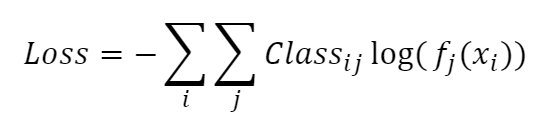📝 머신러닝(기계학습)
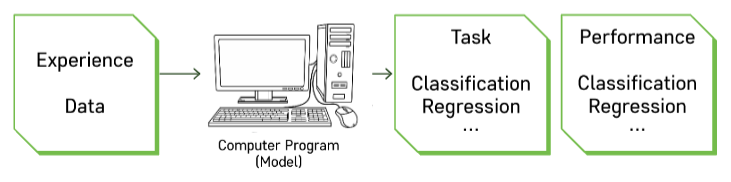
- 기계학습 모형이 문제를 해결해야 하는 환경/상황
- task가 주어지면 이를 적절한 방식으로 학습 수행
- 성능 측정 (accuracy, error, ...)
- 축적된 데이터 추출하여 유의미한 패턴을 찾아낸다.
- 종류
① 지도학습(Supervised Learning): 정답을 알려주면서 학습하는 것
- 분류 (Classification): 최종적인 output이 범주(class) 형태
- 회귀 (Regression): 최종적인 output이 연속적인 값
② 비지도학습(Unsupervised Learning): 정답 X, 컴퓨터 스스로 데이터의 속성, 특징들을 추출해내는 학습 방법
- Clustering
- Anomaly Detection: 이상치 찾기
③ 강화학습(Reinforcement Learning): 정확한 direction은 주지 않지만 컴퓨터가 취한 액션에 대해 보상을 정보로 줌으로써 학습하는 방법
- Markov Decision Process
- DQN
- A3C
📝 Classification
-
학습데이터로부터 함수를 찾는 방법론
-
종속변수 Y가 범주형이면 분류(classification), 연속형이면 회귀(regression)
X: 독립변수, 입력변수 Y: 종속변수, 출력변수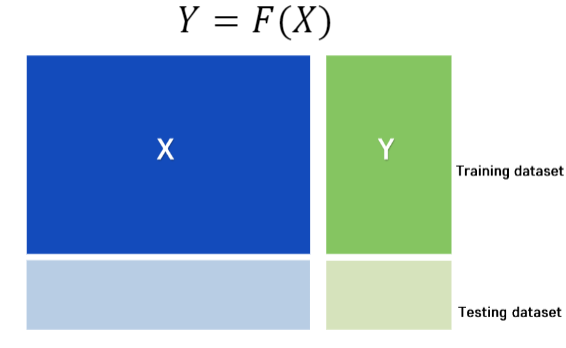
-
성능평가: Training 데이터와 Testing 데이터로 나누어 평가
-
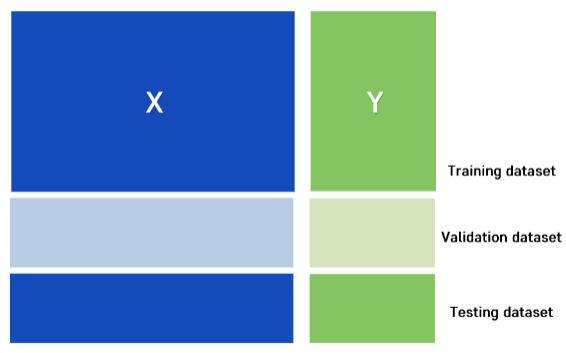
Hyperparameter Tunning: Training 데이터를 분할하여 Validation 데이터로 성능을 평가하면서 최적의 하이퍼파라미터 찾기
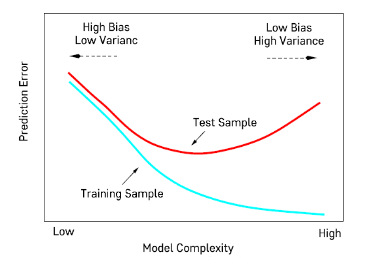
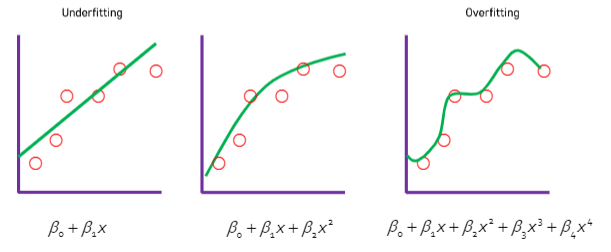
Bias-Variance Tradeoff
- Bias: 정확한 값에서 예측한 값이 얼마나 치우쳐있는가
- Variance: 데이터의 다양성
- 모형의 오차 = Bias + Variance
- 모형의 복잡도 ↑
=> Training 데이터를 지나치게 자세히 학습
=> 변동성 ↑: 데이터 구성이 조금만 달라져도 영향을 크게 받음
=> 일반화 오차의 증가
- 모형의 복잡도 ↓
=> Bias ↑: 모형의 예측 정확도가 떨어진다.
=> Variance ↓: 데이터 구성이 바뀌어도 모형이 크게 변동되지 않는다.
- 모형의 복잡도 ↑
모델 선택
- 모든 모델은 복잡도를 통제할 수 있는 Hyperparameter 를 갖고 있다.
