핸즈온 머신러닝
Part1. 머신러닝 ch7. 앙상블 학습과 랜덤포레스트
1. 앙상블의 유형
Voting
hard, softBagging
Random ForestBoosting
AdaBoost, Gradient Boost, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost)Stacking
2. 보팅
보팅은 hard, soft보팅이 있습니다.
Hard voting은 다수의 classifier의 예측 결과값을 다수결로 최종 class를 결정합니다.
Soft voting은 다수의 classifier의 예측 결과값간 확률을 평균하여 최종 class를 결정합니다.
-> 일반적으로 Soft voting이 성능이 우수하여 주로 사용됩니다.
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log = LogisticRegression()
rf = RandomForestClassifier()
svm = SVC()
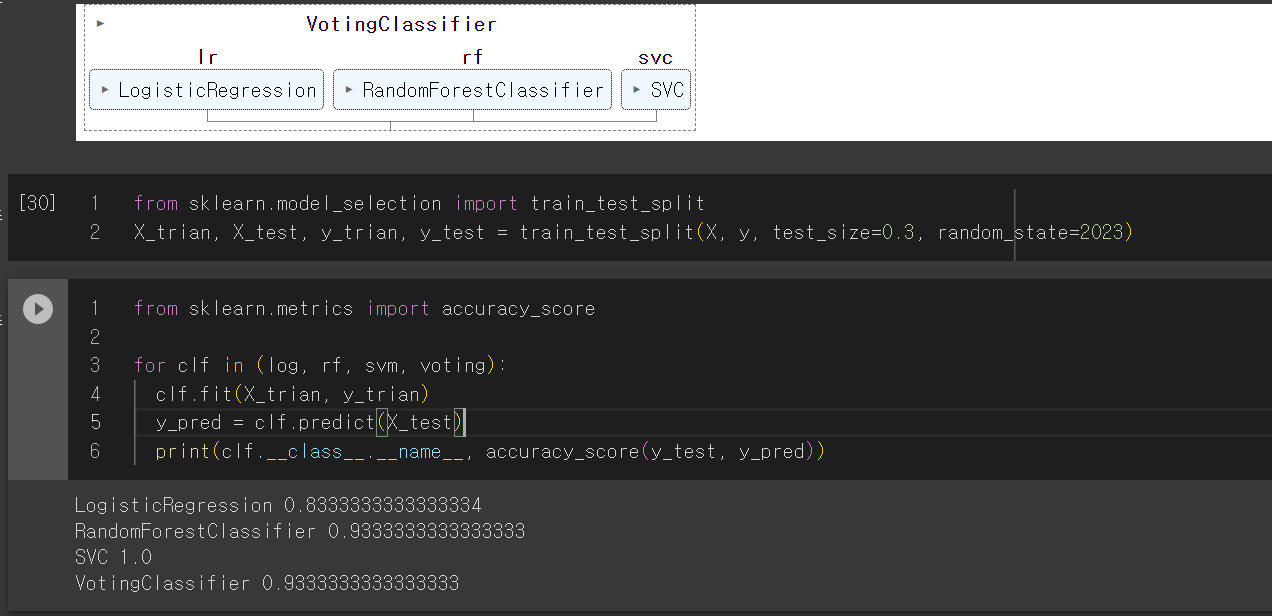
