이번 포스트는 Max pooling에 관하여 알아보자!
CNN에서 Max pooling의 역할은 굉장히 중요한데 dimension reduction(down sampling) 과 translation invariance 를 진행하기 때문이다.
Max pooling layer는 learnable 파라미터를 사용하지 않는다. 그렇기에 따로 학습하지 않고 계산만 이루어진다. 주로 (2x2)를 사용하며 2칸씩 이동하기에 stride=2라고 생각하면 된다. 이 필터들을 겹치지 않고 이동하며 가장 큰 값들 만을 뽑아 낸다.
이렇게 Max pooling을 사용하여 dimension을 줄이게 되는데 가장 중요한 정보만을 보낸다는 의미이다. 중요한 점은 각 feature map 별로 따로 따로 적용되는 것이기에 피쳐맵의 개수 즉, 채널 수는 변하지 않는다! 너비 높이 사이즈만 반으로 줄어드는 것이다. 이를 down sampling 효과를 갖는다.
이는 굉장히 중요한데 feature extraction을 하고 FC layer로 들어가기 위해 feature들을 줄여주는(dim을 낮춰주는) 역할을 한다.
두 번째로 중요한 점은 translation invariance로 객체가 움직이거나 할 때, 같은 그림으로 인식할 수 있게 도와준다.
why?
숫자가 옆으로 움직였다고 해도, Max pooling은 최대값만을 가져오기에 기존과 크게 변화가 생기지 않기 때문이다.
그렇기에 기존 수 많은 data augmentation을 한 데이터를 만들고 넣을 필요가 없는 것이다!

마지막 부분인 fully connected layer를 살펴보자!
이는 traditional MLP이며, classification문제면 softmax를 사용하게 된다.
만약 conv layer와 max pooling을 거쳐 4x4x32가 되었다고 가정하자. 이를 바로 사용할 수 없기에 flatten을 통해 512 dim으로 바꿔준다. 초반 input image의 dim에 비해 훨씬 적다!! 이렇게 flatten이후 FC layer를 거쳐 최종 softmax를 통해 classify하는 것이다.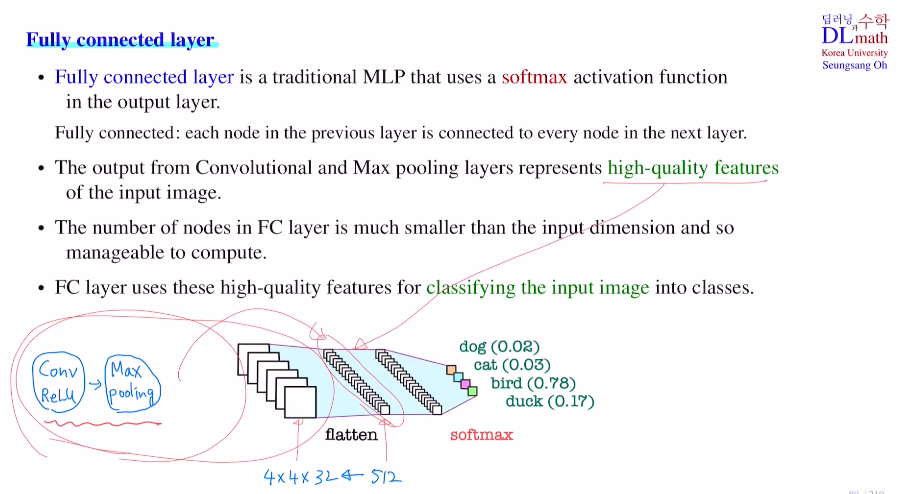
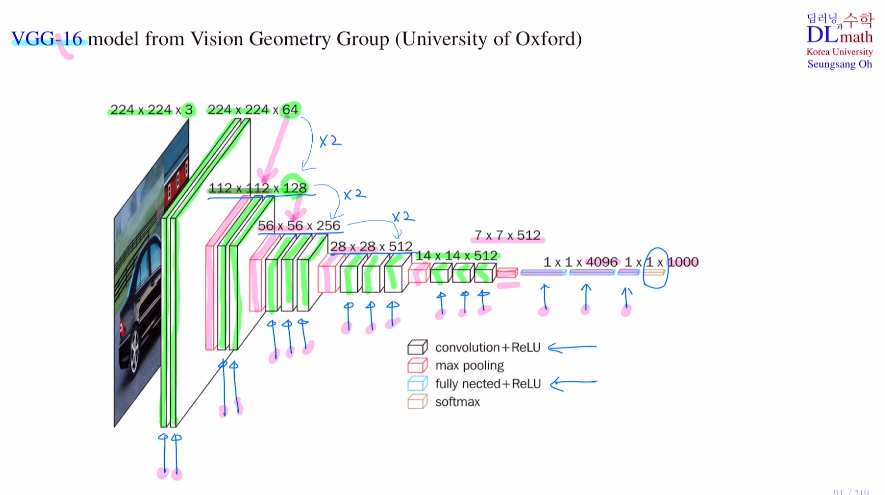
이제 CNN 알고리즘 중 VGG-16모델을 살펴보자.
