
딥러닝에서 regularization은 가중치 규제를 의미한다.
네트워크에서 노드 하나하나들은 각 feature를 말하는데 co-adaptation이 증가해 오버피팅이 발생하는 것을 규제하고자 다양한 방법을 사용한다.
오버피팅을 방지하고자 weight sum이후 feature에 들어오는 값들을 약화시킬 필요가 있다. 이것을 약화시킨다는 말은 weight 값들을 낮춰준다는 것이고(simple model) 이를 regulization이라고 한다.
Q. 그렇다면 weight 값이 커짐을 방지하기 위한 방법들은 무엇이 있을까?
우선 모두 낮추는 것이 아니라 작은 것들은 그대로 두고, 큰 것들은 규제를 가해야 한다. 기본적으로 최종 목적이 cost를 줄이는 방향으로 학습을 진행하는 것이기에, cost ft내부에 가중치 규제를 위한 term을 더해준다.
대표적으로 L1, L2 regularization이 있다.
앞 부분은 기존 cost ft과 동일하지만 뒤에 추가가 되었는데 이를 통해 단순히 cost값을 줄이는 것 뿐 아니라 weight값도 줄이는 방향으로 학습이 진행되게 된다.
(람다는 하이퍼 파라미터)
릿지에서 파라미터 업데이트를 할 때, ①가중치가 커질수록 weight decay로 낮춰주고, ②계속 1보다 조금 작은 값을 곱해주며 이전의 가중치들은 더욱 작아지게, 최근 가중치는 크게 반영할 수 있게 된다.

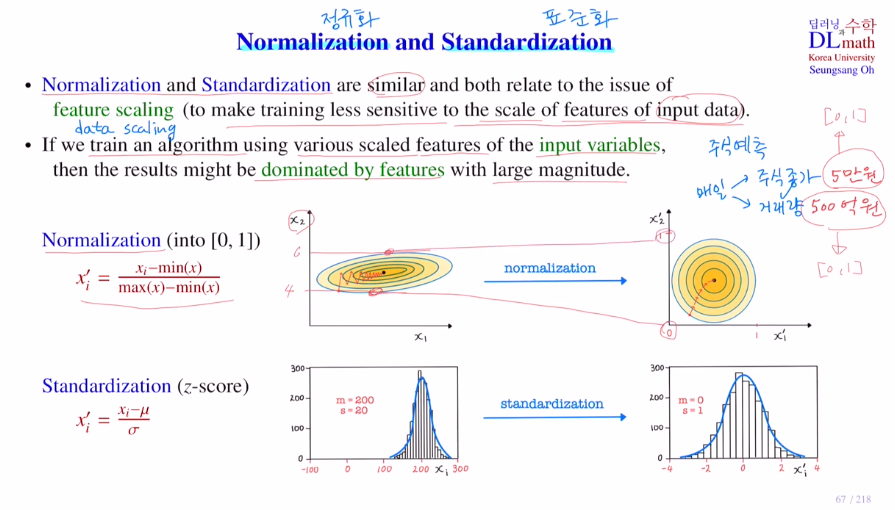
feature scaling
이제 Normalization 정규화와 Standardization 표준화를 알아보자.
이 둘은 앞처럼 weight를 조절하는 것이 아니라 input data에 대해 조절하는 것이다. 용도는 매우 비슷한데 너무 값이 큰 feature들에 대해 이들을 조절하는 것이다.
ex) 예를 들어 faeture의 값들이 하나는 주식 종가로 50,000 정도이고 하나는 거래량으로 5,000,000,000 정도라고 할 때, 컴퓨터는 당연히 큰 값을 중요하게 생각하여 weight가 거래량에 집중되어 값이 변경된다. 이를 방지하기 위해 정규화 및 표준화를 통해 값을 적절히 조절해주고 학습 및 예측을 진행하는 것이다.
중요한 점은 training에서 사용한 scaler를 test에서 똑같이 사용해야 한다!
Normalization은 모든 값을 0에서 1사이로 바꿔준다. 정규화를 진행하기 전에는 cost등고선이 얇아 gradient 값이 수직으로 왔다갔다 하지만, 정규화를 통해 효율적으로 minimum으로 이동할 수 있게 된다.
Standardization는 평균이 0이고 편차가 1인 표준 정규 분포로 바꾸는 것이다. 이는 특정한 vatiable에 쏠리는 현상을 막아주게 된다.
Q. 그렇다면 무엇을 사용할까?
각자의 장단점이 있다.
표준화는 평균과 분산을 구해야 하기에 계산이 조금 더 어렵다.
하지만 만약 데이터셋에 이상치가 있다면?! 정규화를 진행할 때 min값이 너무 작거나 max값이 너무 커서 효율적인 분포가 이루어지지 않게 된다. 이럴 땐 outlier에 영향을 잘 받지 않는 표준화가 좋을 것이다.
따라서 상황에 맞게 적절한 feature scaling을 진행해야 한다.
고려대학교 오승상 교수님 딥러닝 강의 : youtube.com/watch?v=pcl6w5f2Y8M&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=16