voting = VotingClassifier(
estimators=[('lr', log), ('rf', rf), ('svc', svm)],
voting='hard'
)
voting.fit(X, y)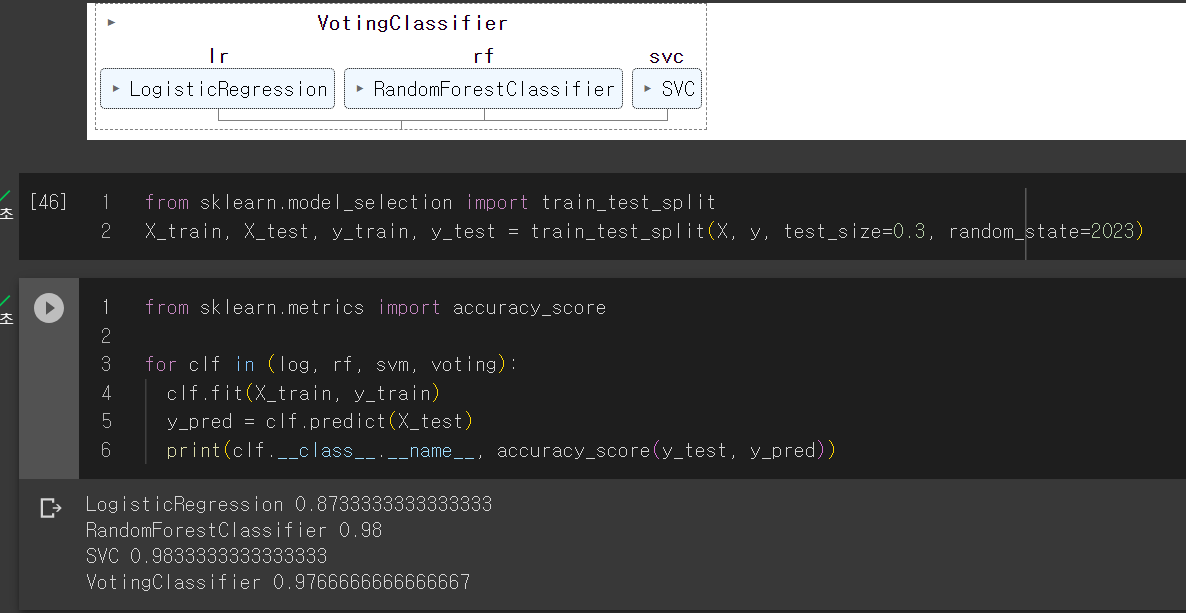
3. 배깅
※ Voting vs Bagging
Voting과 Bagging은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식이라는 점에서 유사합니다.
Q. 차이점?
Voting은 위에서 본 바와 같이 서로 다른 알고리즘을 가진 분류기가 같은 데이터셋을 기반으로 학습되고 결합합니다.
Bagging은 같은 알고리즘 유형의 모델들이 있지만 데이터 샘플링을 다르게 하여 학습 데이터셋이 각각 다릅니다. (단 교차 검증과 다르게 데이터 세트간 중첩을 허용)
++ 중복을 허용하지 않고 샘플링 하는 방식을 페이스팅이라고 합니다.
보팅과 배깅 둘 다 병렬적으로 학습합니다.
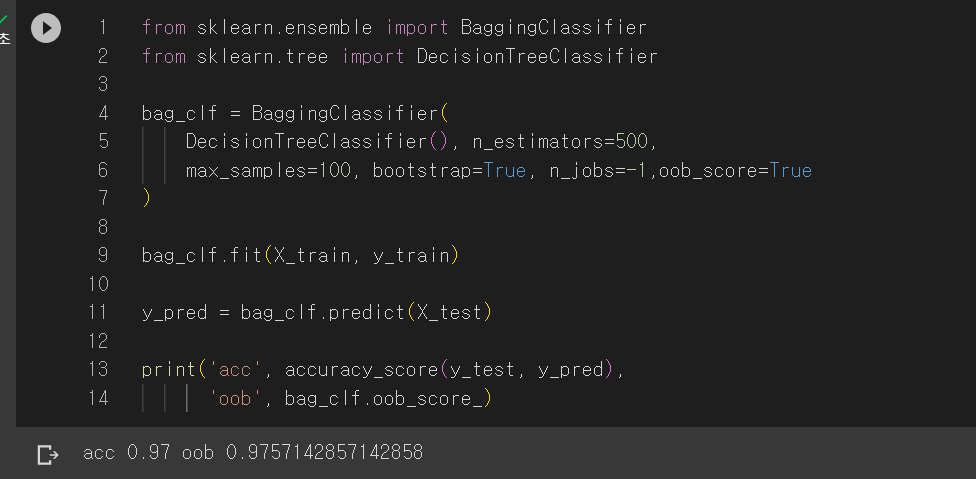
아래는 배깅에 대한 코드입니다.
