데이터 분할
1) shuffle data
2)
① Training set / Test set split 0.7 0.3 분리
② Training set / validation set / Test set 0.6 0.2 0.2 로 분리
-> val set을 통해 모델을 선정 및 하이퍼 파라미터 지정
③ k-fold cross vatidation : k개의 집합으로 나누어 순서대로 한 개를 test set으로 사용하여 학습
데이터가 너무 적을 땐?
=> data augmentation을 통해 새로 데이터를 증강 시킨다.
여기서 중요한 점은 data augmentation을 한 데이터는 test set으로 쓰이면 안 된다! 이미 비슷한 이미지들을 학습했기에 당연히 성능이 좋을 수 밖에 없기 때문이다.
그렇기에 data augmentation를 하고 싶다면, 데이터증강을 하기 전에 미리 test set을 빼 놓고 data augmentation을 진행해야 한다.

Hyperparameter
사람이 지정해줘야 하는 것으로, hidden layer수, node수, output수, epoch수, batch size, 어떤 활성화함수 사용 등 모두 적합하게 잘 사용해야 한다.

Bias-Variance Tradeoff
Bias-Variance problem : 이 편향과 분산이 작을 수록 좋다. 둘 다 줄이는 방향으로 학습하고 싶지만 동시에 줄이는 방식이 서로 상충된다. 그렇기에 적정 선이 존재하고 이를 찾는 것이 문제이다.
-
Bias : output들의 평균값과 실제 값과의 차이, 비슷해야 학습이 잘 된 것
-> 편향이 큰 경우는 underfitting에서 일어난다. training data에 대해 학습이 잘 되지 않아 어설프다. training error, test error 모두 크게 나온다. -
Variance : 예측할 때 마다 변동이 너무 크다. 오버피팅이 되어 기존과 다른 새로운 데이터가 들어오면 제대로 예측하지 못하는 것이다. training data 에 너무 집중해서 일반화되지 않았다. training error는 적지만 test erorr는 높다.
따라서 이 둘 사이의 bias도 variance도 적절히 있지만 성능이 좋은 지점을 잘 찾아야 한다.
Overfitting
training data를 너무 자세히 보거나 노이즈들도 자세히 보게 되어 오버피팅이 일어난다.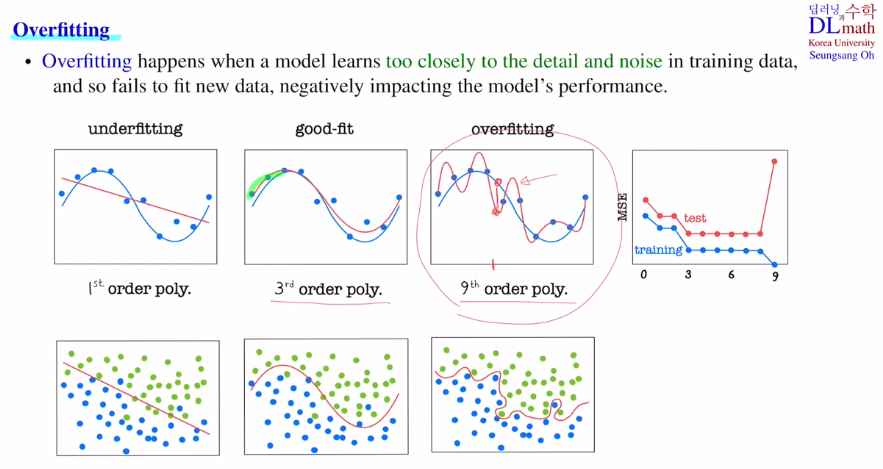
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=2vi6HGZ0Cm4
