고려대학교 딥러닝
1.고려대학교 딥러닝(오승상교수님) - 1. Introduction
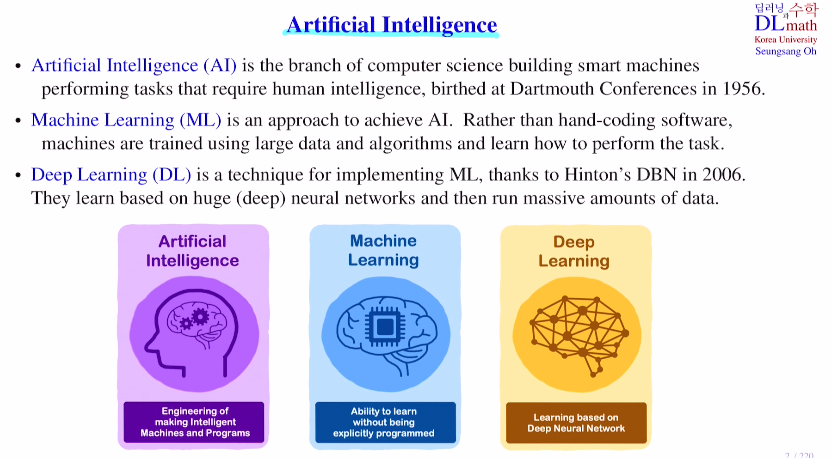
인공지능, 머신러닝, 딥러닝이 셋은 비슷해 보이지만 우선 차이가 있다.AI ⊃ ML ⊃ DLAI : 인간의 학습과 추론, 이를 통해 새로운 것에 대한 추론으로 예측할 수 있다.사람의 지능을 필요로 하는 것을 컴퓨터 같은 스마트 머신을 이용하여 대신 수행한다.ML : 기
2.고려대학교 딥러닝(오승상교수님) - 2. Perceptron MLP
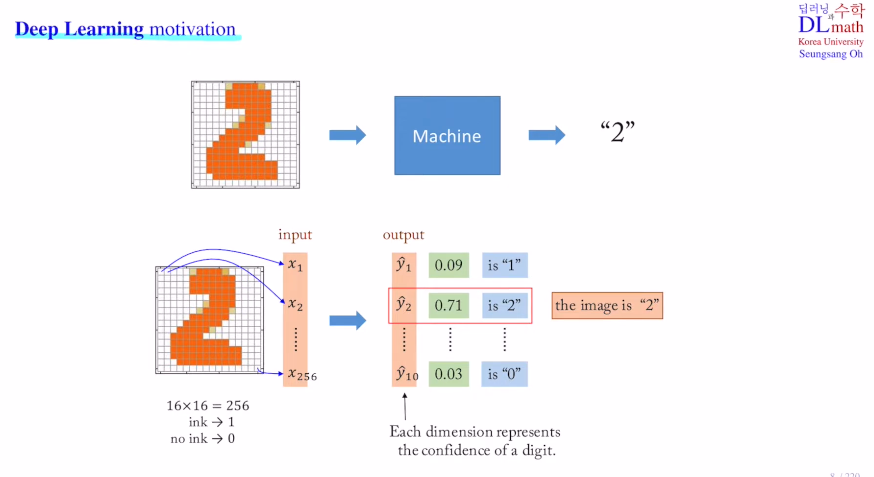
딥러닝의 motivation이 그림을 사람이 아닌 컴퓨터가 2이구나 하고 인식할 수 있게 만들기.how? 이미지를 각 grid로 나누어 픽셀로 구분하고 값(0or1)을 넣어 input vector로 이용한다. 이를 conv layer를 통해 훑은 후 linear lay
3.고려대학교 딥러닝(오승상교수님) - 3. DNN forward pass
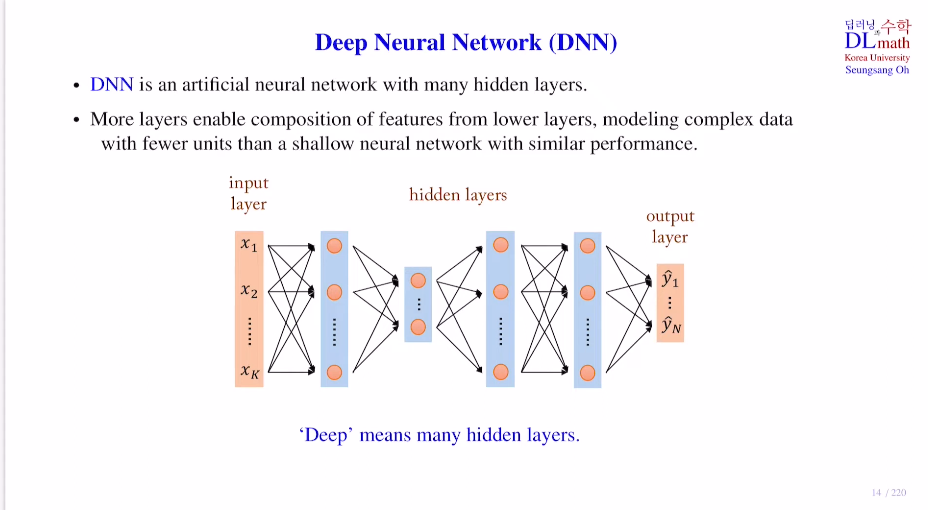
퍼셉트론의 조합을 이용한 딥러닝multi layer perceptron : 복잡한 문제를 해결할 수 있게 된다.Deep Neural Network : DNN : Input layer / Hidden layer / Output layerweight sum + bias =
4.고려대학교 딥러닝(오승상교수님) - 4. Cost Gradient descent
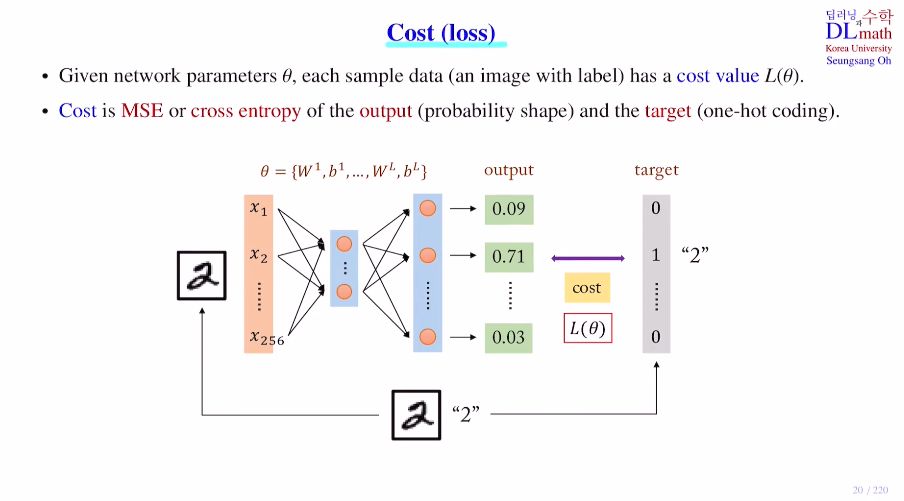
저번시간까지는 DNN과 forward pass computation을 배웠다면, 이제는 backpropagation을 위한 cost(loss) ft을 알아보자.forward pass를 통해 도출된 output값을 이용하여 원래의 정답 라벨과 차이를 통해 cost val
5.고려대학교 딥러닝(오승상교수님) - 5. Stochastic Gradient descent

