먼저 해당 모델을 가장 쉽게 이해하려면 데모를 시행해보는것을 추천한다.
당시 라벨링 부분에서 굉장한 모델이었고, 이 모델을 시작으로 여러 툴에 이 모델이 탑재되고, 많은 튜닝 모델이 쏟아져 나왔었다. 현재는 SAM2도 나왔는데... 예전 간단한게 리뷰해둔걸 지금 옮겨 적는다...
개요
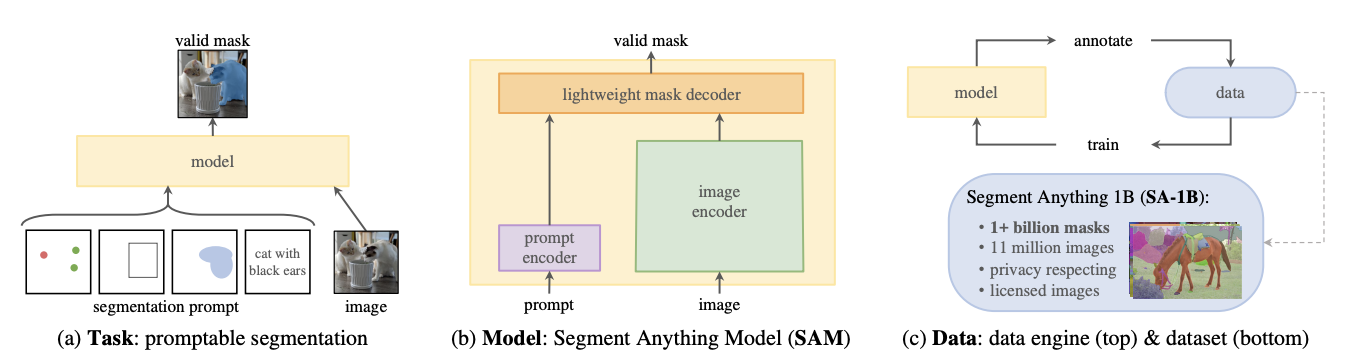
최근 LLM들은 Zero shot learning, Few-shot learning 으로 매우 인상적인 성능을 만들어가고 있습니다.
최근 meta에서 발표한 Segment Anything Model (이하 SAM)은 Image Segmentation에 대한 Foundation Model을 만드는 것을 목표로 하고 있으며, Prompt Engineering을 통해 여러 종류의 Image Segmentation이 가진 문제점을 보완해 나아가고자 합니다.
💡LLM에 적용하던 Prompt Engineering 기법으로 메타에서 거대 모델을 만들어 Image Segmentation에 적용한다
모델
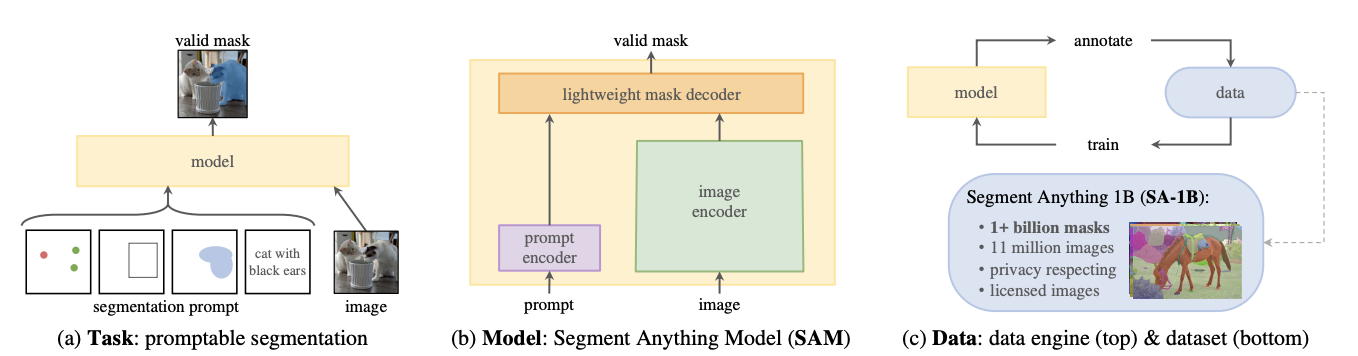
해당 모델은 세가지의 구조를 가지고있다
1. 이미지 인코더
2. 프롬프트 인코더
3. 마스크 디코더
💡 여기서 프롬프트는 일반적으로 우리가 LLM에서 사용하는 프롬프트와는 다르다. 점, 박스, 마스크, 혹은 텍스트가 된다.
