Image Net의 Large Scale Visual Recognition Challenge (ILSVRC) 라는 시합이 있다.
우선 이 대회를 소개하자면 세 가지 track이 있는데
①Image classification
Place2 data set : 천만장 400종류 - 사람이 모두 라벨링
top5(5가지 후보를 만들어 이 중 정답이 있으면 맞은 것), top1
보통 top5로 기준을 잡는다.
②Single-object localization
ImageNet dataset : 120만개 사진 1000개 카테고리
image classification과 object의 위치를 찾아야 한다.
③Object detection
multi image classicication과 각 bounding box도 찾아야 한다.
으로 구성되어 있다.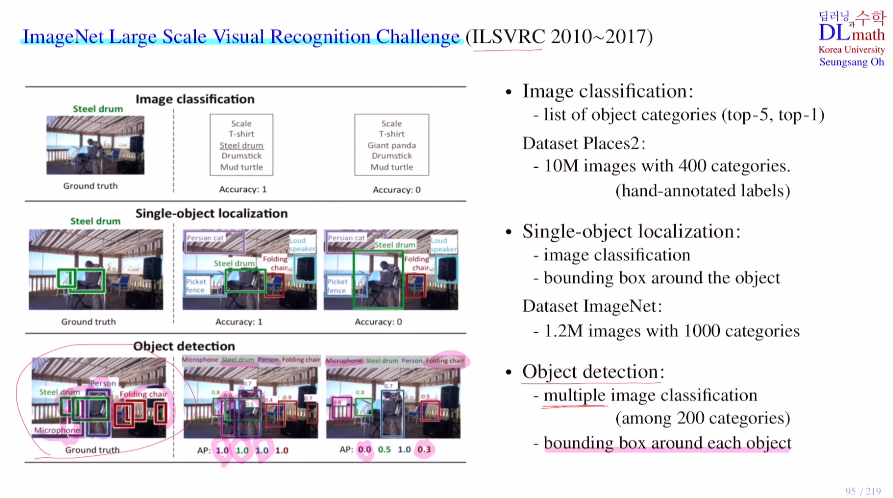
아래는 ILSVRC에서 1등을 했던 모델의 순서를 나타낸 것이다.
top5 error rate가 초반 머신러닝을 사용했을 때는 28%정도가 나왔었다.
이후 AlexNet이 15.3%로 확 줄이고, 이를 기점으로 모두 CNN을 이용하여 성능이 개선된 모델들을 만들어갔다.
GoogLeNet은 Inception 모듈을 사용하여 파라미터 수를 확 줄였고, 당시 2등을 했던 VGG는 모델이 간단하여 사람들이 많이 사용했다. 그리고 residual block을 이용하여 기울기소실을 줄여 layer층을 깊게 쌓을 수 있게 만든 ResNet이 나왔다.(사람의 error-rate이 보통 5%인데 resnet은 이보다 줄였다.)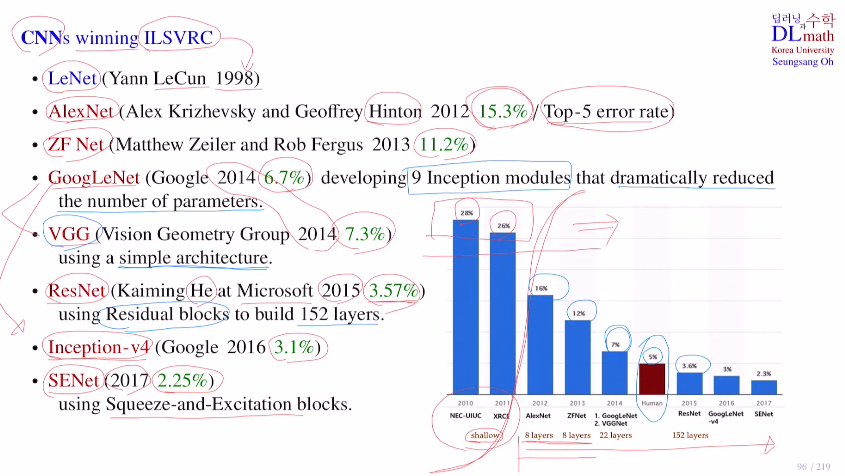
GoogLeNet을 살펴보자. 구글넷은 Inception-v1이라고도 불린다.
