Policy gradient는 DQN과는 구별되는 두 가지 특징이 있습니다.
첫 번째는 neural network로 Q ft이 아닌 policy를 직접 학습한다는 점입니다. 따라서 output이 stochastic으로 action이 나옵니다. output으로 직접 action을 출력하기에 conti action space에 대해서도 다룰 수 있었습니다.
두 번째는 total reward를 maximize하는 방향으로 학습합니다.
그렇기에 neural network에서 파라미터가 정해졌다는 것은 policy하나가 정해졌다는 것 입니다. 하지만 stochastic이기에 policy가 하나가 나올 수도 있지만 확률분포로 나올 수도 있습니다. random성이 작용할 수 있다는 것입니다.
하나의 에피소드인 trajectory를 얻고 이를 통해 total reward를 얻습니다.
policy가 정해져도 랜덤성에 의해 주어진 policy에서 나올 수 있는 trajectory는 많이 있습니다. 그래서 목적함수를 파라미터에서 정의된 policy에서 전체 total reward를 expectation한 값이 목적함수가 됩니다.
여기서 expectation형태를 갖고 있기에 gradient를 계산할 수 없습니다.
따라서 policy gradient thm을 사용합니다.
total reward * policy에 log를 취한 것에 gradient를 한 것의 time step sumation
의 expectation
이론적으로는 total reward를 사용했지만 강화학습의 방향성과 맞게 이전 reward는 무시하는 것으로 discounted return Gt를 사용합니다. 이렇게 되면 time step에 depend되는 것이기에 sumation 안으로 들어가게 됩니다.
또한 expectation을 approximate하기 위해 미니배치사이즈 만큼 샘플링을 하여 이에 대한 평균을 취하게 됩니다.
따라서 이 두 가지를 변형한 것을 REINFORCE라는 알고리즘에 적용합니다!
이 REINFORCE는 return값을 그대로 사용하기에 Monte Carlo Policy Gradient라고도 합니다. 이는 policy gradient algorithm의 가장 기본적인 모델입니다.
수도코드를 확인해보겠습니다.
3) 파라미터가 업데이트 되었다고 했을 때, 이렇게 뉴럴 네트워크의 파라미터가 정해졌다는 말은 이것이 approximate하는 policy가 정해졌다는 말입니다. 이 policy가 정해지면 이 policy에 의해서 에피소드를 여러개를 만들어 낼 수 있습니다. 1) 따라서 이렇게 미니배치 개수만큼의 M개의 에피소트를 만들어냈다고 하겠습니다.
(neural network으로 표현된 (stochastic) policy를 따라서 s라는 state에서 시작해서 M개의 tarjectories(에피소드)를 만들어 냅니다.)
2) 그 다음 policy gradient thm에 의해서 계산을 해줍니다.
3) 이 값에 step size 알파를 곱해서 파라미터를 업데이트 합니다.
이 과정을 반복하며 policy를 업데이트합니다.
이 REINFORCE의 특징은 policy를 직접 업데이트한다는 점과 total reward 대신 discounted return Gt를 사용한다는 점입니다.
REINFORCE with baseline
하나의 policy를 통해 trajectory를 정할 텐데 stochastic이므로 랜덤성이 적용됩니다. 계속해서 랜덤성이 적용되므로 상당히 많이 누적되어 variance가 굉장히 커지게 됩니다.
MC : return 기반, 게임끝날 때 까지 진행, 따라서 bias x, variance high
TD : 한 step만 고려, bias 0, variance low
variance가 크면 bias가 작아도 conv 속도가 느립니다.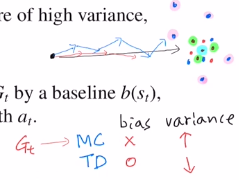
1) 샘플 데이터의 variance 줄이기 2) unbias를 만들기(최종 방향)
variance를 줄이기 위해 discounted return Gt에 baseline b(st)를 빼줍니다.
baseline은 action에 depend하지만 않으면 됩니다.
gradient에 어떤 것을 취할 때 조건이 하나가 붙습니다.
: gradient 값이 변화하면 안 된다. 방향을 잘 잡아야 하는데 값이 변화하면 biased가 되어 이상한 방향을 잡고 나아가게 됩니다.
=> 여기서는 b(st)와 관련한 값이 애초에 0이기에 gradient가 변화하지 않습니다!
모든 trajectory가 적용되어 있고, action과는 관계가 없기에 baseline을 뺄 수 있습니다. 한 state에 대한 모든 action값의 prob합은 1이기에 1을 미분하면 0이므로 0이 됩니다!
그렇다면 baseline을 어떤 것으로 잡을까요?
우선 action과는 관계가 없어야 합니다.
그래서 state value ft V(s)를 주로 사용합니다.
따라서 state value ft을 baseline으로 잡고 빼주어(그렇게 되면 Gt에서 return의 평균값을 빼준 것) variance를 줄여줍니다.
따라서 REINFORCE with baseline가 그냥 REINFORCE보다 학습이 잘 됩니다.
REINFORCE with baseline의 수도코드를 확인해보겠습니다.
이제는 baseline인 state value ft이 생겼습니다. 그렇기에 네트워크가 두 개가 됩니다.
하나는 원래의 policy gradient algorithm에 있는 policy를 approximate하는 네트워크 Θ가 있고, 하나는 baseline에 사용되는 state value ft을 approximate하는 네트워크 Φ 입니다.
Φ 를 업데이트할 때는 state value값을 찾아가야 하는데 이것은 return의 expectation입니다. return을 타겟으로 잡고 MSE를 통해 gradient descent를 통해 적용합니다. δ는 두 네트워크를 업데이트 할 때 동일하게 사용되는 부분입니다.
나중에 actor 네트워크(policy와 관련한), critic 네트워크를(방향이 정해지면 얼마나 나갈지) 배울텐데 REINFORCE with baseline을 확장한 것 입니다.

두 네트워크를 사용하는데 아래와 같이 사용해도 무방합니다.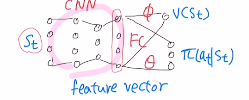
DQN vs Policy gradient
아타리 게임 DQN은 Q-learning을 CNN과 함께 사용한 것 입니다.
알파고는 Policy gradient를 MCTS를 함께 사용하였습니다.
주로 Policy gradient가 성능이 더 좋은데,
1) RL에서 핵심 아이디어는 total reward를 maximize하는 방향으로 업데이트 하는 것 이었습니다. 하지만 DQN의 경우는 optimal한 q value값을 찾고 그것을 통해 policy를 찾았습니다. policy를 바로 업데이트 할 수 없습니다. 그에 반해 Policy gradient는 policy를 직접 찾는 것이고(best action을 직접 학습합니다.), expected total reward를 직접 optimize하는 방향으로 합니다. Policy gradient가 RL의 핵심 아이디어와 일치합니다.
2) DQN의 경우는 q learning이기에 temporal correlation의 영향을 받아 experience replay를 통해 방지해줬습니다. 하지만 Policy gradient의 경우는 total reward를 사용하기에 굳이 temporal correlation의 영향을 받지 않습니다.
그렇기에 코드가 훨씬 간단합니다.
고려대학교 오승상 교수님 강화학습 강의 : https://www.youtube.com/watch?v=CH09gfU7ko4&list=PLvbUC2Zh5oJtYXow4jawpZJ2xBel6vGhC&index=22
