Part1. 머신러닝
ch2. 머신러닝 프로젝트 처음부터 끝 까지
1. 특정 feature를 기준으로 train test split 하기
from sklearn.model_selection import StratifiedShuffleSplit
# 소득 카테고리(소득을 1,2,3,4,5로 분류)를 기반으로 샘플링
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]2. 시각화
경도 위도를 기준으로 집값을 시각화
여기에서 원의 크기는 인구수
housing.plot(kind='scatter', x='longitude', y='latitude', alpha=0.4,
s = housing['population']/100, label="population", figsize=(10,7),
c='median_house_value', cmap=plt.get_cmap("jet"), colorbar=True,
sharex=False)
plt.legend()
plt.show()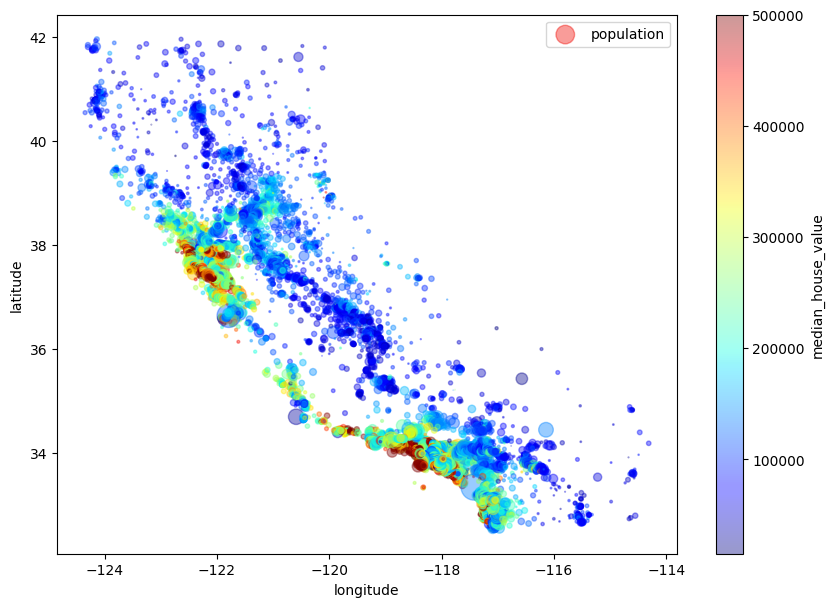
- 실제 캘리포니아 지도를 넣어 시각화
# 깔금한 그래프 출력을 위해
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# 그림을 저장할 위치
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "end_to_end_project"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("그림 저장:", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
---
# Download the California image
images_path = os.path.join(PROJECT_ROOT_DIR, "images", "end_to_end_project")
os.makedirs(images_path, exist_ok=True)
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
filename = "california.png"
print("Downloading", filename)
url = DOWNLOAD_ROOT + "images/end_to_end_project/" + filename
urllib.request.urlretrieve(url, os.path.join(images_path, filename))
---
import matplotlib.image as mpimg
california_img=mpimg.imread(os.path.join(images_path, filename))
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, label="Population",
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar(ticks=tick_values/prices.max())
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)
plt.legend(fontsize=16)
save_fig("california_housing_prices_plot")
plt.show()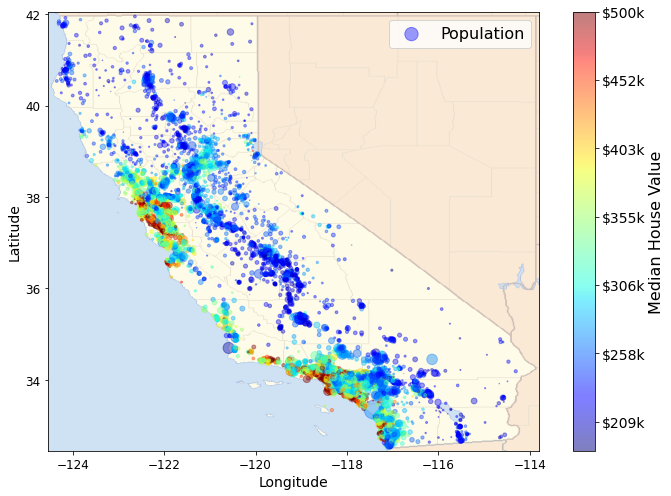
3. Null 값 쉽게 채우기
사이킷런의 SimpleImputer 로 Null값 중간값으로 대체하기
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
---
# 범주형 데이터 뺀 복사본
housing_num = housing.drop('acean_proximity', axis=1)
---
imputer.fit(housing_num)
# 만든 imputer 확인
imputer.statistics_
imputer.strategy
# 원래 중앙값
housing_num.median().values # 위랑 같다
---
# imputer 적용
X = imputer.transform(housing_nym)
# pandas로 변환
housing_tr = pd.DataFrame(X, columns=housing_num.columns,