Gradient Descent의 변형들을 알아보자!VAE를 공부하며 정리했던 VAE 이해하기 위한 내용(1)를 참고하면 더욱 이해하기 수월할 것이다.1) forward pass output 2) cost 3) backpropagation(gradient descent)
6.고려대학교 딥러닝(오승상교수님) - 6. Backpropagation

cost ft을 통해 weight와 bias를 업데이트 시키는데, 이 업데이트를 하는 과정에서 식이 굉장히 복잡하고 파라미터의 수가 많다면 계산하기 까다로울 것이다. 이를 방대한 계산량을 보완하기 위해 나온 것이 바로 backpropagation이다! 컴퓨터가 효율적으
7.고려대학교 딥러닝(오승상교수님) - 7. Vanishing gradient

이번 시간에는 Vanishing gradient, 기울기 소실에 대해 알아보자!우선 아래는 7개의 미분 텀이 존재하는데 input layer, 2개의 hidden layer, output layer로 구성되어 있다.(n:input data개수, j:중간output di
8.고려대학교 딥러닝(오승상교수님) - 8. DL history
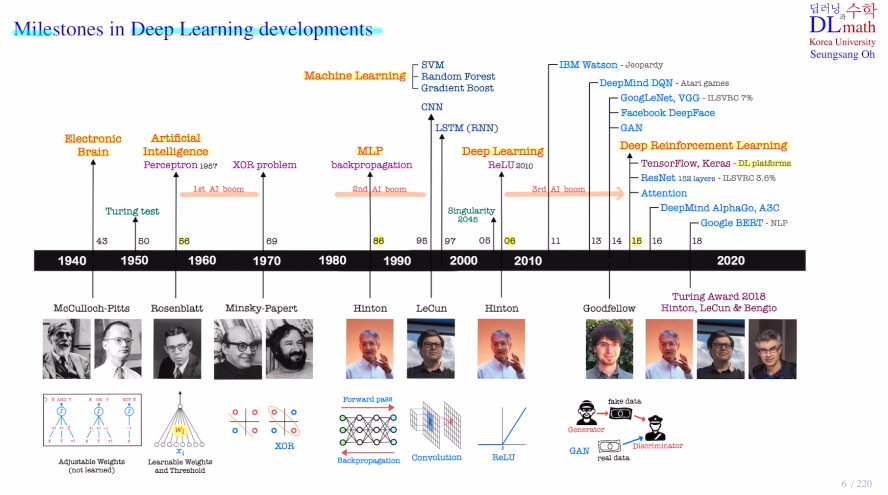
AI 역사에 대해 알아보자!초창기 인공지능과 딥러닝의 발전을 보자Eletronic Brain(Computer:ENIAC)프로그래밍 : 뉴런을 본 따 만든 것, weight를 계산하고 step ft을 통해 도출=> AI . perceptron 1차AI붐 learning컴
9.고려대학교 딥러닝(오승상교수님) - 9. Regression
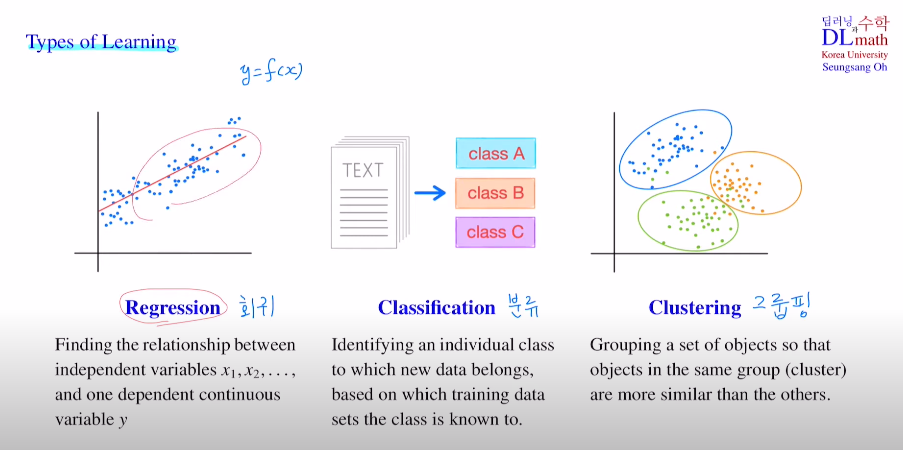
Linear regression : 데이터들을 잘 설명할 수 있는 선형 함수회귀에서 사용되며 이 모형을 만들고 새로운 데이터가 들어왔을 때, 이를 이용하여 예측값을 도출해낸다.Q. 그렇다면 이 모형은 어떻게 최적화시킬까?MSE를 이용한 Cost을 통해 각 편미분으로 파
10.고려대학교 딥러닝(오승상교수님) - 10. Universal Approximation Theorem

Deep Neural network의 학습 능력을 어떻게 평가할 것인가?!=> Universal Approximation Theorem중요한 문제1) 성능이 어디까지가 한계인지 2) 최대한 단순하게 구조를 짜기아래 그림은 perceptron 다음으로 가장 간단한 hid
11.고려대학교 딥러닝(오승상교수님) - 11. Activation function