우선 input image에 제로패딩을 쓰는 conv layer 2개를 통해 224x224x64로 바꾸었다. 그리고 max pooling을 통해 반으로 줄이고 다시 conv layer 2개를 거쳐 112x112x128로 만들었다. 이렇게 conv layer와 max pooling을 반복하며 faeture extraction에서 7x7x512로 만든다.(max pooling을 통해 size가 1/4이 된 것을 conv layer를 통해 채널수를 증가시켜준다.) 이후 이를 flatten시키고 FC layer에 넣어 4096size로 두 번 거친 후 1000가지 클래스이기에 1x1x1000으로 바꿔서 softmax를 통해 classify를 하게 되는 것이다!
이렇게 만든 모델은 학습해야 할 weight가 있는 layer만 따지면 총 16개이므로VGG-16이라는 이름이 붙은 것이다.
CNN도 당연히 backpropagation을 통해 학습하는데 이를 알아보자
0) 하이퍼파라미터인 필터의 개수와 커널의 사이즈를 정해준다
1) Conv filter의 weight와 FC layer의 weight를 초기화시켜준다.
2) mini batch 만큼 가져와 forward pass(conv, maxpool, FC)를 거친 후 softmax로 각 클래스에 대해 확률 값을 구한다.
3) Total cost 계산
4) 역전파로 gradient를 계산한다.(FC, conv-cov는 weight sharing을 했기에 조금 더 복잡하다) 이후 cost를 minimize시키는 방향으로 파라미터를 업데이트 한다.
5) 2~4를 반복하며 weight update를 진행한다.
코드를 짜보자!
# input size = 32x32 with 3 channels 즉, (32, 32, 3)
from keras.models import Sequential
from keras.layers imprt Convolutional2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
n_filter = 36
nb_classes = 10
model = Sequential()
model.add(Convolutional2D(nfilter, (3, 3), padding="same", input_shape = x_train.shape[1:])) # 32x32x36
model.add(Activation('relu'))
mode.add(MaxPooling2D(pool_size=(2, 2))) # 16x16x36
model.add(Dropout(0.25))
model.add(Convolutional2D(2*nfilter, (3, 3), padding="same") # 16x16x72
model.add(Activation('relu'))
mode.add(MaxPooling2D(pool_size=(2, 2))) # 8x8x72
model.add(Dropout(0.25))
model.add(Convolutional2D(4*nfilter, (3, 3)) # 8x8x144
model.add(Activation('relu'))
mode.add(MaxPooling2D(pool_size=(2, 2))) # 4x4x144
model.add(Dropout(0.25))
model.add(Flatten()) # 2024
model.add(Dense(16*nfilter)) # 576
model.add(Activation('relu))
model.add(Dropout(0.5))
model.add(Dense(nb_classes)) # 10
model.add(Activation('softmax'))
마지막으로 Visualizing CNN을 살펴볼 것인데, conv layer를 거칠 수록 filter들이 어떤 역할을 하는지와 이로 인해 만들어지는 feature map들의 값은 어떻게 변화하는지 확인해보자
기본적으로 DNN에서는 layer수가 많아질 수록 훨씬 복잡한 특징을 찾아 문제를 해결한다.
conv layer도 마찬가지로 layer가 깊어질 수록 훨씬 더 복잡한 feature들을 인식하게 된다. 아래 그림을 보면 lower layer, middle layer, high layer가 있다. 이렇게 점점 거칠 수록 각 픽셀들이 이미지의 전체적인 부분 특징을 갖게 되는 것 즉, high quality feature를 갖게 되는 것이다!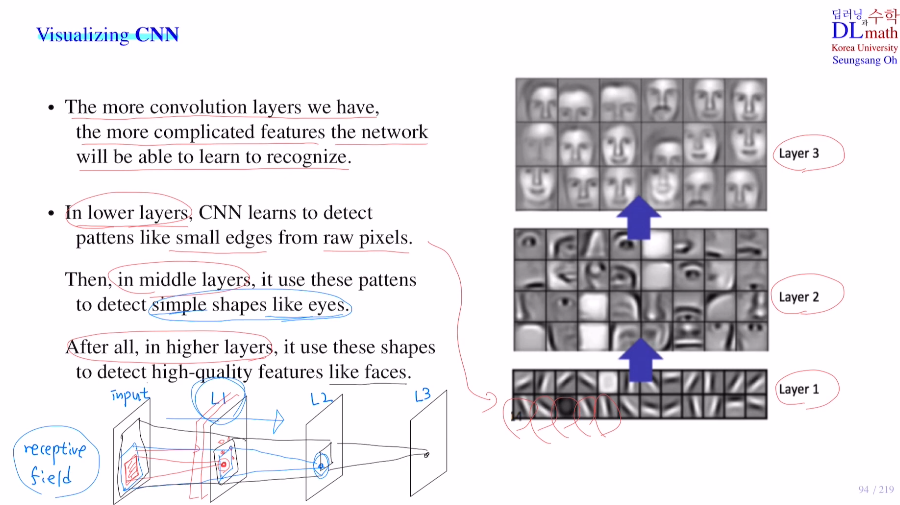
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=iZxoWdvfDoI&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=22
