이제부터는 심층 강화학습 Deep Reinforcement Learning에 대해 알아보겠습니다!
우선 RL과 DRL의 차이를 알아보겠습니다.
RL은 tabular updating method를 사용하고, DRL은 Function approximation method를 사용합니다.
state action value인 Q값을 (s,a) pair마다 테이블에 저장하는 것 입니다.
tabular updating method는 Q table에 있는 Q value값들을 bellman eq을 사용해서 반복적으로 update합니다. 그 후 궁극적으로 optimal policy를 찾아갑니다.
: 대표적인 알고리즘은 MC, Sarsa, Q-learning이 있습니다.
-> 여기서 가장 큰 문제는 state and action pair에 대해 테이블을 기록해야 하기에 너무 많아지면 메모리가 부족하다는 단점이 있습니다.
만약 모든 state and action pair에 대한 테이블에 저장하지 않아도 Q value값을 구할 수 있다면? 굳이 Q 값을 모두 기록하는 Q 테이블이 필요 없을 것 입니다.
따라서 이러한 Q값을 바로 구할 수 있는 Function이 있으면 좋습니다.
Function approximation method는 state-action value ft(Q ft) or policy 를 테이블을 통해 기록하는 것이 아닌, Deep neural network를 통해 업데이트 하는 것 입니다!
대표적인 모델인 DQN을 보면, input으로 특정 state 하나를 받는다고 하겠습니다. input의 dim은 state의 dim이 됩니다. output은 Q(s,a)값을 출력합니다.
여기서는 state space가 너무 커도(s1,s2,...) RL에 비해 Q table이 필요없기에 괜찮습니다.
특정한 state action pair에 대해 그것을 input을 집어넣고, output을 해당하는 action을 가지고 Q값을 출력하기에 테이블에 기록할 필요 없이 state를 넣으면 action에 대한 출력값을 잘 학습하면 됩니다.
value ft인 Q ft을 estimate하는 경우는 Deep Q-Network인 DQN이 있습니다.
policy를 approximate하는 경우는 Policy Gradient인 REINFORCE가 있습니다.
두가지를 합쳐 혼용으로 사용해 둘 다 approximate하는 경우는 Actor-Critic으로 A3C라고 합니다.
state space나 action space가 훨씬 크거나 continuous인 경우에도 사용가능하다는 것 입니다.
DRL은 딥러닝인데 라벨이 없는 딥러닝입니다. 테이블이 없는 RL입니다.
DRL을 왜 사용할까요?
딥러닝은 빅데이터가 발전하고 컴퓨팅파워가 발전하고 새로운 알고리즘들이 계속해서 만들어지고 있습니다. 딥러닝은 계속해서 발전하고 있습니다. 이제는 DRL을 통해 게임, 로봇, 금융 등에서 아주 좋은 성능을 냅니다.
특히 robotics의 경우는 state이 너무나 많습니다. 12개 관절을 state variable이라고 할 때, 각도를 0~90도로 매 1도씩 state이라고 하면 관절 하나 당 91개 state이 있는 것 입니다. 경우의 수가 91^12개만큼의 총 state이 존재합니다.
이렇게 exponential하게 증가하는 것을 차원의 저주라고 하며 curse of dimensionality라고 합니다.
기존 RL은 이렇게 큰 사이즈를 Q테이블에 감당할 수 없습니다.
이러한 경우를 DRL을 통해 해결합니다.
DRL이 크게 알려지게 된 경우는 DQN과 AlphaGo(cnn+RL)입니다.
