이전 포스트에서 오버피팅에 관해 다루었다. 이것은 뉴럴 네트워크의 학습을 방해하는 대표적인 문제로 이 과적합을 방지하기 위해 오늘 언급할 Dropout을 사용한다.
코딩을 할 때는 Dropout(p) (p:0~1)으로 쉽게 사용 가능하다. 보통 0.3
일반화 기법으로 학습할 때, training data에 너무 초점을 맞추는 것을 방지하기 위해 node를 임의로 random 제거하는 것이다.
feature를 표현하기 위해 weight들이 업데이트 될 것이다.
하지만 만약 비슷한 feature들이 많다면?(꼬리정보, 꼬리정보, 귀정보, 귀정보, 귀정보, ...)
성능이 꽤 좋진 않을 것이다. 따라서 각각의 node들의 feature들이 서로 다른 특징 정보(꼬리정보, 귀정보, 눈정보, ...) 를 갖고 있어 output으로 보낼 때 특정된 하나를 맞출 수 있게 하는 것이 좋다.
각 weight의 gradient는 독립적인 것이 아니라 결국 최종 Cost를 줄이는 것이 공통 목표이기에 다른 weight들의 영향 또한 받게 된다. 다시 말해, 귀 정보에 대한 weight가 좋아서 cost를 낮추는 방향으로 가도, 꼬리 정보 weight가 좋지 않아 cost를 늘리는 방향으로 간다면 의미가 없다는 것이다. 그렇기에 다른 노드들도 고려하며 cost를 줄이는 방향으로 고려하게 된다.
하지만 점점 심해지면 이를 Co-adaptation이라고 하며 서로 feafure간 너무 깊게 관여하게 된다.(각 노드는 자신의 것을 집중하면 좋을 텐데 너무 깊게 서로를 고쳐주기 위해 끌려다닌다) 이런 것들이 너무 많아지게 되면 한 layer의 feature들이 여러개의 것들을 다양하게 찾는 것이 아닌, 몇 개 안되는 특징을 같이 찾게 되어 성능이 떨어지게 되는 것이다!
=> 이렇게 오버피팅이 발생하게 된다.
이 과적합을 방지하기 위해 Dropout인 regulization technique를 사용한다.
각각의 node들이 자신만의 독립적인 feature를 찾으면 좋겠다!
이를 통해 정답을 내리기 수월해진다. 따라서 일반화 성능을 높이고 새로운 데이터가 들어와도 잘 예측할 수 있게 된다.
dropout으로 node들을 임의적으로 없애어 Co-adaptation을 줄이게 된다.
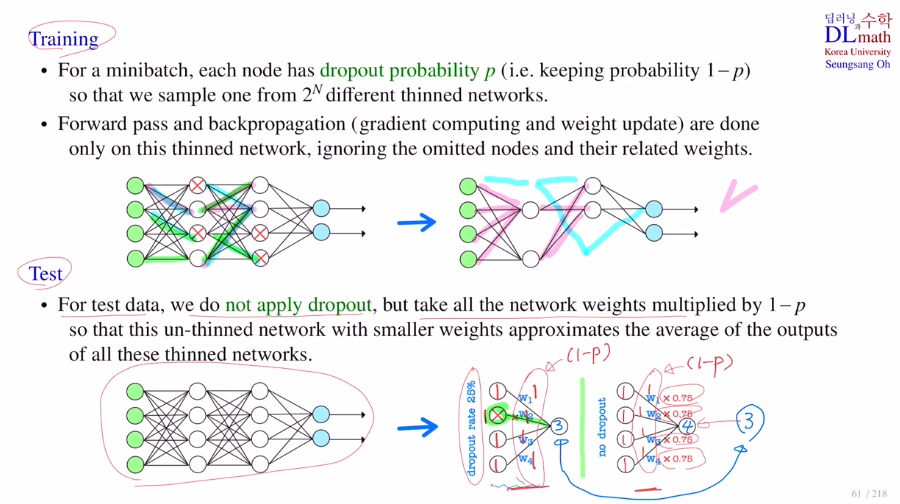
각 iteration마다 새롭게 dropout을 진행한다. (미니배치마다 새롭게 정의)
dropout(0.3)을 진행한다고 가정하면, 각 노드들이 사라질 확률이 30%인 것이다. 전체 노드 중 30%가 사라지는 것이 아니다! 그렇기에 모두 살아있을 수도 있다.
(training할 때만 사용)
backpropagation은 지워진 노드는 생각하지 않고, connection된 것들에 대해서만 진행하여 update한다.
node는 위에서 말했듯 p=0.2일 때 20%가 없어지는 것이 아닌, 20%확률로 각 노드가 없어지는 것이기에 한 iteration당 2^N (N:노드개수) 개 중 하나의 thinned network를 전정하여 학습이 진행되는 것이다.
test할 때는 dropout을 할 필요가 없다. why? 학습시 co-adaptation을 낮추기 위해 한 것이기 때문이다. 잘 학습되었는데 굳이 모델을 단순화시킬 필요가 없기 때문!