index = housing_num.index)4. transform pipeline 사용
순서를 조심하여 사용
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
---
# 각 열마다 적절한 변환을 적용
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)5. 교차검증
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
---
def display_scores(scores):
print("점수:", scores)
print("평균:", scores.mean())
print("표준 편차:", scores.std())
display_scores(tree_rmse_scores)6. 하이퍼 파라미터 튜닝
1) Grid Search
- Random Patches method : 특성 및 데이터 셋 샘플링(bootstraping) 모두 사용하는 방식
- Random Subspace method : 특성만 샘플링하는 방식
: bootstrap=False 이고, bootstrap_features=True 그리고 max_features는 1.0보다 작은 값-> 이러한 특성 샘플링은 더 다양한 모델을 만들며 편향은 늘어나지만 분산을 낮출 수 있다.
from sklearn.model_selection import GridSearchCV
param_grid = [
# 12(=3×4)개의 하이퍼파라미터 조합을 시도합니다.
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
# bootstrap은 False로 하고 6(=2×3)개의 조합을 시도합니다. (특성만)
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# 다섯 개의 폴드로 훈련하면 총 (12+6)*5=90번의 훈련이 일어납니다.
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error',
return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
---
grid_search.best_params_
---
grid_search.best_estimator_
---
# 그리드서치에서 테스트한 하이퍼파라미터 조합의 점수를 확인합니다:
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
---
pd.DataFrame(grid_search.cv_results_)
2) Random Search
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(housing_prepared, housing_labels)
---
cvres = rnd_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)3) feature importances
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importances
---
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
#cat_encoder = cat_pipeline.named_steps["cat_encoder"] # 예전 방식
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)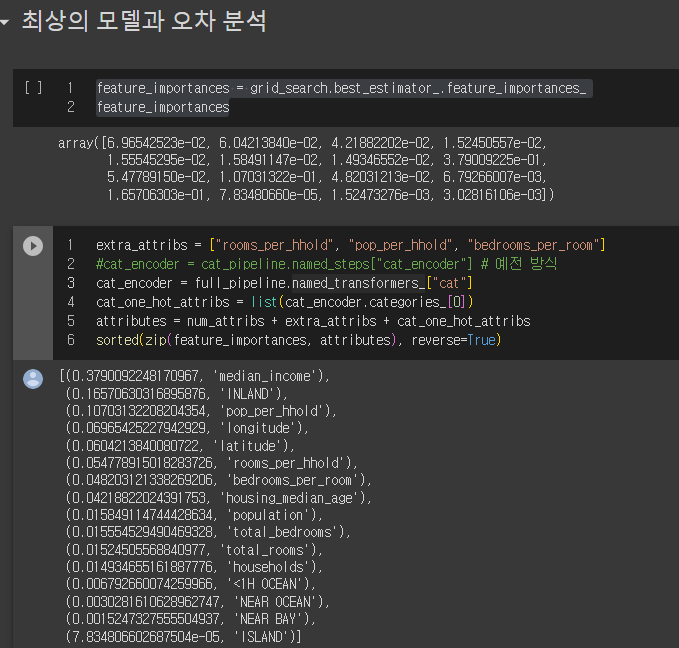
7. grid search 결과를 모델에 저장 후 test set 적용
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse8. 테스트 RMSE에 대한 95% 신뢰 구간을 계산
from scipy import stats
confidence = 0.95
squared_errors = (final_predictions - y_test) ** 2
np.sqrt(stats.t.interval(confidence, len(squared_errors) - 1,
loc=squared_errors.mean(),
scale=stats.sem(squared_errors)))
수학과 대학원생. 한 걸음씩 꾸준히