500개의 결정 트리를 사용하며, 중복을 허용한 무작위 샘플링 100개를 사용합니다.
boostrap=False로 두면 페이스팅을 사용하며, n jobs는 CPU코어 개수로 -1로 지정하면 가용한 모든 코어를 사용합니다.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1
)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))여기서 배깅은 중복을 허용한 무작위 샘플링이기에 뽑히지 않는 데이터가 있을 수 있습니다. 평균적으로 각 예측기에 훈련 샘플의 63% 정도만 샘플링 됩니다. 따라서 선택되지 않은 훈련 샘플의 나머지 37%를 out-of-bag(oob)라고 부릅니다. 예측기마다 남겨진 37%는 모두 다릅니다.
따라서 배깅 모델을 만들 때 oobscore=True로 두어 자동으로 oob평가를 수행합니다.
(**obb_score** 변수에 저장되어 있습니다.)
추가적으로 oob샘플에 대한 결정 함수의 값은 oobdecision_function 변수에서 확인할 수 있습니다.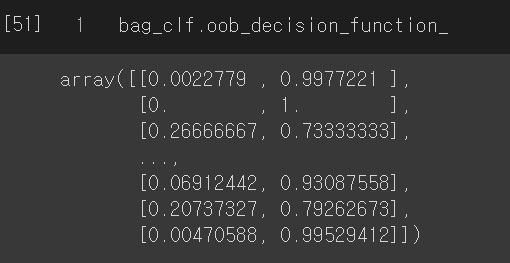
4. RandomForesst vs Extratrees
RandomForestClassifier와 ExtraTreesClassifier는 모두 앙상블 학습 기법을 기반으로 한 분류 모델입니다. 이 두 모델은 비슷한 아이디어를 공유하지만 몇 가지 중요한 차이점이 있습니다:
분할 기준 선택 방법:
RandomForestClassifier: 무작위로 선택한 일부 특성(feature)을 고려하여 각 노드에서 최적의 분할 기준을 찾습니다. 이렇게 하면 다양한 트리가 생성되고, 과적합을 줄이는 데 도움이 됩니다.
ExtraTreesClassifier: 랜덤 포레스트와 달리 모든 특성을 고려하여 각 노드에서 최적의 분할 기준을 찾지 않고, 특성 중에서 무작위로 선택한 임계값을 사용하여 노드를 분할합니다. 이로 인해 더 많은 무작위성이 도입되며, 이는 모델의 다양성을 높이고 더 견고한 모델을 만들 수 있습니다.
부트스트랩 샘플링:RandomForestClassifier: 부트스트랩 샘플링(중복 허용 임의 샘플링)을 사용하여 각 트리를 학습합니다. 이는 각 트리가 서로 다른 데이터 부분 집합에 학습되도록 합니다.
ExtraTreesClassifier: 랜덤 포레스트와는 달리 부트스트랩 샘플링을 사용하지 않고 전체 학습 데이터를 사용하여 각 트리를 학습합니다.
노드 분할 시점:RandomForestClassifier: 각 노드에서 최적의 분할 기준을 찾을 때 Gini 불순도나 엔트로피 등의 지표를 사용하여 가장 좋은 특성과 분할 값을 선택합니다.
ExtraTreesClassifier: 특성과 임계값을 완전히 무작위로 선택하므로, 최적의 분할 기준을 찾는 데 무작위성이 도입됩니다.
총평하면, RandomForestClassifier와 ExtraTreesClassifier 모두 앙상블 학습을 기반으로 하며 무작위성을 활용하여 다양한 트리를 생성합니다. 그러나 ExtraTreesClassifier는 더 많은 무작위성을 도입하고, 이로 인해 더 견고한 모델을 만들 수 있지만, RandomForestClassifier는 더 정교한 최적화를 통해 더 나은 예측을 할 수 있을 때가 있습니다. 어떤 모델을 선택할지는 문제에 따라 다를 수 있으며, 실험을 통해 최적의 모델을 결정해야 합니다.
