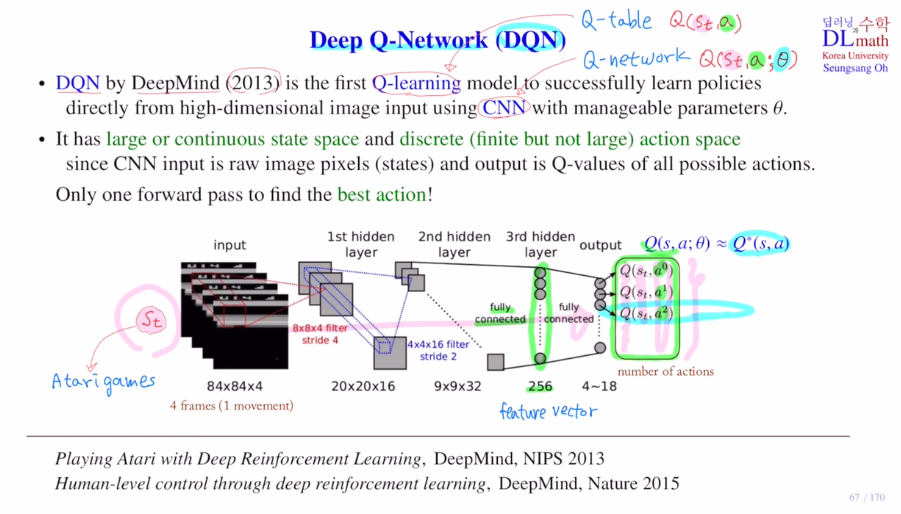
DQN은 Atarigame을 하기 위해 나온 것 입니다.
input으로 84x84화면 4개를 연속해서 받습니다.
화면을 4개를 넣은 이유는 정지화면 하나로는 어디로 올지 예측하기 어렵기 때문입니다.
이미지 데이터를 사용하기에 CNN을 사용합니다.
84x84x4
-> 8x8x4 filter stride 4 16개 : 20x20x16
-> 4x4x16 filter stride 2 32개 : 9x9x32
-> FC를 통해 256 feature vector 생성
-> FC 4~18 사이의 action이 나옵니다. (보통 action개수가 4~18)
-> st에 대해 모든 action에 대한 Q값을 계산하고 가장 큰 것을 찾습니다.
-> 여기에 ε-greedy policy적용하여 선택
이렇게 Q network를 통해 Q값을 approximate합니다. 이렇게 policy를 학습합니다.
CNN을 사용하기에 파라미터를 줄여 사용합니다. 큐테이블은 부담이 되는 이렇게 큰 state space를 다룰 수 있게 됩니다.
하지만 output으로 나오는 action의 개수가 너무 많으면 학습을 효율적으로 할 수는 없습니다. 그렇기에 DQN은 아직 finite한 action에서 사용가능합니다.(로봇의 경우 불가)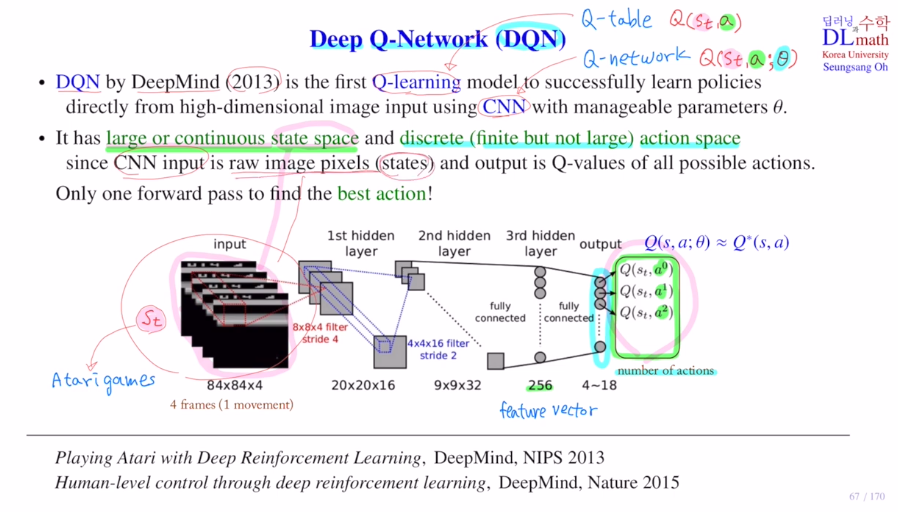
이번에는 Naive DQN을 알아보겠습니다.
가장 간단한 모델입니다.
Q-learning에서는 Behavior policy가 Target policy를 목표로하고 학습을 하며 둘 사이의 간격이 작아지는 쪽으로 학습을 합니다.
