이제 CNN에 대해 배워보자!
CNN 특징 1 : shared weight을 Convolution layer로 해결
이미지는 flatten시키면 input dim이 너무 크기에, conv로 weight sharing을 통해 작은 수의 weight를 사용하여 해결한다.CNN 특징 2 : translation invariance을 Max pooling으로 해결
translation invariance : 컴퓨터는 동일한 객체여도 위치가 바뀌면 혹은 조금만 움직여도 다른 객체로 인식한다. 이 문제를 Max pooling으로 해결한다.
single object
Classification / Calssification+Localizaiton
multiple object
Object Detection / Segmentation
또한 LSTM과 결합하여 이미지를 보고 text로 설명

본격적으로 CNN을 배우기 전, 이전에 배웠던 Multi layer perceptron MLP를 사용한다면 어떤 문제가 있을까?
1) 이미지는 input할 때 flatten시켜야 하기는데, 이미지가 너무 커지게 되면 vector size가 너무 커지게 된다. 이렇게 되면 학습해야할 파라미터가 너무 많아지게 된다.
2) 특정한 픽셀이 있을 때, 주변에 몇 개의 픽셀들이 존재한다. 이미지를 확인할 때 픽셀 주변의 픽셀들과 합쳐져서 확인하게 된다. 즉, 독립적으로 하나만 보는 것이 아닌 주변과 합쳐서 봐야 한다. 하지만 flatten을 시켜 weighted sum을 하면 픽셀 간 공간적 정보를 많이 잃어버리게 되는 것이다.
3) 이미지의 객체가 움직이거나 크기가 변경되는 등 변형이 일어나면 이를 다른 객체로 인식한다. 성능을 올리려면 모든 training이미지를 augmentation을 통해 변형시킨 것들을 학습시켜야 한다. 부담이 너무 크다.
=> 이러한 문제를 conv layer의 filter를 통해 해결한다. 1)이제는 더이상 input image size에 의존하는 것이 아니라, filter에 의존하게 된다. 이렇게 되면 파라미터 수를 조절할 수 있고, 2)주변 픽셀들을 같이 봐서 spatial information lose도 해결 가능하다. 3)세 번째 문제는 Max pooling을 통해 translation invariance 특징을 사용하여 해결한다.

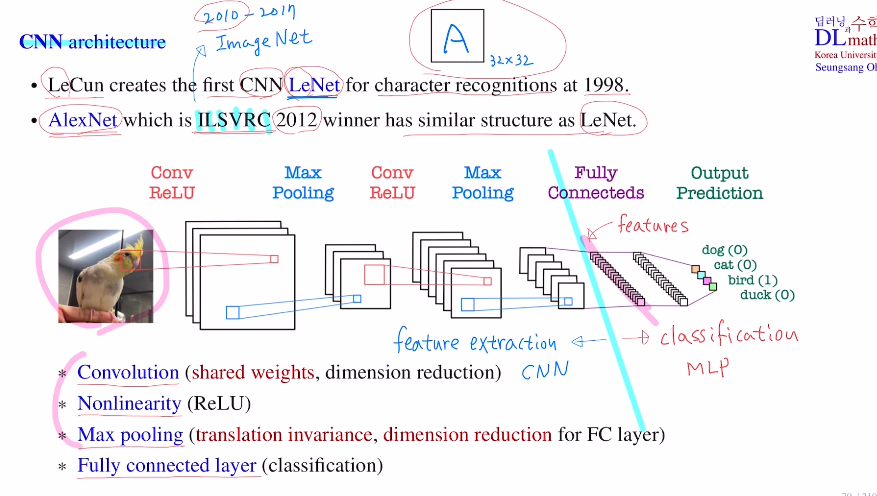
1998 first CNN LeNet을 통해 알파벳(32x32) character recognition을 해결한다.
2012 AlexNet을 통해 이미지넷에서 주관한 챌린지(천만장, 400category:이전에는 머신러닝이 1등)에 참여하여 우수한 성능을 보인다.
CNN 구조 : Convolution(shared weight, dim reduction) , Nonlinearity(Relu), Max pooling(translation invariance, dim reduction) , Fully connected layer (classification)
CNN을 통해 feature extraction (사람이 데이터 전처리를 할 필요가 없다)
: 최대한으로 요약되어 있는 feature를 찾자 (파라미터 수 적다)
MLP를 통해 classification (파라미터 수 많다)
컴퓨터는 각 픽셀별로 숫자로 인식, matrix로 인식
흑백 이미지는 2d matrix로 표시
(0(black)~255(white))
컬러 이미지는 RGB 2d matrix 채널 3개로 표시
(0~255)

고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=DYIgm0Ue4_Y&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=19