모델의 개념은 먼저 이미지를 임베딩하여 인코딩을 하고, 사용자에게 프롬프트를 입력 받아서 인코딩한다. 그리고 해당 프롬프트에 맞는 마스크를 생성한다. 이때 프롬프트는 점, 박스, 마스크의 좌표 혹은 텍스트
이미지 인코더는 무겁지만, 미리 연산이 가능하며, 연산 시켜 둔 이미지 임베딩을 그대로 마스크 생성에 사용할수 있다.
이와 반대로 프롬프트 인코더와 마스크 디코더는 굉장히 가볍기 때문에, 프론트엔드 단에서 처리가 가능한 장점이 있다
💡 따라서 서비스 단에서는 미리 db에 임베딩 값을 저장해두고 실시간으로 빠르게 세그멘테이션을 처리 할 수 있다!
모호함의 문제
개발진들은 모델의 구동방식의 하나의 문제를 겪는다.
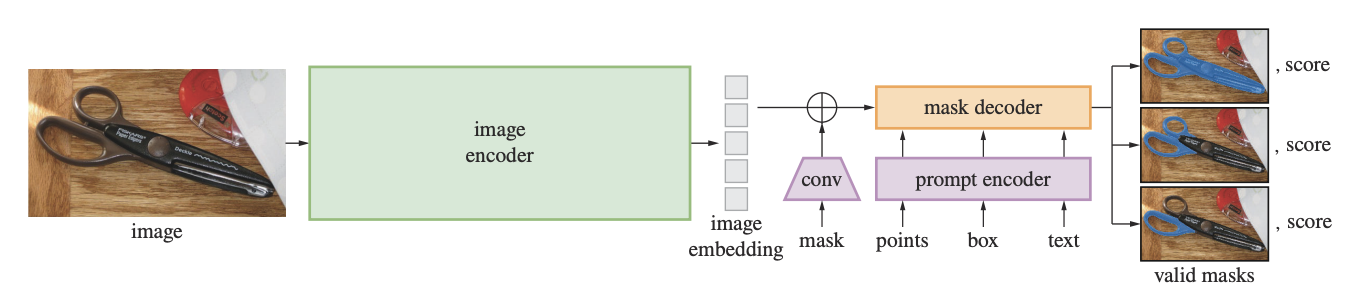
프롬프트는 점과 박스 등등으로 사용자가 사진에 입력하게 되면 모호한 경우가 생긴다.
이때, 디코더는 마스크를 Whole, Part, Sub-Part 세가지의 정답을 생성하여 정답값과 정답에 얼마나 근사한지 값도 계산을 한다
사용자는 세개중 하나를 선택 할 수도 있고, 세개중 argmax 사용하여 가장 정답 같은 값을 자동으로 받을수도 있다.
데이터 구축
텍스트 정보와 달리 Segmentation Mask는 인터넷에서 손쉽게 구하기 어려운 데이터다. Meta는 대규모(1.1B)의 마스크를 취득하기 위해 자체적인 Data Engine을 구현했다.
Data Engine은 다음 세 가지 Stage로 구성된다.
- Assisted-manual: 작업자가 점을 찍으면 SAM 모델이 어느정도 마스크를 만들어줍니다. 이렇게 도와주면서 레이블링 합니다.
- Semi-automatic: 특정 object 집합에 대해 SAM이 알아서 마스크를 만들면 동시에 작업자가 다른 object에 대해 마스크를 만듭니다. 예를 들면, SAM에게 "Generating masks for all apples in an image"라고 말하면 얘가 사과 마스크 만들고 있을 동안 사람이 다른 애들을 작업하는 겁니다.
- Fully automatic: 이미지에 grid point를 찍어서 모든걸 알아서 masking하게 됩니다.
초기에는 자동이 아닌 작업자를 구하여 반자동 > 자동으로 작업하였다.
이런 대규모 데이터를 자체 제작 하기 위해서 얼마나 많은 사람들이 고생했을지...
<파인튜닝 관련자료>
Segment Anything 모델 미세조정하기 (How To Fine-Tune Segment Anything)
Segment Anything으로 labeling 없는 데이터를 fine tuning하기
<모두의 연구소 세미나 쉽게 설명해주는 sam>
SAM(Segment Anything Model)과 친해지기 - 김경환(스마일게이트, ML 엔지니어) | 모두의연구소 K-디지털플랫폼 모두팝