acitivation ft은 아래와 같이 많은 종류가 있다.non linearity는 데이터의 복잡한 표현들을 나타내는데 용이하게 해준다. Q. 왜 활성화 함수를 사용해야 하는가?활성화함수를 사용하지 않는다면, WL...W1x = Wx로 단순 하나의 layer만 갖는
12.고려대학교 딥러닝(오승상교수님) - 12. Gradient descent optimizer
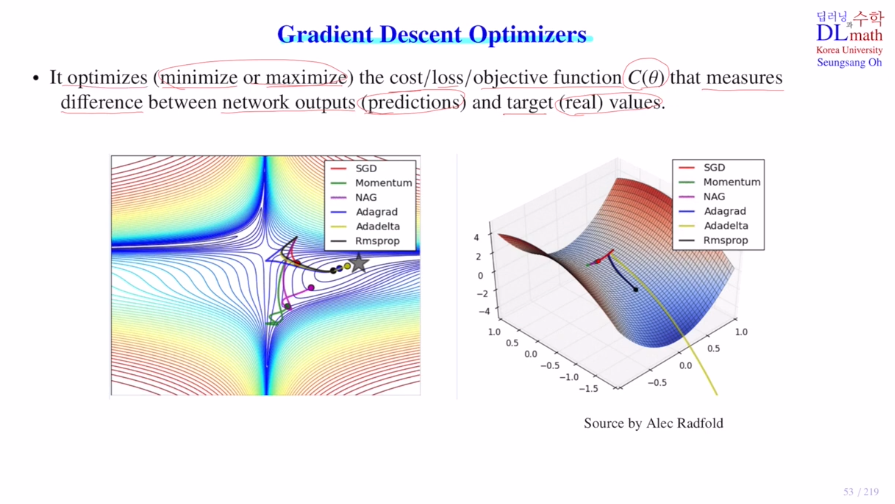
Cost ft의 minimum값으로 다가가야 하는데, 초반에는 크게 움직이고 점점 다가갈 수록 작게 움직이는 것이 가장 효율적일 것이다. : Learning rate decay이와 관련한 내용들을 알아보자.VAE 이해하기 위한 내용(1) - Gradient Descen
13.고려대학교 딥러닝(오승상교수님) - 13. Overfitting

1) shuffle data 2) ① Training set / Test set split 0.7 0.3 분리② Training set / validation set / Test set 0.6 0.2 0.2 로 분리\-> val set을 통해 모델을 선정 및 하이퍼 파
14.고려대학교 딥러닝(오승상교수님) - 14. Dropout1

이전 포스트에서 오버피팅에 관해 다루었다. 이것은 뉴럴 네트워크의 학습을 방해하는 대표적인 문제로 이 과적합을 방지하기 위해 오늘 언급할 Dropout을 사용한다.코딩을 할 때는 Dropout(p) (p:0~1)으로 쉽게 사용 가능하다. 보통 0.3일반화 기법으로 학습
15.고려대학교 딥러닝(오승상교수님) - 15. Dropout2

가우시안 드롭아웃과 몬테카를로 드롭아웃을 알아보자.우선 가우시안 드롭아웃을 살펴보자.기존 드롭아웃은 확률적으로 노드들을 없앤다.: 베르누이 1or0으로 드롭아웃될 확률이 p로 생략Bern(1-p)를 따르는 값 m(0or1)들1 0 0 1 1 1을 이용하여 Wx와 ele
16.고려대학교 딥러닝(오승상교수님) - 16. Regularization

딥러닝에서 regularization은 가중치 규제를 의미한다.네트워크에서 노드 하나하나들은 각 feature를 말하는데 co-adaptation이 증가해 오버피팅이 발생하는 것을 규제하고자 다양한 방법을 사용한다.오버피팅을 방지하고자 weight sum이후 featu
17.고려대학교 딥러닝(오승상교수님) - 17. Batch normalization
오늘은 Batch Normalization을 알아보자!이는 Internal Covariate Shift를 방지하고 나온 기법이다.공변량 변화(분포가 바뀌는 것)로 input과 output layer 뿐 아니라 모든 layer에서 발현한다.weighted sum을 하고
18.고려대학교 딥러닝(오승상교수님) - 18. Weight initialization

네트워크의 파라미터들을 초기에는 random으로 할당했다.하지만 성능이 안 좋았기에 Xavier, He initialization이 등장하며 성능이 개선되었다.Weight initialization은 Cost가 minimum으로 가게 되는 방향을 수월하게 진행시킬 수
19.고려대학교 딥러닝(오승상교수님) - 19. CNN Introduction

이제 CNN에 대해 배워보자!CNN 특징 1 : shared weight을 Convolution layer로 해결이미지는 flatten시키면 input dim이 너무 크기에, conv로 weight sharing을 통해 작은 수의 weight를 사용하여 해결한다.CNN
20.고려대학교 딥러닝(오승상교수님) - 20. CNN Convolution 1
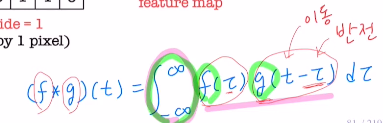
Conv layer는 filter들을 사용하여 픽셀들 간의 관계를 이해하며 feature extraction을 시행한다. (kernel size(하이퍼파라미터)가 클 수록 광범위하게 본다)filter 안의 값을 weight로 보아 이를 update한다.(이 filter
21.고려대학교 딥러닝(오승상교수님) - 20. CNN Convolution 1
Conv layer는 filter들을 사용하여 픽셀들 간의 관계를 이해하며 feature extraction을 시행한다. (kernel size(하이퍼파라미터)가 클 수록 광범위하게 본다)filter 안의 값을 weight로 보아 이를 update한다.(이 filter
22.고려대학교 딥러닝(오승상교수님) - 21. CNN Convolution 2
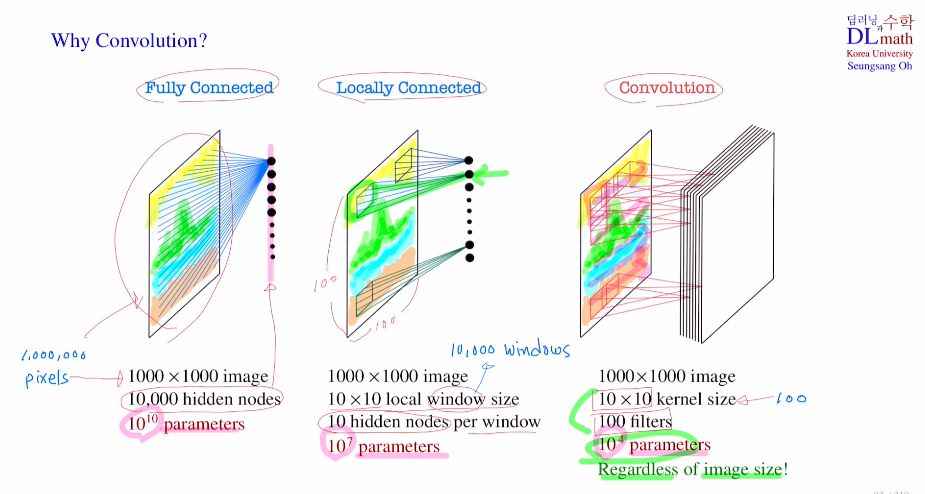
기존의 MLP방식은 여러 문제가 있었다.1) dim이 너무 크기에 노드 수도 많아지기에 파라미터가 너무 많다.(locally connect를 해도 파라미터가 너무 많다) -> Conv layer로 filter를 사용하여 weight sharing으로 파라미터 수를 줄였
23.고려대학교 딥러닝(오승상교수님) - 22. CNN Max pooling