Milestones in Deep Reinforcement Learning
Reinforcement Learning
trial and error learning 효과의 법칙 : 반복적으로 우연히 행동을 취할 때 보상을 얻으며 행동결과에 따라 변화시키고 발전시킨다 : 강화 reinforcement
SNARC : 처음으로 RL을 도입한 신경망
DP : bellman eq를 이용해 optimal control(최적제어)를 수학적으로 formular한 Markoc Decision Procees를 해결
TD : 시간차학습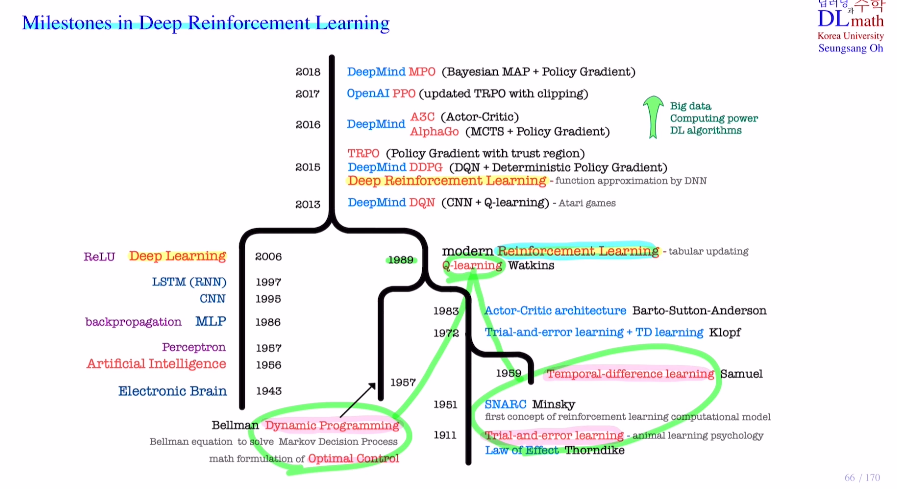
Deep Learning
Electronic Brain
AI
perceptron - learning - XOR winter시작
MLP - Hinton backpropagation
CNN
RNN - simoid 기울기소실 winter2
Relu - 기울기소실 해결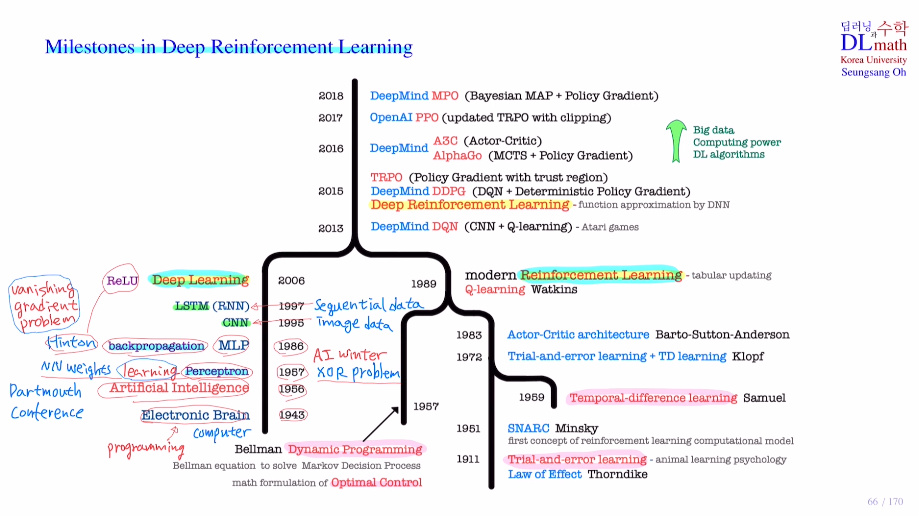
DRL
DQN - finite state space를 large or conti state space로 확장
DDPG, TRPO - finite action space도 conti로 확장
A3C, AlphaGo
PPO
MPO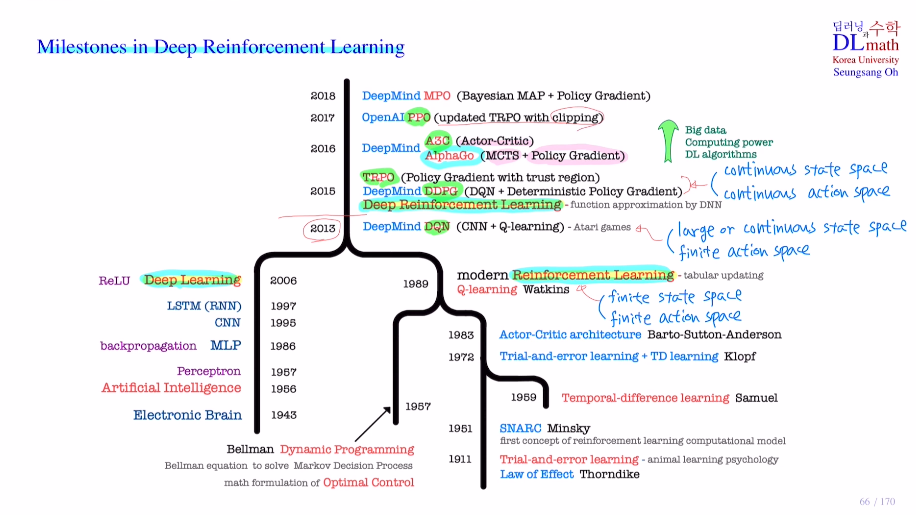
고려대학교 오승상 교수님 강화학습 강의 : https://www.youtube.com/watch?v=TL1RavBMag8&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=16
