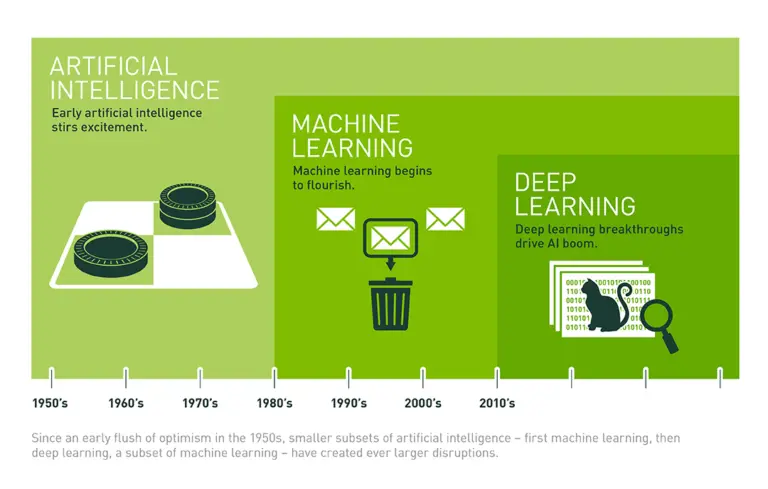
K-MOOC 복습
1.[K-MOOC] 인공지능과 머신러닝 개요
Knwledge Engineering유용한 함수를 직접 코딩하여 데이터와 함께 컴퓨터에 입력하면 컴퓨터가 이를 바탕으로 학습하여 최종적인 output을 낸다.Machine Learning데이터를 컴퓨터에 입력하여 function의 기본적인 형태를 알려주면 컴퓨터가 학습
2.[K-MOOC] 머신러닝 프로세스 개요
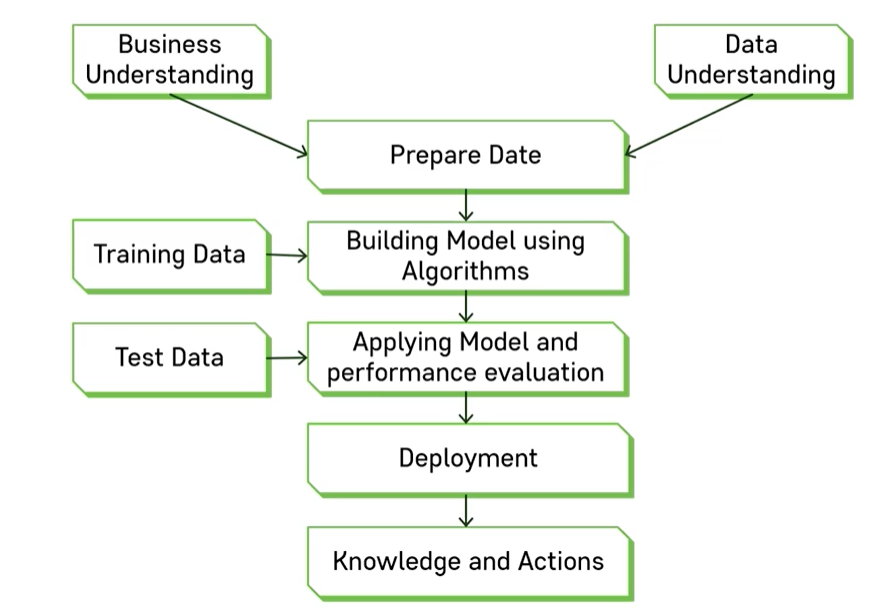
배경지식(prior knowledge) + 데이터에 대한 이해 => 데이터 준비학습 데이터 -> 함수 도출 (알고리즘을 통해 모델 생성)테스트 데이터 -> 함수를 적용하여 성능 평가Deployment (현실에 적용)적용한 것을 바탕으로 결론 도출Dataset : 정의된
3.[K-MOOC] 머신러닝 Classification
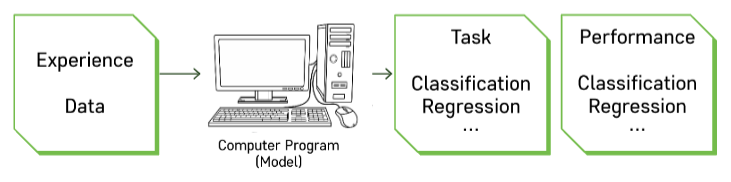
기계학습 모형이 문제를 해결해야 하는 환경/상황task가 주어지면 이를 적절한 방식으로 학습 수행성능 측정 (accuracy, error, ...)축적된 데이터 추출하여 유의미한 패턴을 찾아낸다.① 지도학습(Supervised Learning): 정답을 알려주면서 학습
4.[K-MOOC] 머신러닝 최적화
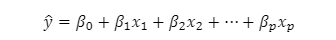