이번 포스트는 Max pooling에 관하여 알아보자! CNN에서 Max pooling의 역할은 굉장히 중요한데 dimension reduction(down sampling) 과 translation invariance 를 진행하기 때문이다.Max pooling lay
24.고려대학교 딥러닝(오승상교수님) - 23. CNN GoogLeNet Inception-v4
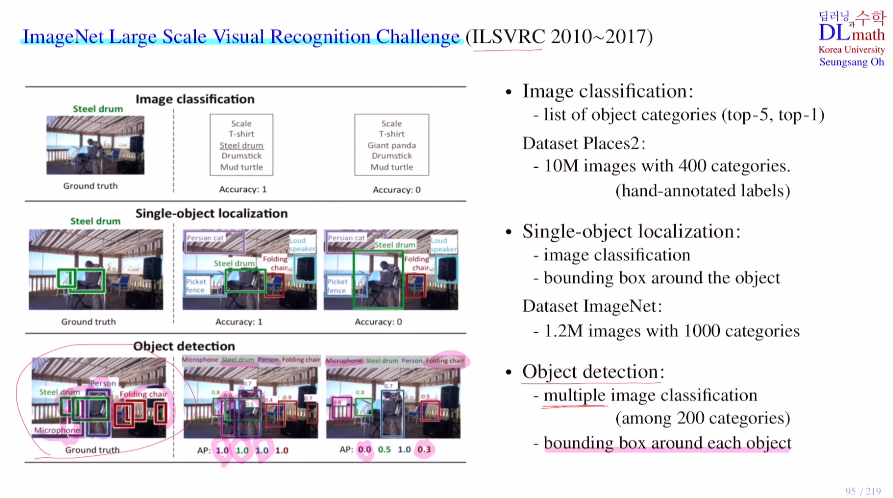
Image Net의 Large Scale Visual Recognition Challenge (ILSVRC) 라는 시합이 있다.우선 이 대회를 소개하자면 세 가지 track이 있는데 ①Image classificationPlace2 data set : 천만장 400종류
25.고려대학교 딥러닝(오승상교수님) - 24. CNN ResNet SENet
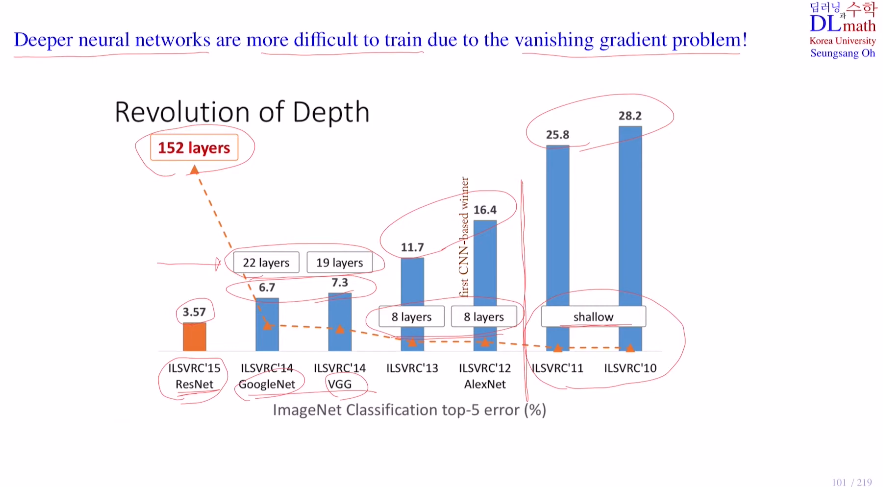
오늘은 ResNet SENet에 대해 알아보자!GoogleNet과 VGG의 모델은 역전파 진행 시 기울기 소실 문제로 인해 layer층을 깊게 쌓을 수 없었다. 이 문제를 해결한다면 더욱 깊은 층을 쌓아 좋은 모델을 만들 수 있을 것이다. 이를 ResNet이 resid
26.고려대학교 딥러닝(오승상교수님) - 25. CNN Convolutions and Dropout
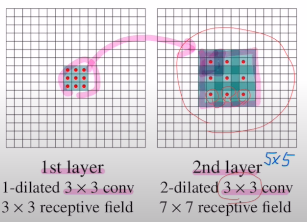
변형된 convolution과 conv에 쓰이는 dropout에 대해 알아보자!첫 번째로 알아볼 convolution은 Dilated Convolution이다.정해진 kernel size만큼 sliding하는 것이 아닌, 인위적으로 면적을 넓히는 방식이다. Q. 이것이
27.고려대학교 딥러닝(오승상교수님) - 26. CNN Transposed convolution U-Net
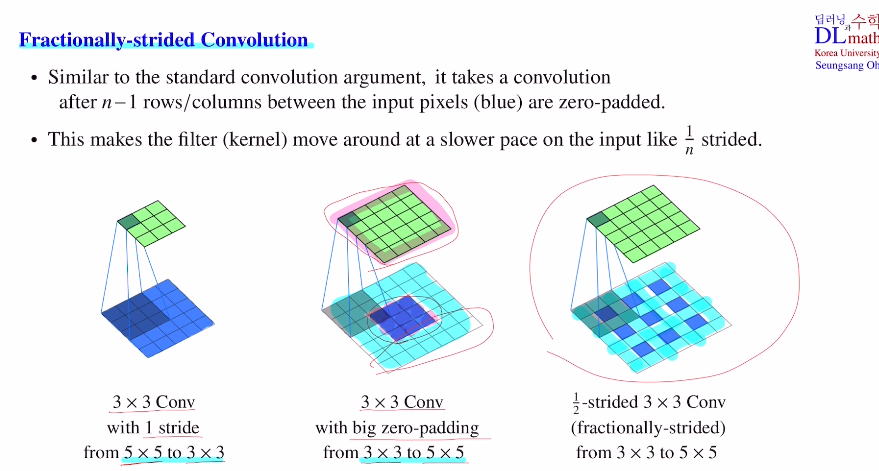