DQN에서는 큐테이블 대신 큐네트워크를 이용합니다. SGD을 써서 MSE를 줄이는 방향으로 학습합니다. L(Θ)를 줄이는 방향으로 학습합니다.
하지만 이는 성능이 별로 좋지 않습니다.
1) 샘플들 사이에 temporal correlation 2) tartget값들이 계속 바뀌는 non-stationary target이라는 문제가 생깁니다.
비선형함수를 쓰지도 않은 간단한 Linear모델과 비교했을 때도 성능이 좋지 않습니다.
이 두 문제를 해결하기 위해 딥마인드는 두 가지 장치를 장착합니다.
DQN은 Q네트워크를 통해 Q value ft을 approximate하는 것 입니다.
Experience replay(Replay buffer) :to overcome the temporal correlation problem
Target network : to overcome the non-statoinary target problem
이 두 가지를 통해 해결합니다.
++ Clipping rewards를 사용합니다.(게임마다 score기준이 다르기에 그냥 positive reward +1, negetive reward -1로 정합니다.)
end-to-end RL입니다.
각종 게임 룰들을 설명할 필요가 없이, input으로 image pixels과 게임 score만 넣어주면 학습을 진행합니다. 최소한의 정보만으로 학습합니다.
같은 알고리즘에 같은 아키텍쳐, 같은 하이퍼파라미터를 써도 다양한 아타리 게임들에 좋은 성능을 보입니다.
우선
Experience replay(Replay buffer) :to overcome the temporal correlation problem
부터 살펴보겠습니다.
온라인 상에서 진행된다고 하겠습니다.
experience(sample data)
새로운 데이터가 들어오면 바로 사용하고 버립니다.
하지만 이렇게 하면 temporal correlation 문제가 생깁니다.
로봇이 매초 걸어갈 때 넘어지지 않아야 postive reward를 받습니다.
만약 계속 state가 지나가는데 넘어지는 상황에서는 매 초 아직까지는 넘어지지 않았기에 positive reward를 받으며 학습합니다. 마지막에 딱 넘어졌을 때만 negative reward를 크게 받는 것 입니다. 하지만 온라인으로 계속 학습하기에 이렇게 되면 넘어지는 상황을 postive로 보아 학습하기에 문제가 생기는 것 입니다. 최근의 몇 개로만 approximation을 하면 문제가 생기는데 이를 temporal correlation 문제라고 합니다. 이렇게 되면 iid assumption이 바로 깨지게 됩니다.
또한 한 번 사용하고 바로 버리기에 자주 등장하지 않는 샘플은 중요함에도 불구하고 중요하지 않게 생각할 수 있습니다.
예를 들어 아래와 같이 전체적인 곡선을 approximate하고 싶은데 샘플을 몇 개만 가지고 하려니 첫 번째 그림과 같이 이차곡선으로 적합하지 않게 나옵니다.
따라서 이 문제를 해결하기 위해 experience replay를 사용합니다.
{s,a,r,a'}이 하나의 data sample이 되는데, 이것을 한 번 사용하고 버리면 아깝습니다. 따라서 이를 Replay buffer라는 창고에 저장합니다.
그 다음 네트워크 파라미터를 업데이트 할 때는 Replay buffer에서 미니배치만큼 random하게 꺼내서 사용합니다. 그렇기에 temporally correlated되어 있지 않습니다.
1) 이렇게 하면 학습할 때 샘플들 사이의 correlation 이 줄어들게 됩니다.
2) 한 번 업데이트할 때 하나의 샘플이 아닌 미니배치 만큼을 가지고 업데이트하기에 학습속도가 빨라집니다.
