Pipeline Hazards : Control Hazard
이번에는 Control Hazard에 대해 알아보자.
이를 해결하는 방법은 총 네 가지가 있다.
1) Stall
2) Optimized branch processing
3) Branch prediction
4) Delayed branch
1)의 stall은 앞의 data hazard를 해결하기 위한 방법과 똑같다.
두 번째 방법인 Optimized branch processing은 문제를 해결하는 방법이라기 보다는 손실을 최소화하는 방법이다.
제대로 된 해결책은 뒤에 두 개로
3) Branch prediction 은 branch가 될 지 되지 않을 지 예측을 하여 해결하는 방법이며,
4) Delayed branch 는 data hazard의 소프트웨어 방법의 NOP방법으로 delay를 시켜서 애초에 발생하지 않게 하는 방법이다.
구체적으로 하나씩 살펴보자!
1) Stall
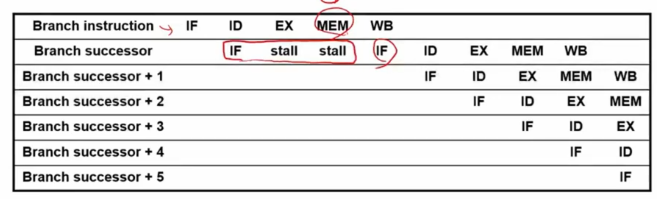
branch에 대한 여부는 MEM까지 가야 rs와 rt를 비교하고 판단을 할 수 있다. 그렇기 때문에 메모리 단에 도착하기 전까지 뒤 따라 오는 명령어들은 stall을 시켜야 한다.
이렇게 stall을 시키고 MEM이 끝난 후에서야 비로소 명령이 진행된다.
당연히 단순히 기다리는 것이기에 해결하긴 해도 3clock이나 낭비하기에 비효율적이다.
2) Optimized branch processing
이 방법은 완벽히 해결하지는 않아도 손실을 최소화한다.
최대한 미리 연산할 수 있는 것들은 미리 땡겨서 연산을 해 두는 방법으로 3clock낭비 -> 1clock낭비로 낭비를 줄일 수 있다.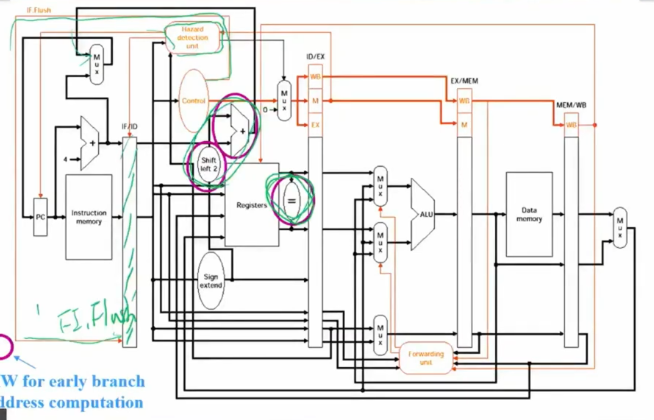
3) Branch prediction
이제는 branch가 일어날지에 대해 예측하는 것이다.
가장 심플한 방법은 무조건 branch가 일어나지 않는 다에 거는 것이다. 이렇게 되면 branch가 일어나지 않을 때는 당연히 손해가 없으며, 만약 branch가 일어난다면 IF단에 들어온 명령어를 무효화 시켜버리는 것이다.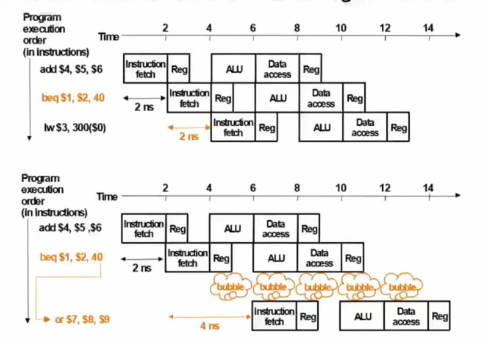
무효화시키는 것은 한 clock을 손해 보는 것이기에 위에서의 무조건 1clock손해에 비해 효율적이다. 이를 bubble or NOP라고 한다.
아래와 같이 1clock만 손해보고 다음에 바로 이어서 실행해 버린다.
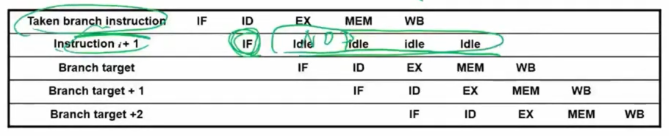
위의 방법을 정적 branch prediction이라고 한다.
이와 반대로 Dynamic하게 상황에 따라 예측할 수 있는 동적 branch prediction도 있다. 하지만 당연하게 계속 반대로 할 위험이 따른다.
이 방법은 과거의 내용을 기록하며 branch를 했는 지 따져본 후 현재 branch를 할 지 예측하는 방법이다.
방법론은 간단한데, 틀리면 방향을 바꾸는 것이다. 하지만 이렇게 되면 계속 방향을 바꾸며 틀릴 가능성이 있기에 2-bit prediction scheme으로 두 번 연속으로 틀릴 시 방향을 바꾸는 방법도 사용된다. 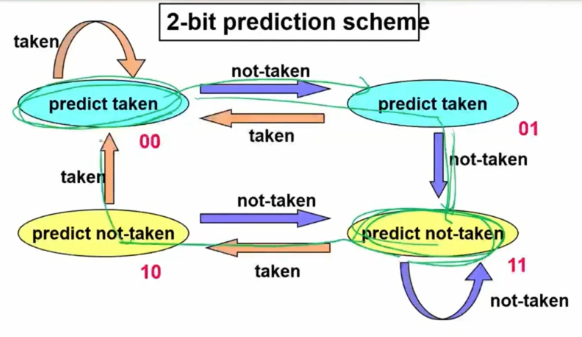
4) Delayed branch
마지막으로 이 방법은 Branch의 바로 다음 명령어를 branch의 방향에 상관없이 실행하는 것이다.
예를 들어 beq(slt jump) add sub slt 인 경우 beq가 시행되는 중에 add가 일어나는데 만약 branch를 하게 되면 충돌이 일어나 문제가 발생하는 것이다.
그렇기에 이때 beq NOP add sub slt 로 세팅하여 beq에서 계산하고 NOP가 시행되어 branch가 일어나든 일어나지 않든 문제가 없게 세팅을 해 두는 것이다. 즉, data hazard의 소프트웨어로 세팅해두는 것과 같다.
여기서 더 나아가 NOP자리에 branch를 하든 하지 않든 상관없는 계산을 껴 두면 더욱 효율적으로 사용할 수 있고, 이와 같이 명령어를 하나 더 실행하는 것 처럼 보이기에 delayed branch라고 한다!