이번에는 기존까지 배운 down sampling과는 반대로 up sampling에 대해 알아보고, U-Net에 대해 알아보자! U-Net: Convolutional Networks for Biomedical Image Segmentation - 논문 리뷰 를 참고하면
28.고려대학교 딥러닝(오승상교수님) - 27. RNN RDNN vs RNN
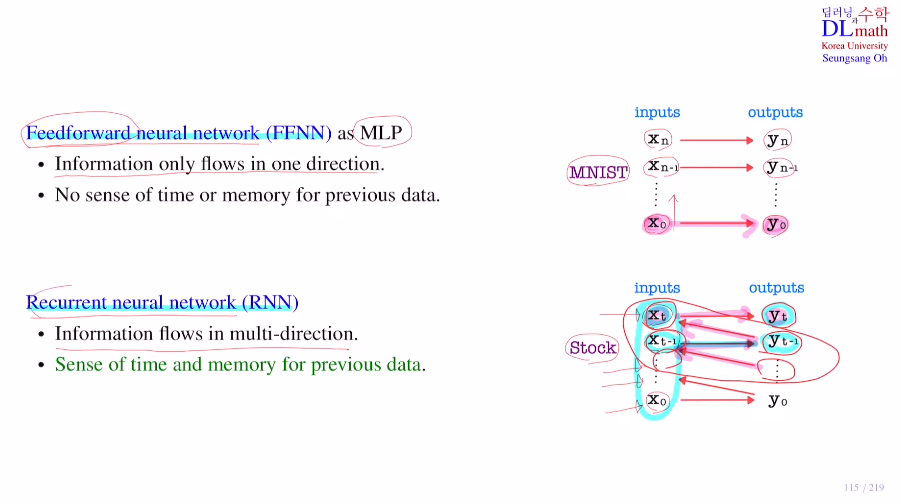
이제부터는 RNN과 관련하여 알아보자!
29.고려대학교 딥러닝(오승상교수님) - 28. RNN Backpropagation through time
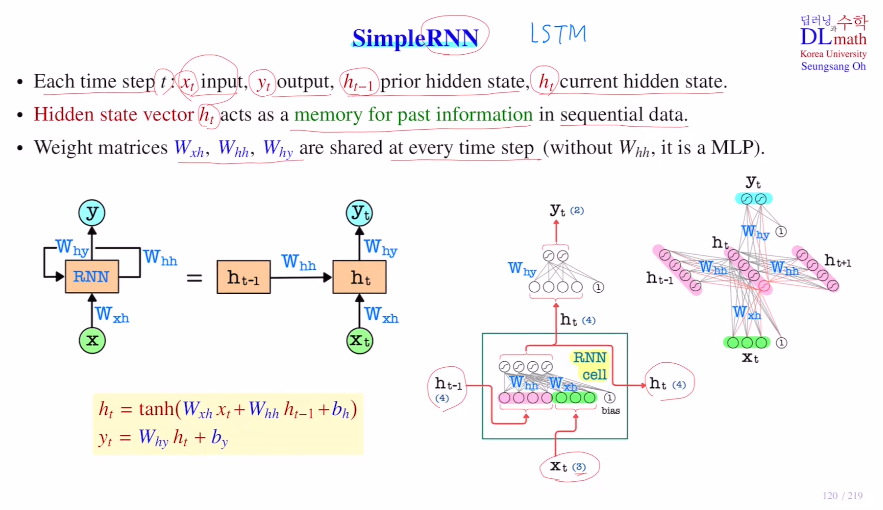
이번 포스트에서는 RNN에서 weight를 업데이트 하는 방식인 backpropagation through time이라는 BPTT에 대해 알아보자.Simple RNN매 입력 time step t에 대해 아래와 같이 표시한다. RNN에서 학습해야 할 파라미터는 Wxh,
30.고려대학교 딥러닝(오승상교수님) - 29. RNN Truncated BPTT
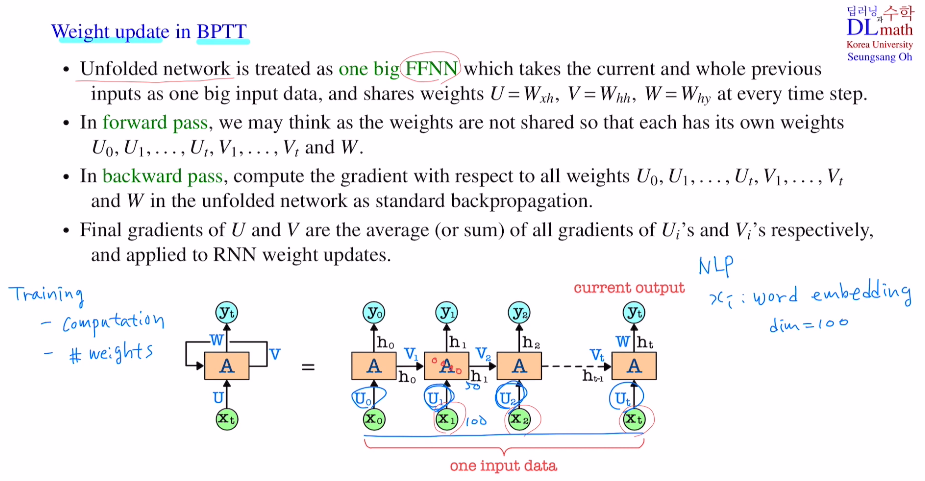
이전 포스트의 내용을 리뷰하자면 에를 들어 단어 xi들을 word embedding(dim=100)을 통해 변경했다고 가정하자. 이들은 각 layer마다 들어오게 될텐데, layer이 노드수가 50이라고 하면 5000개의 파라미터가 필요하게 된다. 시퀀스의 길이가 10
31.고려대학교 딥러닝(오승상교수님) - 30. RNN LSTM
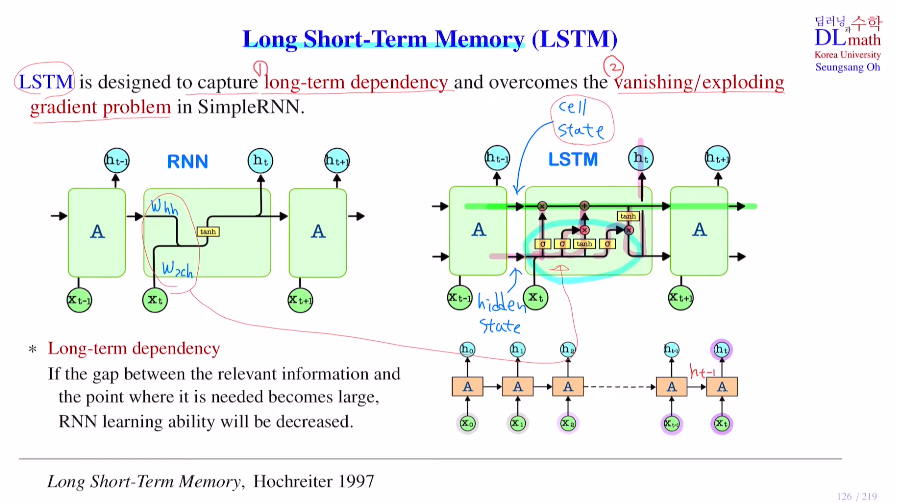
이번 포스터는 RNN의 대표적인 모델 LSTM을 알아보자.장기기억과 단기기억을 이용하는 LSTM: Long Short-Term Memory로 long-term dependency문제와 vanishing/exploding gradient 문제를 해결하기 위해 만들어졌다.
32.고려대학교 딥러닝(오승상교수님) - 31. RNN GRU Dropout
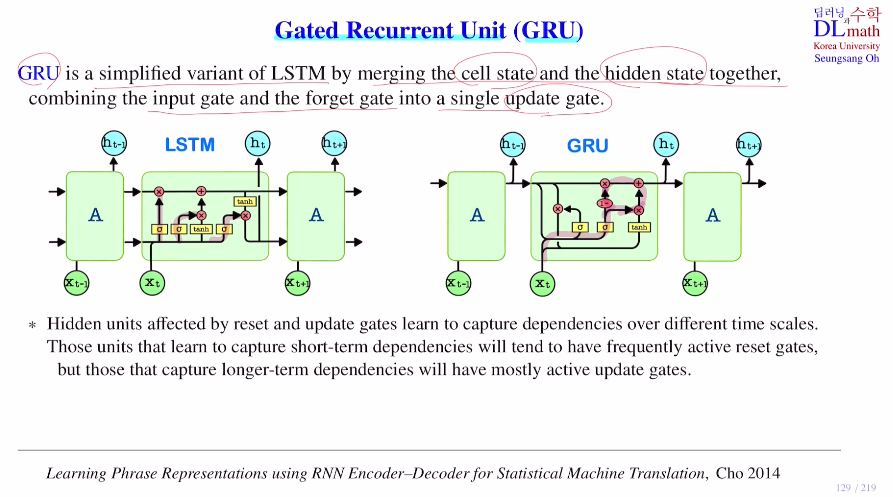
