Memory Hierarchy 1(메모리 계층구조)
CPU는 날이 갈 수록 발전되어 계산이 빠르게 진행된다.
하지만 이 명령어를 빨리 실행하는 만큼 다음 명령어 및 명령어를 실행하기 위한 데이터가 빠르게 공급되어야 하는데, 메모리에서 CPU로 전달되는 속도가 한계가 있어 bottel neck이 되는 현상이 지속되고 있다.
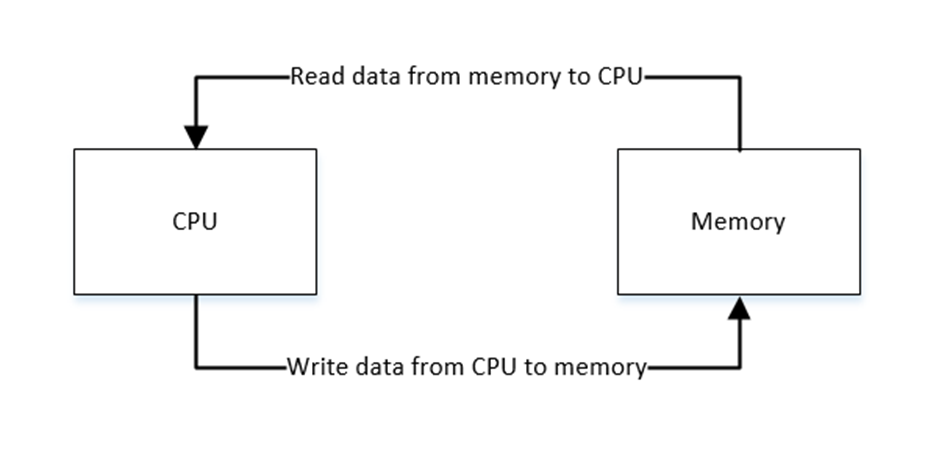
이로 인해 빠른 CPU보다는 빠른 메모리의 요구가 대두되고 있다.
메모리 계층구조에서 알아볼 내용은 크게 아래와 같다.
1. Memory hierarchy general
-Large sv Fast
-Principle of locality
2. Basics of cache
3. Improving chache performance
4. Virtual memory
1. Memory hierarchy general
- Large sv Fast
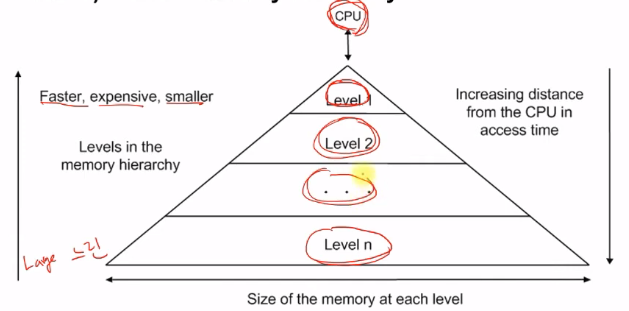
큰 메모리를 가진다면 속도가 느리고, 빠르다면 작은 크기를 가지고 있다.
하지만 우리는 large and fast memory를 원한다.
이를 충족하기 위해 '메모리 계층구조'를 만들어 해결한다.
아래 그림과 같이 위에서 부터 차례로 데이터를 찾아 나선다.
=> 이렇게 계층적으로 쌓는다면 용량은 크되, 위쪽의 데이터들은 빨리 뽑을 수 있는 장점을 얻게 된다!
(여기서 위쪽에 있는 메모리는 아래에도 존재한다.)
- Principle of locality
예를 들어 우리가 코딩을 한다면 사용한 변수들은 주로 이어서 사용하게 된다.
ex) a = b+c; d = a//2+1; # a가 연속적으로 사용된다.
이렇게 변수들은 temporal locality의 성향을 드러낸다.
변수가 주로 계속해서 연쇄적으로 사용되는데, 이 때 우리는 계층적 메모리 구조를 사용하기에 맨 위쪽에 데이터를 저장해 둔다면, 빠른 속도로 접근할 수 있다는 장점이 있다!
또한 반복문의 경우도 spatial locality로
for i in range(10): sum = sum +a[i]
과 같이 사용될텐데 이러한 경우에도 굉장히 유용하다.
이와 같이 메모리 지역성 때문에 계층적 메모리 구조가 사용되는 것이다.
실제로 어떻게 계층적 메모리 구조가 이루어져 있는 지 확인해 보자.
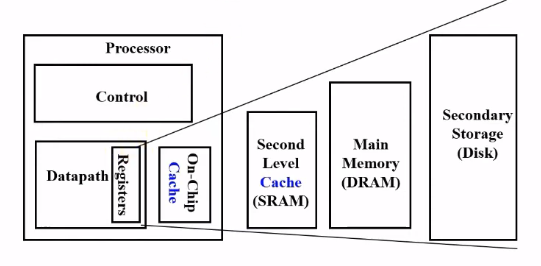
- CPU내부의 레지스터로 가장 빠르고 비싸고 작다.
- Cache
- Second Level Cache(SLAM) (DLAM에 비해 비싸고 면적도 넓지만 속도가 10배 넘게 빠르다.)
- DRAM (main memory)
- Secondary 저장소 : Disk
Caches
캐시는 더 크고 느린 저장 장치의 버퍼로 작동하여 주로 Principal of locality를 활용하여 빠른 액세스를 제공하는 것을 목적으로 한다.
< 용어 >
block : minimum unit of data
hit : data requested is in the upper level
miss : data requested is not in the upper level
ex) 어떤 block을 찾기 위해 이동하는데, level1 에서 데이터가 없으면 miss로 level2 로 이동하여 찾으면 hit
이 때, CPU는 stall로 freeze시킨 후 아래 계층의 데이터를 복사하여 위로 올린다.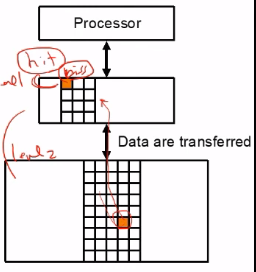
이 부분에서 데이터를 가져오는 속도가 꽤 걸리기에, 위에서 언급한 data locality를 잘 적용시키지 않으면 오히려 시간이 오래 걸린다.
따라서 이를 잘 적용시켜 놓아야 한다.