Extra Trees에서는 무작위로 특성과 분할 임계값을 선택하는 과정은 다음과 같이 이루어집니다:
특성의 무작위 선택:
각 노드에서 분할을 수행할 때, 모든 특성(입력 변수)이 고려됩니다. 다시 말해, 가능한 분할 후보군은 데이터셋에 있는 모든 특성을 대상으로 합니다.
임계값의 무작위 선택:선택된 특성을 기준으로, 분할을 위한 임계값(threshold)을 무작위로 선택합니다. 이 임계값은 해당 특성의 값 범위 내에서 무작위로 선택됩니다.
가장 좋은 분할 선택:무작위로 선택된 특성과 임계값을 사용하여 노드를 분할합니다. 분할 후에는 정보 이득(또는 지니 불순도)과 같은 분할의 품질 지표를 사용하여 분할의 품질을 측정합니다.
가장 좋은 분할 선택:모든 무작위한 분할 후보군 중에서 가장 좋은 분할을 선택합니다. 여기서 "가장 좋은 분할"은 분할 후의 불순도를 최소화하거나 정보 이득을 최대화하는 분할을 의미합니다.
이렇게 무작위로 선택된 특성과 임계값을 사용하여 가장 좋은 분할을 찾습니다. 이러한 과정을 여러 번 반복하여 트리를 계속 성장시킵니다. 이것이 Extra Trees에서 모든 특성과 임계값을 무작위로 선택하는 방식입니다. 이러한 접근은 모델이 다양한 특성 조합을 고려하면서 노드를 분할하도록 만들어, 더욱 다양하고 견고한 모델을 형성합니다.
* 특성중요도
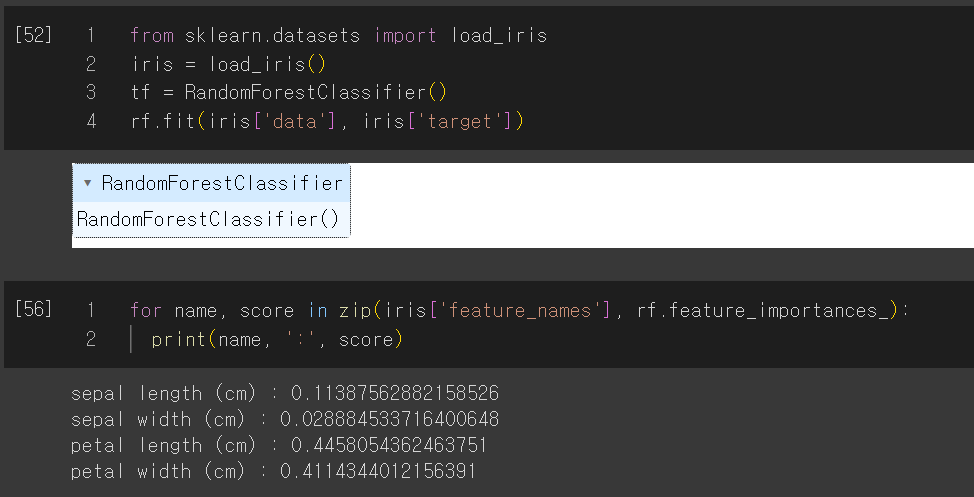
5. 부스팅
부스팅은 약한 학습기 여러개를 연결하여 강한 학습기를 만드는 앙상블 방법을 말합니다. 앞의 모델을 보완해가며 예측기를 학습시키는 것 입니다. 병렬적으로 처리하는 배깅과는 다릅니다. 그렇기에 일반화 성능이 좋은 배깅에 비해 성능이 좋을 순 있지만 과적합의 위험이 존재합니다.
1) Ada Boost


아래는 AdaBoost 코드입니다. max depth=1로 결정 노드 하나와 리프 노드 두개로 이루어진 shallow 결정트리를 200개 연쇄적으로 학습시키며 보강해나갑니다.
from sklearn.ensemble import AdaBoostClassifier
ada = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm='SAMME.R' ,learning_rate=0.5
)
ada.fit(X_train, y_train)이렇게 만든 모델은 예측치 가중치 합을 통해 가중치 합이 가장 큰 클래스가 예측 결과가 됩니다.
