앙상블 (Ensemble)
여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
① 랜덤 포레스트
- 조금씩 다른 여러 결정트리의 묶음
- 각각 결정트리는 예측을 잘 할 수 있지만 데이터 일부에 과대적합된다.
- 예측을 잘 하지만 서로 다른 부분에 과대적합된 트리를 묶어 평균을 채택하면 과대적합을 줄일 수 있다.
② 그래디언트 부스팅
- 여러 결정트리의 묶음
- 랜덤 포레스트와 달리 순차적으로 결정트리를 만들며 이전 트리의 오차를 보완해간다.
- 얕은 트리를 많이 연결하여 성능이 좋은 최종 모델을 만들어내는 것
Bootstrap
- 주어진 훈련 데이터에서 중복을 허용하여 원 데이터셋과 같은 크기의 데이터셋을 만드는 과정
- 트리들의 편향은 그대로 유지하면서 분산 감소
=> 포레스트 성능 향상
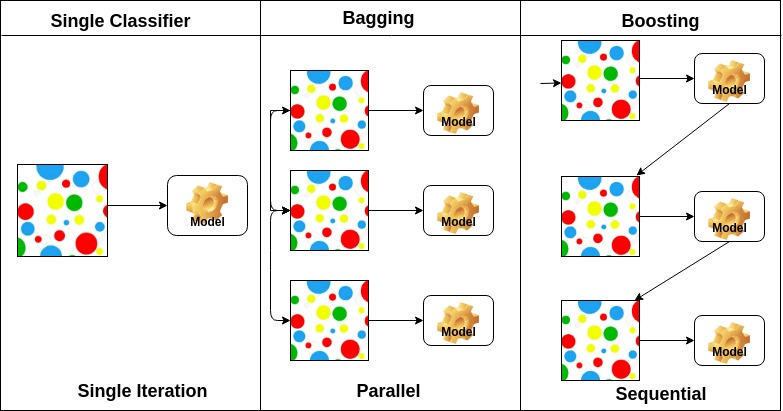
Bagging (Bootstrap aggregating)
-
부트스트랩을 통해 조금씩 다른 훈련 데이터에 대해 훈련된 기초분류기들을 결합시키는 방법
-
모든 트리들을 동일한 데이터셋으로만 훈련 -> 트리들의 상관성이 매우 커진다
=> 배깅: 서로 다른 데이터셋들에 대해 훈련시킴으로써 트리들을 비상관화
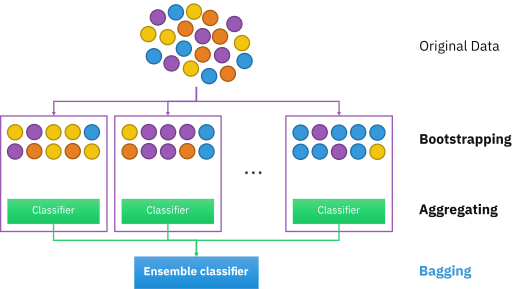
-
훈련 단계
① 부트스트랩 방법을 통해 T개의 훈련 데이터셋 생성
② T개의 기초 분류기(트리) 훈련
③ 기초 분류기(트리)들을 하나의 분류기(랜덤포레스트)로 결합
(평균 또는 과반수투표 방식 이용)
Boosting
여러 얕은 트리를 연결하며 편향과 분산을 줄여 강력한 트리를 생성하는 기법

<비교>
GBM (Gradient Boosting Machine)
- 회귀 / 분류분석
- 예측 모형의 앙상블 방법론 중 부스팅 계열에 속하는 알고리즘
- 예측 성능이 높다.
- 계산량이 상당히 많이 필요한 알고리즘 -> 하트웨어 효율적으로 구현하는 것이 필요
GBT (Gradient Boosting Tree)
sklearn.ensemble.GradientBoostingRegressor
- 주요 파라미터
- loss : 최적화시킬 손실함수 지정
- learning_rate : 각 트리의 기여도를 제한하는 파라미터
- n_estimators : 부스팅 단계를 지정하는 파라미터
- subsample : 개별 기본 학습자를 맞추는데 사용할 샘플의 비율
XGBoost
- 손실 함수가 최대한 감소하도록 split point(분할점) 찾기
- 장점
- 병렬 학습 => GBM 대비 빠른 수행 시간
- 과적합 규제
- 분류와 회귀 영역에서 뛰어난 예측 성능 발휘 (광범위한 영역)
- 다양한 옵션(Hyper Parameter) 제공, Customizing이 용이
- 단점
- GBM에 비해 성능이 좋지만 여전히 학습 시간이 느리다.
- Hyper Parameter 튜닝을 하면 시간이 더욱 오래 걸린다.
- 모델의 오버피팅
- 특징: Hyper Parameter의 종류가 많다.
LightGBM (Light Gradient Boosting Machine)
- Microsoft에서 개발한 머신러닝을 위한 오픈 소스 분산 그래디언트 부스팅 프레임워크
- 결정 트리 알고리즘 기반
- 개발 초점: 성능, 확장성
- 순위 지정, 분류 및 기타 기계 학습 작업에 이용
- 장점
- 더 빠른 훈련속도와 더 높은 효율성
- 적은 메모리 사용량
- 더 나은 정확도
- 병렬, 분산 및 GPU 학습 지원
- 대규모 데이터 처리
- 단점
- 과적합에 민감하고 작은 데이터에 대해서 과적합되기 쉽다.
- 특징
- 트리 기반 학습 알고리즘을 사용하는 그래디언트 부스팅 프레임워크
- GBT, GBDT , GBRT , GBM , MART 및 RF를 포함한 다양한 알고리즘을 지원
- GOSS(Gradient based One Side Sampling): 기울기 기반 단축 샘플링
- EFB(Exclusive Feature Bundling): 배타적 특성 묶음
※ GOSS
- 데이터에서 큰 Gradient를 가진 모든 인스턴스를 사용해 무작위 샘플링
- 많이 틀린 데이터 위주로 샘플링
=> 행 줄이기 : 대규모 데이터 인스턴스를 다루기 위한 것
※ EFB
- 열 줄이기 : 대규모 Feature 수를 다루기 위한 것
CatBoost
-
Yandex에서 개발한 오픈 소스 소프트웨어 라이브러리
-
기존 알고리즘과 비교하여 순열 기반 대안을 사용하여 범주형 기능을 해결하려고 시도하는 그래디언트 부스팅 프레임워크 제공
-
장점
- 범주형 기능에 대한 기본 처리
- 빠른 GPU 훈련
- 모델 및 기능 분석을 위한 시각화 및 도구
- 더 빠른 실행을 위해 무시 트리 또는 대칭 트리 사용
- 과적합을 극복하기 위해 순서가 있는 부스팅 사용
-
단점
- 희소 행렬을 지원하지 않음
- 데이터 세트에 수치형 타입이 많을 때 상대적으로 많은 시간 소요
-
특징
- 수평 트리
- 정렬된 부스팅
- 임의 순열
- 정렬된 대상 인코딩
- 범주형 Feature 조합
- 원핫인코딩
- 최적화된 파라미터 튜닝

안녕하세요