3) 잘 등장하지 않았던 중요한 정보들을 반복적으로 사용할 수 있습니다.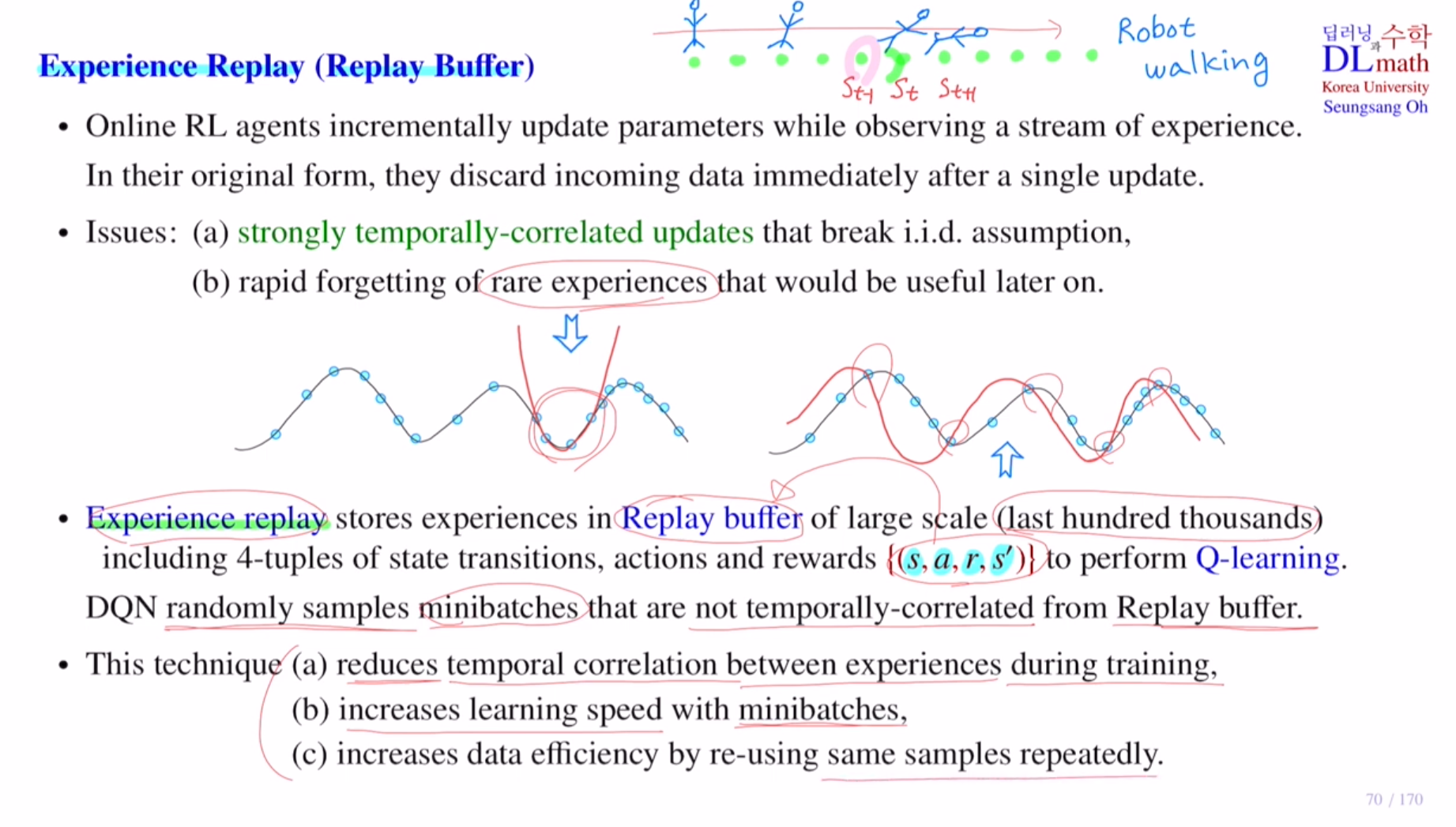
Replay buffer를 사용하는 방법을 알아보겠습니다.
action을 선택할 때 CNN을 통해 만든 큐 네트워크를 지나 state에 대한 action값들을 output으로 출력한다고 했습니다. 여기서 highest Q value를 가지고 action을 선택하게 됩니다. 이 때 사용되는 CNN network를 behavior Q network라고 합니다.
-Choose action at
0) Q네트워크에 input으로 present state이 들어왔을 때 output으로 모든 action에 대한 Q value값이 나올텐데
1) 그 중 highest Q value를 갖는 action을 선택하고 ε-greedy를 써서 action을 선택합니다.
2) 이렇게 정해진 action을 Environment 환경에다가 직접 취하게 됩니다. 이것을 execute at in emulator라고 합니다.
3) 이렇게 되면 immediate reward rt+1을 얻고, next state st+1을 얻습니다.
이제 하나의 데이터 샘플을 얻은 것 입니다.(st,at,rt+1,st+1)
-update network Θ
4) 얻은 샘플(new transition)을 이용해서 바로 업데이트 하지 않습니다! 이 얻은 데이터를 Replay buffer하는 창고에 저장합니다.
5) Replay buffer 한도를 10만개라고 한다면, 10만개까지 계속 데이터를 쌓다가 용량이 다 찼을 때는 새로운 데이터가 하나가 들어오면 가장 오래된 데이터(oldest transition) 하나를 버리게 됩니다.
6) 이제 학습을 시작하겠습니다. minibatch개수만큼 랜덤하게 샘플링을 하고 이를 통해 Q네트워크를 업데이트 합니다.
이렇게 Qnetwork를 사용하면 uncorrelated sample을 사용하고 미니배치만큼 업데이트하기에 Data efficiency가 좋아집니다.
고려대학교 오승상 교수님 강화학습 강의 : https://www.youtube.com/watch?v=eBIdI1hntf8&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=17
