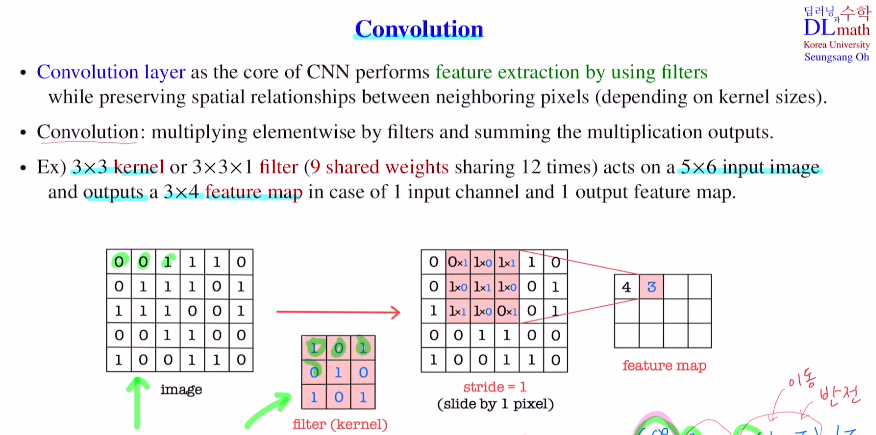
Conv layer는 filter들을 사용하여 픽셀들 간의 관계를 이해하며 feature extraction을 시행한다. (kernel size(하이퍼파라미터)가 클 수록 광범위하게 본다)
filter 안의 값을 weight로 보아 이를 update한다.(이 filter를 이용한 weighted sum)
아래는 9개의 weight와 1개의 bias를 가지고 12번 weighted sum : 주변 이미지들과 합해서 함축한다.
여기서 중요한 장점은 weight가 모두 같다! weight sharing하기에 큰 장점이다.
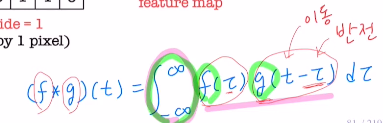
수학에서 말하는 convolution과 비슷하지만 다르다. 그냥 두 함수를 곱하고 sum을 한다는 의미에서 이름을 따온 것 같다.
중요한 하이퍼 파라미터 2개가 있다!
kernel size와 filter의 개수. 이 둘을 통해 줄이고 개수를 늘리며 이미지특징을 추출해간다. Conv2D(64, (3,3), ...)
++ 여기서 제로패딩을 사용하면 사이즈가 줄어들지 않는다.
각 채널에 사용되는 kernel은 모두 다르다!
: 만약 같다면 채널들 값을 더하고 kenel을 거치는 것과 같다. 그렇다면 굳이 채널을 만들 필요가 없는 것이다. 그럼 feature map이 하나밖에 없게 되는데 이러면 우리의 목적인 각 feature map들을 이용해 종합적으로 결론을 내리고 싶다는 것을 실현할 수가 없다..! 따라서 각 채널에 사용되는 kernel들이 다 다른 종류의 weight값을 갖고 있는 것이 좋다.
=> 파라미터는 3x3이 3개 & 필터개수 6개 , 5x5 6개 & 필터개수 10개
-> (27+1(bias)) 6 = 168, (150+1) 10 = 1510
기존 MLP에 비해 굉장히 적은 수이다! 또한 input size에 의존하지 않고 커널사이즈와 필터 수에 의존할 수 있게 되는 것이다.
Max pooling은 채널수가 바뀌지 않는다.(+파라미터가 사용되지 않는다.)
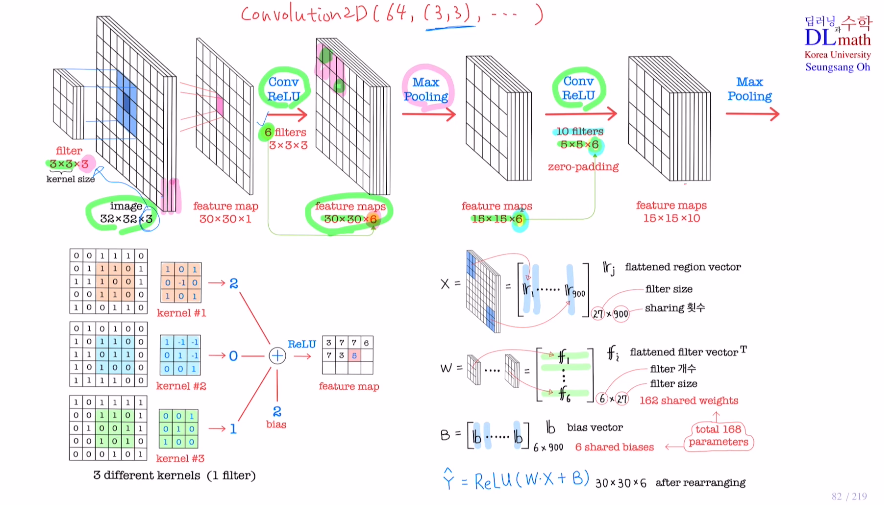
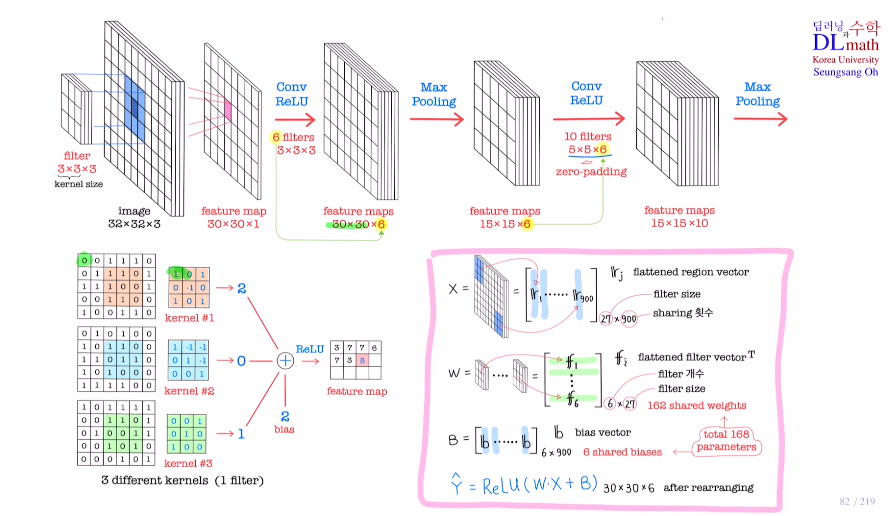
계산
kernel size에 맞게 3x3 3개로 각 input image에서 9개, 9개, 9개(rgb 채널3)로 flatten하여 27x1 하나가 나온다. 이를 r1이라고 하겠다.
그렇게 되면 input image X = [r1 ... r900] : 27x900 (900은 30x30)
kernel을 flatten하고 Transpose하면 9 9 9니까 1x27
필터 개수 6개라고 했으므로 W = 6x27이 된다.
Bias는 필터 개수 6개에 최종 30x30이므로 6x900
따라서 Yhat = Relu(WㆍX+B)
고려대학교 오승상 교수님 딥러닝 : https://www.youtube.com/watch?v=NwdEQ9LuyKE&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=20
