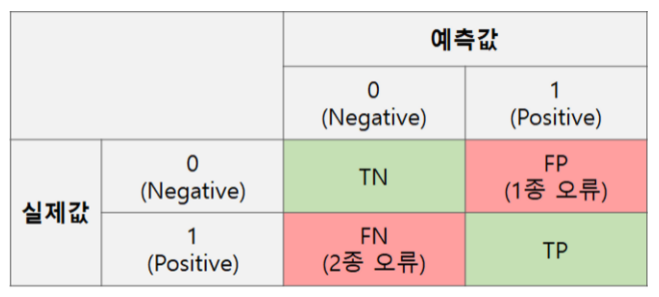
📝 Confusion Matrix (혼동 행렬)
- 모델이 성능을 평가할 때 사용되는 지표
- 예측값이 실제값을 얼마나 정확히 예측했는지 보여주는 행렬
TRUE : 모델이 맞췄을 때
FALSE : 모델이 틀림
Positive : 모델이 예측 값이 TRUE
Negative : 모델이 예측 값이 FALSE

- TN : 아닌것을 아니라고 “잘” 예측
- FP : 아닌데 맞는 것으로 예측 - 1종오류
- FN : 맞는데 아닌 것으로 예측 - 2종오류
- TP : 맞는 것을 맞는 것으로 “잘” 예측
✏️ 1종 오류와 2종 오류
- 1종 오류: 통계상 실제로는 음성인데 결과는 양성이라고 나오는 것
- 2종 오류: 통계상 실제로는 양성인데 겨로가는 음성이라고 나오는 것
- 1종 오류와 2종 오류는 tradeoff관계
- 한쪽 오류를 강제로 줄이면 다른 오류가 늘어나게 된다.
ex)


- TN : 임신이 아닌 사람을 임신이 아니라고 잘 예측했다.
- FP - 1종 오류
: 실제는 임신이 아닌데, 임신으로 예측했다. - FN - 2종 오류
: 실제는 임신인데, 임신이 아닌 것으로 예측했다. - TP : 실제 임신인데, 임신으로 잘 예측했다.
📝 분류 성능 평가 지표
1. 정확도 (Accuracy)
전체 데이터에서 모델이 옳게 판단한 비율


2. 정밀도 (Precisioin)
양성 가운데 맞춘 양성의 수
💡 Tip
예프리 : 예측값이 1(Positive)인 것을 기준으로 하는 계산은 Precision


3. 재현율 (Recall)
= 민감도 (Sensitivity)
실제 양성을 양성으로 음성을 음성으로 판단한 비율
💡 Tip
실리콜 : 실제값이 1인 것을 기준으로 하는 계산은 Recall


4. 성능점수 (F1 Score)
정밀도와 민감도의 조화평균

5. 특이도 (Specificity)
음성 가운데 맞춘 음성의 수


📝 Precision과 Recall

✏️ Precision이 중요한 경우
: 스팸 메일 검출
- 스팸 메일이면 참, 스팸 메일이 아니면 거짓
→ 스팸 메일이 아닌데 스팸 메일로 판단해서 차단해버리면 중요한 메일을 받지 못할 수 있다.
Precision이 낮다: 참이 아닌데도 참이라고 한 것이 많다.
Precision이 지나치게 높다: 참으로 예측한 경우가 필요 이상으로 적다.
→ 아주 확실한 경우에만 참으로 예측하고 나머지를 전부 거짓으로
✏️ Recall이 중요한 경우
① 암 검출
- 암이 검출되면 참, 검출되지 않으면 거짓
실제로 암에 걸렸는데 걸리지 않았다고 판단하는 경우가 가장 위험
② 지진
- 지진이 안났으나 대피명령을 한 것은 생명과 지장이 없다.
- 지진이 났는데 대피명령이 없다면 생명에 위험하다.
Recall이 낮다: 참인데 못 찾은 것이 많다.
Recall이 지나치게 높다: 참으로 예측한 경우가 필요 이상으로 많다.

안녕하세요