저번 포스터에서 알아본 LSTM에서 단순화 시킨 GRU에 대해 알아보자! 큰 차이점은 LSTM에서는 hidden state와 cell state가 존재하는데 GRU는 hidden state만 존재한다는 점이다. 여기서는 cell state과 hidden state를
33.고려대학교 딥러닝(오승상교수님) - 32. Visual Attention
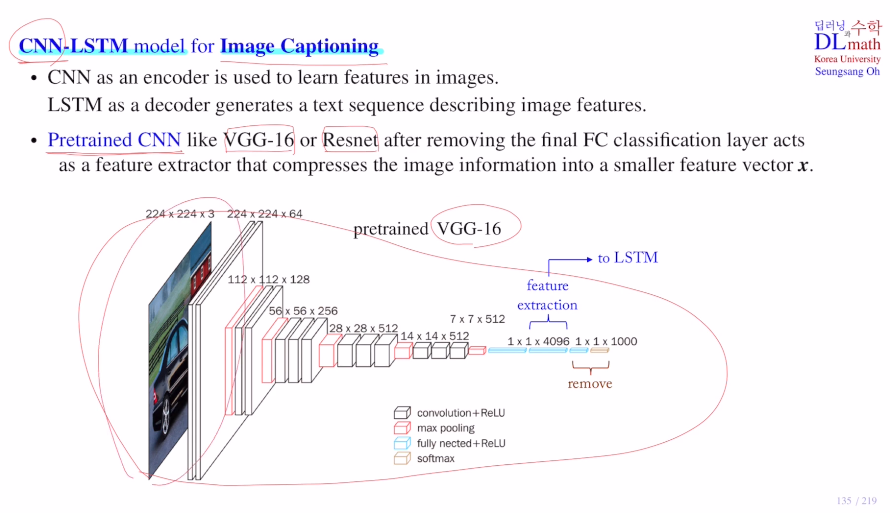
이번 포스터부터는 Attention에 대해 알아보자!이번 포스터는 이미지에 Attention을 적용한 Visual Attention을 알아보자.Image Captioning은 input으로 어떤 이미지가 들어오면 이 이미지에서 중요한 context를 찾아내어 문장으로
34.고려대학교 딥러닝(오승상교수님) - 33. Attention LSTM
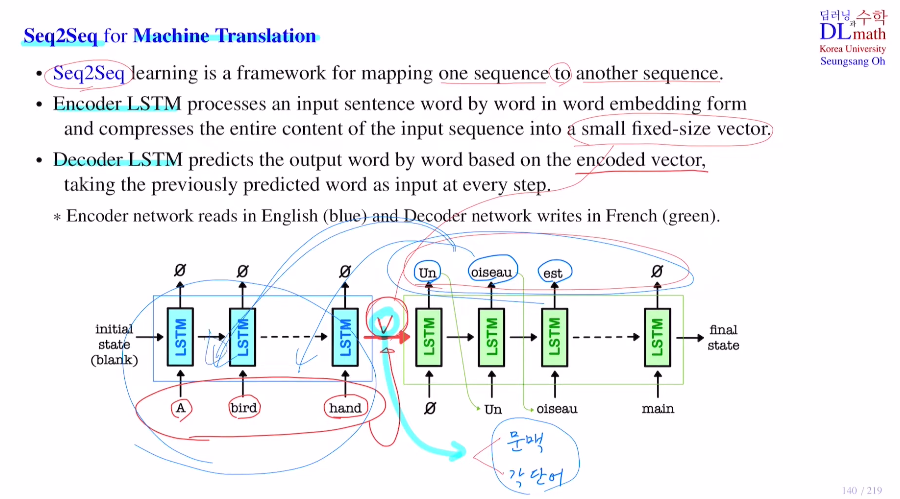
지난 포스터에서는 이미지를 다루는 Visual Attention을 알아보았다면, 이번에는 기계번역을 위한 Attention LSTM을 알아보자! 우선 Seq2Seq를 알아보자.하나의 Seq에서 또 다른 Seq로 보내는 framework이다.하나의 문장을 이해(인코더 L
35.고려대학교 딥러닝(오승상교수님) - 34. Auto-Encoder 1
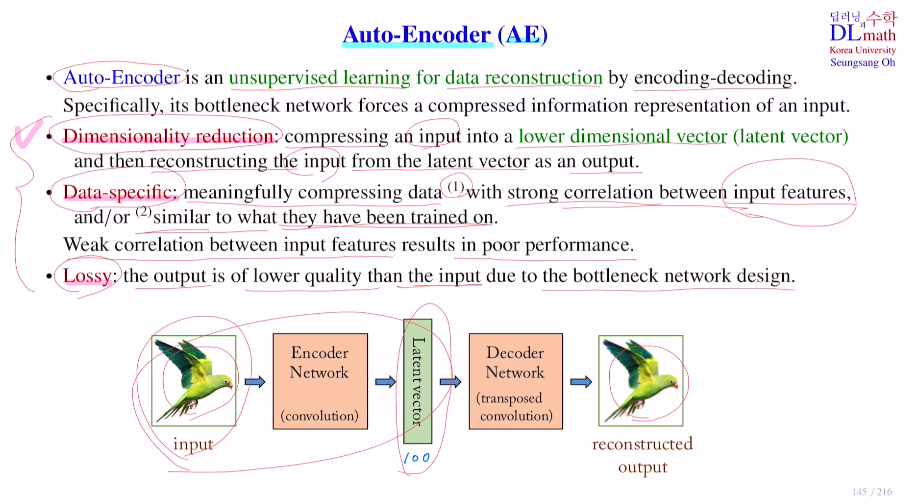
Auto-Encoder는 AE라고 불리며 AE의 세 가지 특징이 있다.우선 unsupervised learning이고, data reconstruction 구조를 갖고 마지막으로 encoding-decoding구조를 가진다는 것이다.AE는 비지도학습으로 label이 없
36.고려대학교 딥러닝(오승상교수님) - 35. Auto-Encoder 2
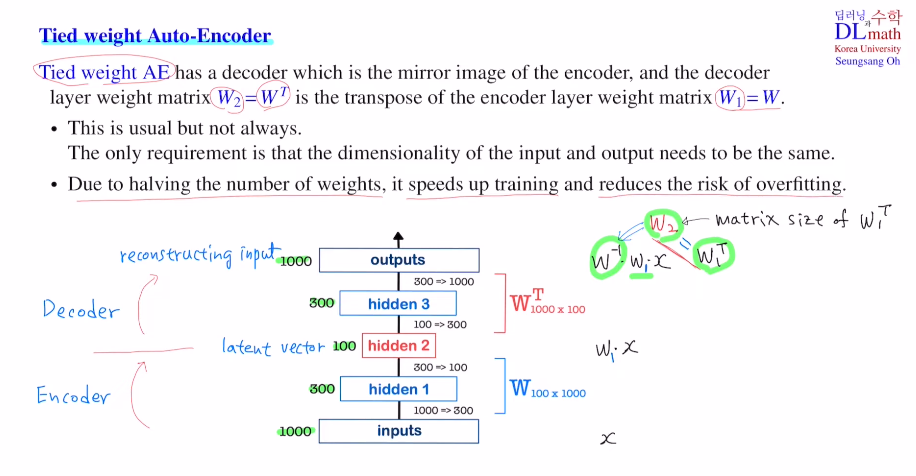
이전 포스터에서는 AE에 대해 배웠다면, 이번에는 이 AE를 이용한 다양한 모델들을 알아보자!우선 Tied weight Auto-Encoder이다.가운데 hidden layer가 latent vector가 된다.non-linearity를 고려하지 않는다고 가정하면 ip