하지만 아주 중요하게 고려해야 할 점이 있다. 각 weight값들이 dropout할 때 update되었으므로, 다 살린 상태에서 weighted sum을 하면 값이 적절히 나오지 않게 되는 것이다. (training시에 3개가 4개 역할을 했기에 값이 크다)
이 문제를 방지하기 위해 각 weight들의 값을 조금 줄여줘야 한다. 따라서 각 weight들에 1-p를 곱해서 줄여준다!
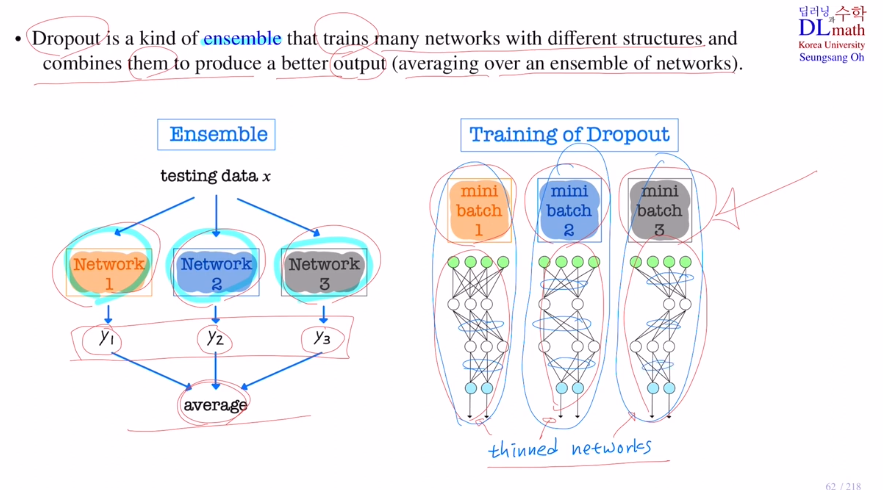
앙상블의 개념을 살펴보자.
네트워크 여러개를 사용하고 싶을 때, 각각의 결론을 가지고 종합하여 판단한다.
다른 모양의 네트워크들을 각각 학습하여 나온 결론을 하나로 종합하여 예측하는 것이다!
dropout은 이 앙상블과 비슷하게 했다고 할 수 있다. 미니배치마다 서로 다른 network구조를 사용하였고, 이 여러 결과로 인해 각 weight들을 업데이트하며 점점 최적화를 진행했기 때문이다.
(앙상블과는 다르다. 앙상블은 각 모델의 결과값을 이용해 결론을 도출하는 것)
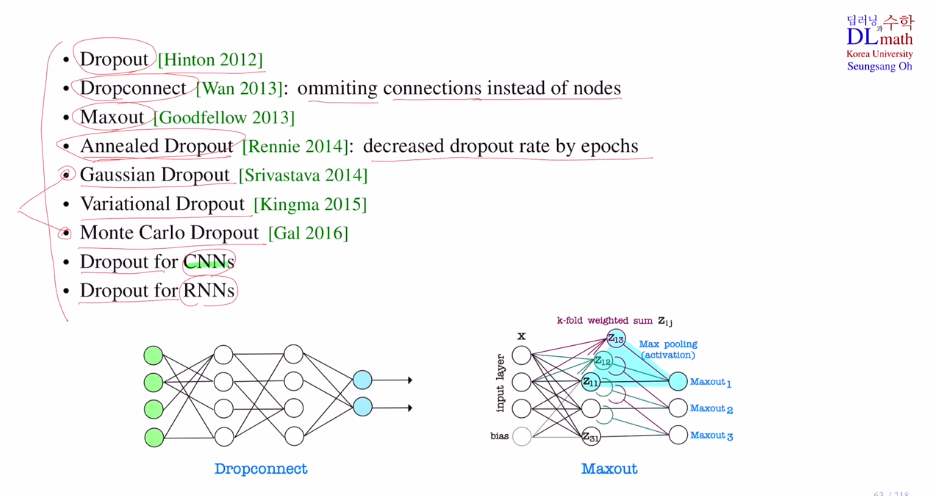
Dropout의 종류는 아래와 같이 꽤 많다.
특정한 connection만 없애는 Dropconnect
Maximum을 고르는 Maxout
학습이 진행되기 전에는 초기화된 weight이기에 co-adation을 할 가능성이 높다. 하지만 학습이 꽤 진행된 후에는 co-adation이 줄어들 것이다. 따라서 초반에는 dropout을 높이고 점점 줄여가는 방식인 Annealed Dropout
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=EnCKWmj9WVA&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=14