2) Gradient Boosting
GD는 위의 adaboost와 비슷하지만 adaboost는 가중치를 반복마다 수정하는 대신, 이전 예측기가 만든 잔여 오차(residual error)에 새로운 예측기를 학습시킵니다.
GradientBoostingRegressor가 있지만 아래와 같이 결정 트리를 연쇄적으로 사용하여 잔여 오차에 대해 학습시키며 앙상블을 구축할 수 있습니다.
from sklearn.tree import DecisionTreeRegressor
tree1 = DecisionTreeClassifier(max_depth=2)
tree1.fit(X, y)
y2 = y - tree1.predict(X)
tree2 = DecisionTreeClassifier(max_depth=2)
tree2.fit(X, y2)
y3 = y2 - tree2.predict(X)
tree3 = DecisionTreeClassifier(max_depth=2)
tree3.fit(X, y3)
y_pred = sum(tree.predcit(X_new) for tree in (tree1, tree2, tree3))
# 기존 모델의 예측값에 오차를 더해주어 조정해주는 것과 같습니다!아래는 위와 같은 모델입니다.
from sklearn.ensemble import GradientBoostingRegressor
gb = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
gb.fit(X, y)이 GradientBoosting은 최적의 트리 수를 찾기 위해 아래와 같이 staged_predict를 통해 낮은 에러율을 보이는 tree의 수를 정할 수 있습니다.
early stopping과 같은 효과라고 볼 수 있습니다.
from sklearn.ensemble import GradientBoostingRegressor
gb = GradientBoostingRegressor(max_depth=2, n_estimators=120)
gb.fit(X_train, y_train)
errors = [mean_square_error(y_val, y_pred) for y_pred in gb.staged_predict(X_val)]
best_n_estimators = np.argmin(errors)+1
gb_best = GradientBoostingRegressor(max_depth=2, n_estimators=best_n_estimators)
gb_best.fit(X_train, y_train)3) XGBoost
XGBoost는 바로 val data를 통해 조기 종료와 같은 기능을 포함합니다.
from xgboost import XGBRegressor
xgb = XGBRegressor()
xgb.fit(X_train, y_train,
eval_set=[(X_val, y_val)], early_stopping_rounds=2)
y_pred = xgb.predict(X_test)7. 스태킹