loss함수 정의 -> loss함수 최적화① 대략적인 알고리즘적 접근을 통해 손실함수가 최소화가 되도록 유도 (Heuristic)K-Nearest NeighborDecision Tree② 수학적으로 로스함수를 정의하여 최적화 (Nemerical Optimization)
5.[K-MOOC]서포트 벡터 머신(SVM)
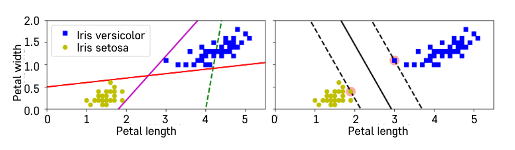
선형이나 비선형 분류, 회귀, 이상치 탐색에 사용할 수 있는 머신러닝 방법론딥러닝 이전 시대까지 널리 사용됨복잡한 분류 문제 잘 해결, 상대적으로 작거나 중간 크기를 가진 데이터에 적합최적화 모형으로 모델링 후 최적의 분류 경계 탐색두 클래스 사이에 가장 넓이가 큰 분
6.[K-MOOC]Decision Tree
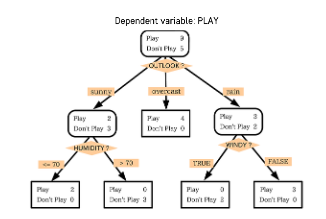
분류와 회귀 작업 및 다중 출력 작업한 번에 한 개의 변수 사용 => 정확한 예측이 가능한 규칙들의 집합 생성IF-THEN 룰에 기반해 결과물에 대한 해석이 용이일반적으로 예측 성능이 우수한 랜덤 포레스트 방법론의 기본 구조CART 훈련 알고리즘을 이용해 모델 학습데이
7.[K-MOOC]Ensemble Learning
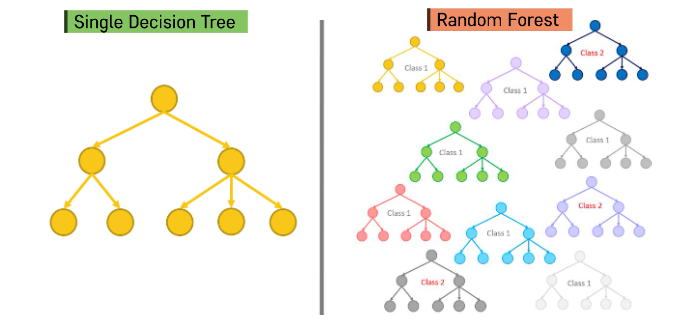
대중의 지혜 (집단 지성)무작위로 선택된 수천 명의 사람의 답이 한 명의 전문가의 답보다 좋은 경우들이 많다.일련의 분류나 회귀 모델로부터 예측을 수집하면 가장 좋은 모델 하나보다 더 좋은 예측 성능을 얻을 수 있다.일반적으로 다양한 머신러닝 기법들을 Ensemble