37.고려대학교 딥러닝(오승상교수님) - 36. Variational AE 1
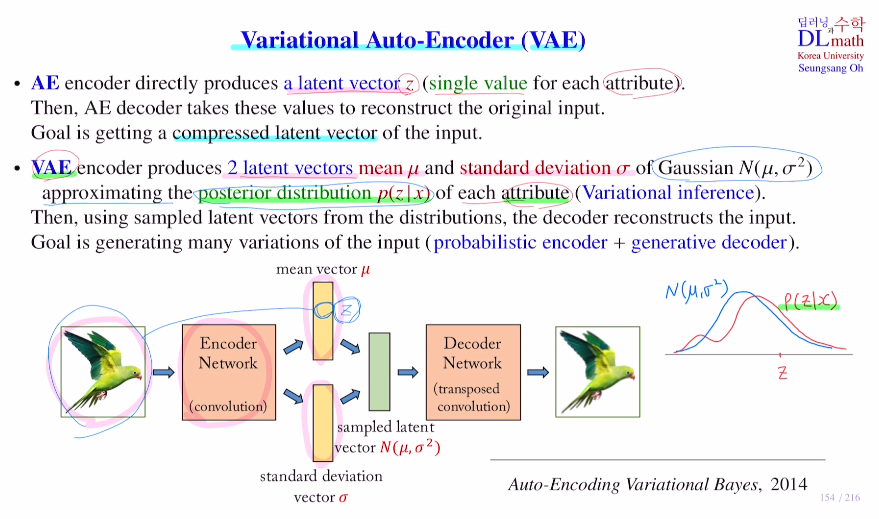
이번 포스터에서는 Variational Auto-Encoder : VAE를 알아보자!VAE : Auto-Encoding Variational Bayes - 논문 리뷰를 참고하면 좋을 것 같다.우선 AE의 목적은 output을 만들어 내는 것이 아니라, output을 만
38.고려대학교 딥러닝(오승상교수님) - 37. Variational AE 2
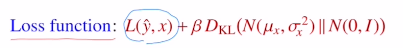
VAE는 input image와 비슷해지게 Reconstruction term과 샘플링 하기 위한 정규분포가 표준정규분포와 유사하게 만드는 Regularization term이 있다.이번 포스터에서는 Reconstruction term에서의 Reparameterizat
39.고려대학교 딥러닝(오승상교수님) - 38. GAN architecture 1
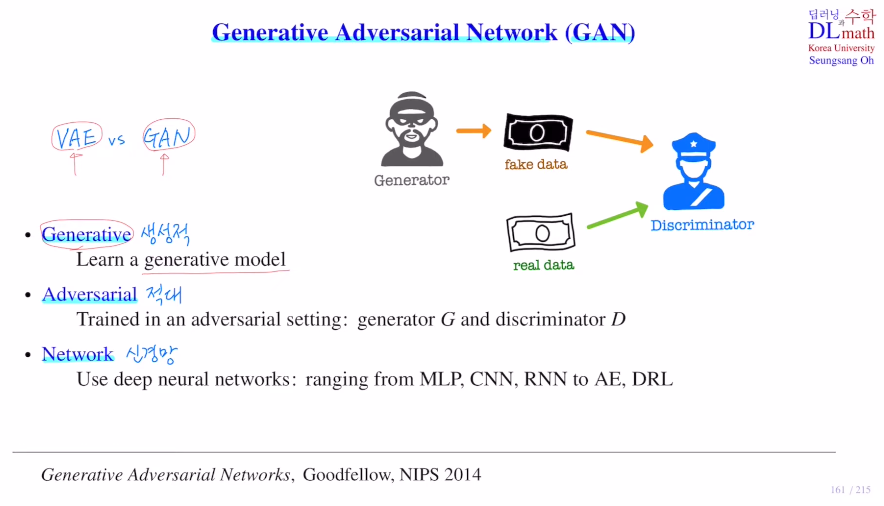
VAE를 마치고 이제부터는 GAN을 알아보자!GAN은 Generative Adversarial Network로 생성적 적대 신경망 이다. (비지도 학습)GAN : Generative Adversarial Nets - 논문 리뷰을 참고하면 좋을 것 같다.VAE의 목적은
40.고려대학교 딥러닝(오승상교수님) - 39. GAN architecture 2
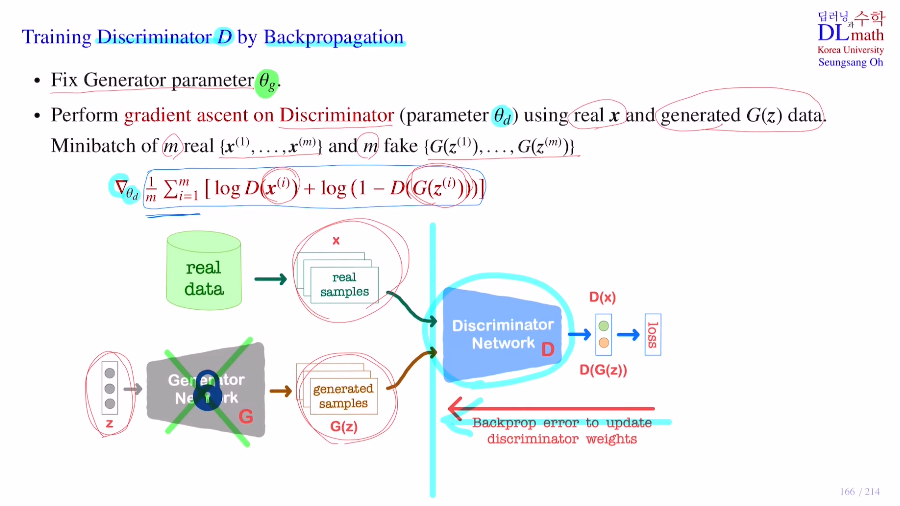
저번 포스터에서 GAN의 구조와 어떻게 학습할지, 최종적으로 내쉬 균형에 의해 D=1/2이 되는 것 등을 알아보았다.이번 포스터에서 구체적으로 수식과 함께 알아보자!우선 Discriminator를 학습하는 것을 확인해보자.생성자는 고정시켜놓고 학습하지 않는다.gradi
41.고려대학교 딥러닝(오승상교수님) - 40. GAN difficulty