- 가장 좋은 성능을 낼 수 있는 모델을 학습하기 위해 최적의 Hyperparameter를 결정해야 한다.
Validation Set
- 좋은 모델을 선택하기 위한 검증 데이터 셋
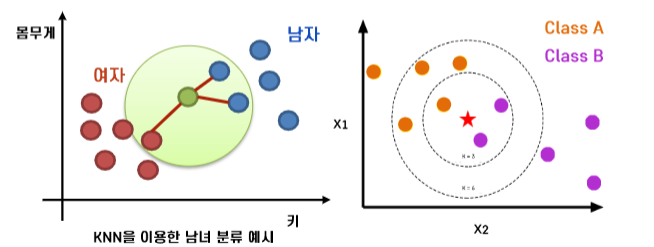
📝 K-Nearest Neighbors (KNN)
- "두 관측치의 거리가 가까우면 Y(Target/Label)도 비슷하다"
- K: Hyperparameter, 이웃의 수
- K개의 주변 관측치를 기준으로 더 많은 class를 채택
- Distance-based model, instane-based learning
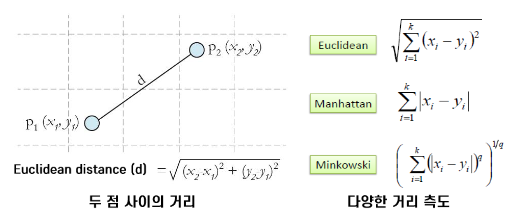
거리
- 두 관측치 사이의 거리 측정
- Euclidean: 데이터 공간에서 두 점 사이의 거리를 구하는 공식
- Manhattan: 데이터 공간 상에서 완벽하게 독립시켜서 변수별로 거리를 계산하고자 할 때
- Minkowsk
- 범주형 변수는 Dummy Variable으로 변환하여 거리 계산
*Lazy Learning Algorithm
이전까지 동작을 하지 않다가 Testing 데이터가 왔을 때 이 데이터를 기준으로 Training 데이터와의 거리를 구하고 최종 결과 출력
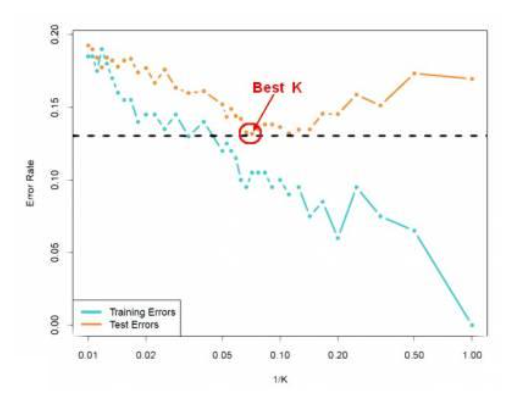
K의 영향
-
K가 클수록 과소적합, K가 작을수록 과대적합
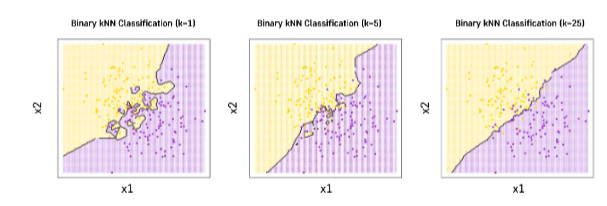
-
테스트: K가 작아질 수록 Training Error는 0으로 수렴하지만 Validation Error는 줄어들다가 다시 높아진다.
📝 Logistic Regression
다중선형회귀분석
목적
수치형 설명변수 X와 종속변수 Y간의 관계를 선형으로 가정하고 이를 가장 잘 표현할 수 있는 회귀 계수 추정
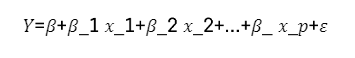
필요성
-
범주형 반응 변수: 이진변수, 멀티변수
-
이진형(0/1)의 형태를 갖는 종속변수(분류문제)에 대해 회귀식의 형태로 모형을 추정하기 위해서
-
회귀식으로 표현하는 이유: 변수의 통계적 유의성 분석 및 종속변수에 미치는 영향력 등을 알아볼 수 있다.
-
로지스틱 회귀분석의 특징
- 이진형 종속변수 Y를 그대로 사용하는 것이 아니라 Y에 대한 Logit function을 회귀식의 종속변수로 사용
- Logit funcion: 설명변수의 선형결합으로 표현
- 로짓함수의 값은 종속변수에 대한 성공확률로 역산될 수 있으므로 분류 문제에 적용 가능
시그모이드(Sigmoid) 함수
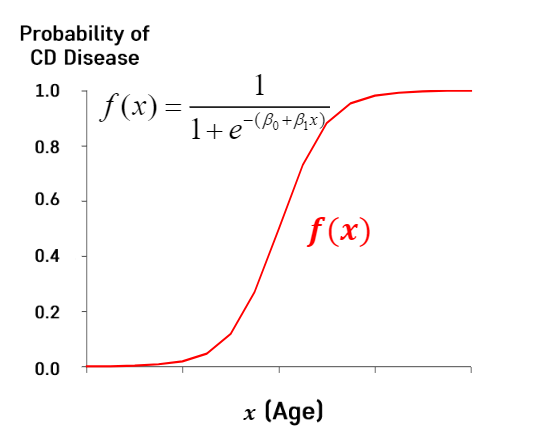
Cross Entropy