보팅과 배깅의 경우는 모델들의 예측값을 바로 이용했다면, 스태킹은 여러 모델들의 예측값을 input으로 받아 이것을 통해 output을 내어 예측값을 도출합니다. 여러 모델의 output을 input으로 받는 모델을 블렌딩이라고 하며 블렌딩의 숫자는 하나 이상 다 가능합니다.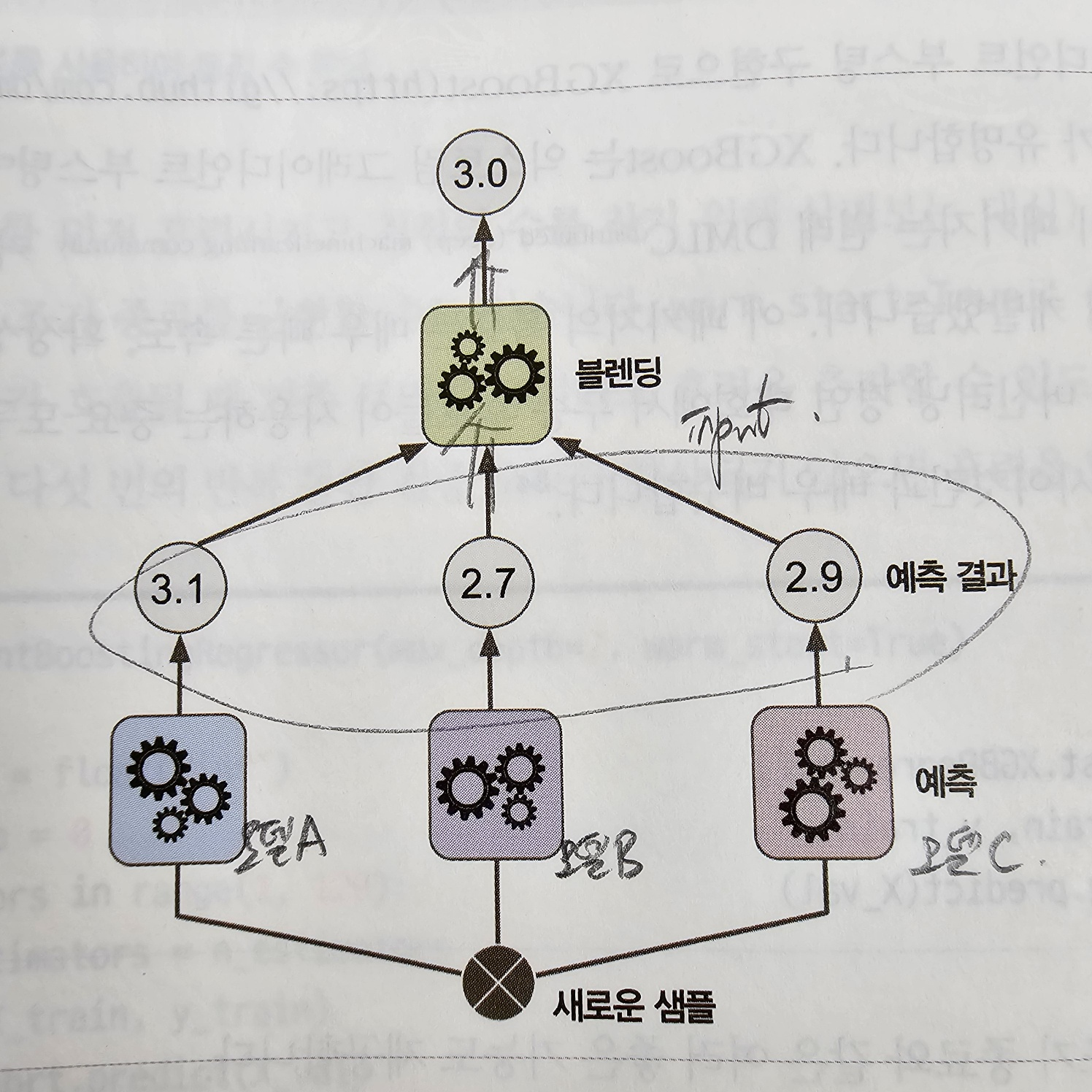
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
X_train , X_test , y_train , y_test = train_test_split(X_data , y_label , test_size=0.2 , random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25)
# 개별 ML 모델을 위한 Classifier 생성.
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
# 최종 Stacking 모델을 위한 Classifier생성.
lr_final = LogisticRegression(C=10)
# 개별 모델들을 학습.
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train , y_train)
dt_clf.fit(X_train , y_train)
ada_clf.fit(X_train, y_train)
knn_pred = knn_clf.predict(X_val)
rf_pred = rf_clf.predict(X_val)
dt_pred = dt_clf.predict(X_val)
ada_pred = ada_clf.predict(X_val)
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
# transpose를 이용해 행과 열의 위치 교환. 컬럼 레벨로 각 알고리즘의 예측 결과를 피처로 만듦.
pred = np.transpose(pred)
lr_final.fit(pred, y_val)
# 학습된 개별 모델들이 각자 반환하는 예측 데이터 셋을 생성하고 개별 모델의 정확도 측정.
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
real_pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
real_pred = np.transpose(real_pred)
final = lr_final.predict(real_pred)
# 개별 모델 성능
print('KNN 정확도: {0:.4f}'.format(accuracy_score(y_test, knn_pred)))
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy_score(y_test, rf_pred)))
print('결정 트리 정확도: {0:.4f}'.format(accuracy_score(y_test, dt_pred)))
print('에이다부스트 정확도: {0:.4f}'.format(accuracy_score(y_test, ada_pred)))
# 스태킹 성능
print('최종 메타 모델의 예측 정확도: {0:.4f}'.format(accuracy_score(y_test , final)))