(GoogLeNet은 최종 output 이외에도 중간 output이 2개가 있다.)
아래 강아지를 보면 왼쪽은 허스키이고 오른쪽은 에스키모강아지이다. 육안으로 봤을 땐 둘이 굉장히 비슷해 보인다. 구글넷은 이를 정확하게 구분할 수 있다.
layer를 굉장히 깊게 늘리되, 파라미터 숫자는 많지 않게 하는 Inception 모듈을 사용했다. 여기서는 1x1 conv도 사용했는데 이는 나중에 언급해보겠다. Inception모듈을 보면 feature concatenate를 진행한다. 이는 아래를 예를 들어 각기 다른 filter를 사용하여 5개 feature map 짜리 4개를 생성한 후 이를 concat하는 것이다. 총 20개 채널을 갖게 합친 것이다. (중요한 점은 당연히 concat을 위해 size를 같게 해야 한다.)
tensor = n-dim array
1-d tensor = vector
2-d tensor = matrix
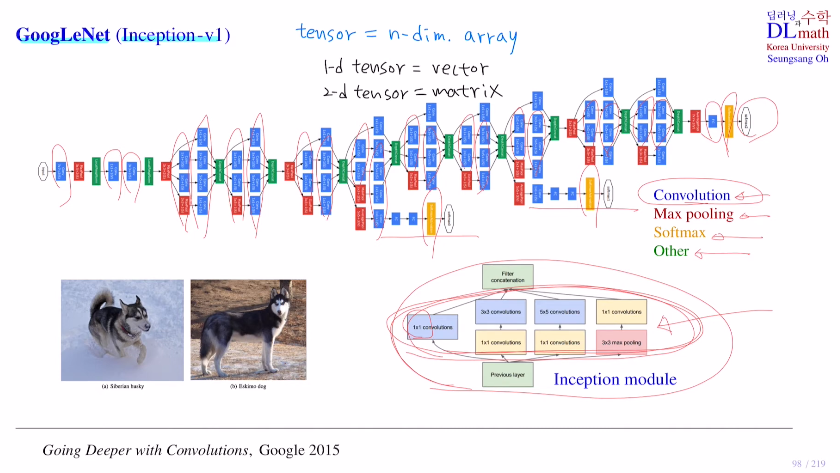
이 Inception 모듈의 성능이 좋은 이유는 수학적인 증명으로 인한 것이 아닌 경험적으로 나온 모듈이다. 따라서 이 구조를 복잡하게 하거나 하는 방안들로 Inception-v4까지 나오며 좋은 성능을 이끌었다.
Inception-v4는 Stem, Reduction과 avarge pooling을 사용했다.
같은 input으로 다양한 conv layer 및 maxpooling을 거치고 다시 concat하는 방식을 반복하고, 마지막에 avarge pooling을 사용하여 flatten을 시키지 않아도 되는 장점이 있다.
또한 1x7 7x1을 반복적으로 사용하며 더 깊게 쌓는 특징도 확인해 볼 수 있다.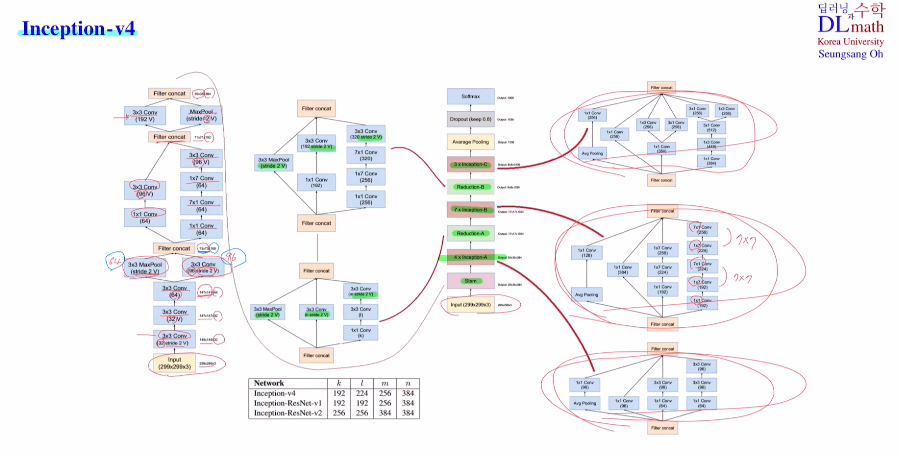
위의 모델에서 1x1 filter를 사용한 것을 볼 수 있다.