GAN의 장점과 단점에 대해 살펴보자!장점GAN의 장점은 비지도학습이라는 점과 GAN이 만들어 내는 이미지가 high quality image라는 것이다. 우리가 알아보았던 GAN, AE, VAE 들은 대표적인 비지도 학습이었다. 또한 GAN은 대표적인 generaiv
42.고려대학교 딥러닝(오승상교수님) - 41. Conditional GAN

이전 포스터에서 DCGAN에 대해 알아본 것과 같이, 이번에도 다양한 GAN의 변형들을 알아보자.우선 Progressive growing GAN : PGGAN 이다.이 PGGAN은 이미지의 선명도를 올리게 한 모델이다. 아래는 PGGAN을 통해 만든 사람 얼굴이며 상당
43.고려대학교 딥러닝(오승상교수님) - 42. Semi-supervised GAN
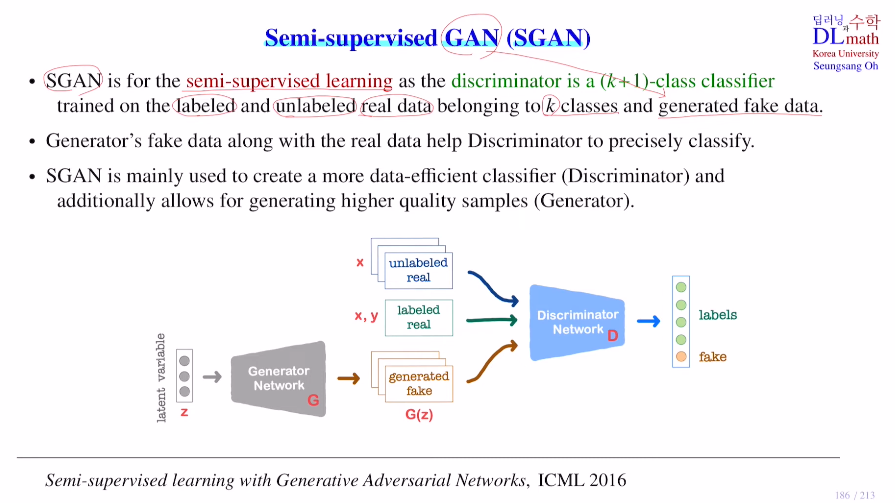
GAN에서의 semi-supervised learning은 real data가 일부는 라벨을 갖고 있고, 일부는 갖지 않은 것이다. 여기서는 GAN을 사용하기에 fake data에 대한 것들도 있기에 조금 더 복잡한 구조를 갖는다.우선 semi-supervised le
44.고려대학교 딥러닝(오승상교수님) - 43. Wasserstein GAN 1
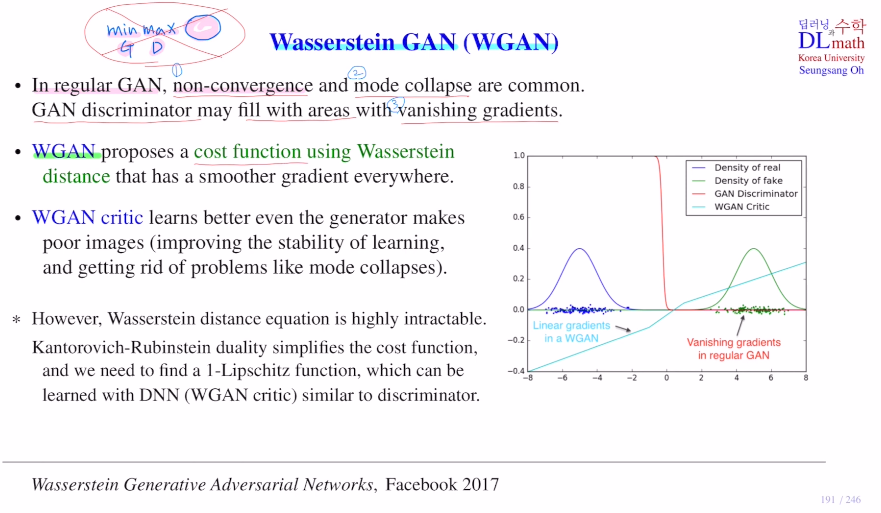
이번 포스터는 Wasserstein GAN : WGAN을 알아보자!이 WGAN은 Wassestein distance를 이용한 cost ft을 활용하는 것이다.우선 기존의 GAN은 학습할 때, non-convergence(minimax로 인해), mode collapse
45.고려대학교 딥러닝(오승상교수님) - 44. Wasserstein GAN 2

이전 포스터에서 Wasserstein distance를 사용한 cost ft을 이용하여 기존 GAN의 단점들을 보완할 수 있었다. 이를 통해 smooth하게(conti&diff) 바꿔주었다.또한 WGAN critic을 통해 vanishing gradient문제를 해결했