그렇다며 이 필터는 왜 사용했는지 알아보자!
크게 세 가지 이유가 있다.
예를 들어 feature map 3개가 있을 때, 1x1 filter를 사용하면 아래와 같이 하나의 feature map이 탄생하게 된다.
이는 한 픽셀에 대해서만 진행하기에, 3x3 filter와 같이 공간적인 부분 정보를 포함하지 않는다. 단순히 앞의 채널에 적당한 weight값만 곱하기에 receptive field효과는 없다. 하지만 위에서 보는 것과 같이 마지막에 activation ft으로 non-linearity를 취해준다. 이를 통해 모델을 좀 더 정교하게 만들 수 있다는 특징이 있다.
두 번째로는 feaure map 단위로 보았을 때 각각을 노드로 생각하고 weight sum을 진행시키는 fully connected 효과를 얻을 수 있다.
세 번째로 많은 것을 변형시키기 않고 단순히 feature map의 개수만 조절하고자 할 때 유용한다. 아래 세 가지 경우를 예시로 보자.
single 3x3 conv는 3x3xFxF로 학습해야 할 파라미터 개수가 나온다.
1x3, 3x1 conv는 1x3xFxF + 3x1xFxF 이다. 앞에 비해 파라미터 개수도 적고 non-linearity도 많다.
Bottleneck은 필터개수 절반만 사용하여 1x1xFx(F/2) + 3x3x(F/2)x(F/2) + 1x1x(F/2)xF 로 구조는 복잡하지만 학습해야 할 파라미터 수가 훨씬 줄고 layer가 깊어 non-lienarity도 더 많다.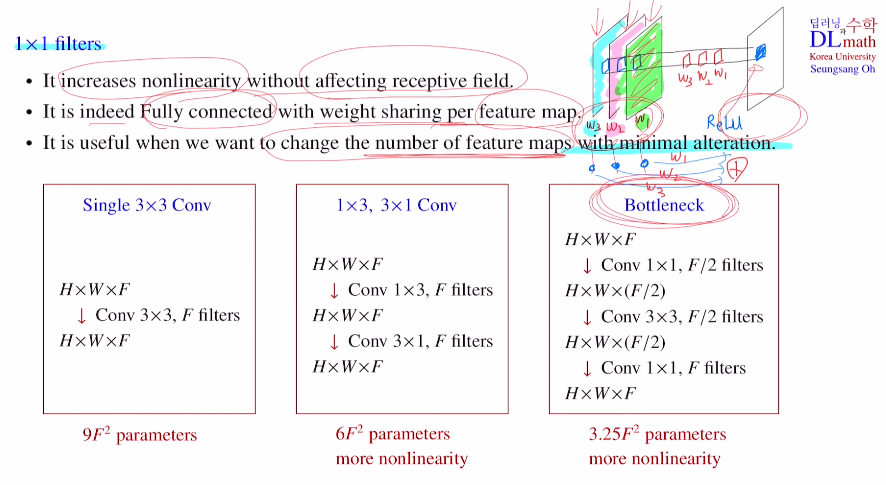
고려대학교 오승상 교수님 딥러닝 강의 : https://www.youtube.com/watch?v=WmrjTfANQ8c&list=PLvbUC2Zh5oJvByu9KL82bswYT2IKf0K1M&index=23
