📝 Data Science Process
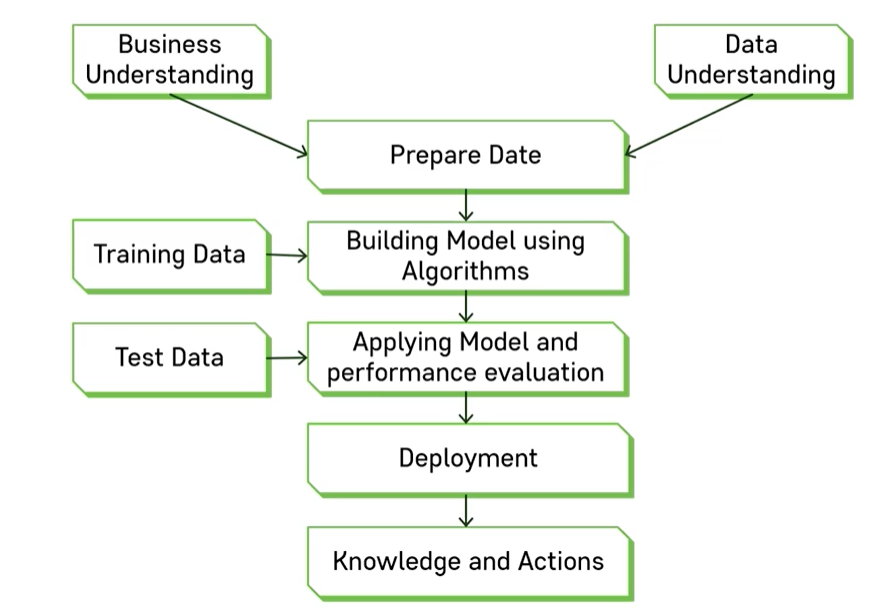
- 배경지식(prior knowledge) + 데이터에 대한 이해 => 데이터 준비
- 학습 데이터 -> 함수 도출 (알고리즘을 통해 모델 생성)
- 테스트 데이터 -> 함수를 적용하여 성능 평가
- Deployment (현실에 적용)
- 적용한 것을 바탕으로 결론 도출
* 데이터 관련 용어
- Dataset : 정의된 구조로 모아져 있는 데이터 집합
- Data Point (Observation): 데이터 세트에 속해 있는 하나의 관측치
- Feature (Variable, Attribute): 데이터를 구성하는 하나의 특성
- Label (Target, Response): 입력 변수들에 의해 예측, 분류되는 출력 변수
- 출력변수(y), 입력변수(x)
- 관측치의 개수(n, 행의 수), Feature의 개수(p, 열의 수)
📝 분류와 회귀

📝 데이터 준비 과정
-
Dataset Exploration
데이터 모델링을 하기 전에 데이터 변수 별 기본적인 특성들을 탐색하고 데이터의 분포적인 특징 이해 -
결측치(Missing Value) 처리
-
Data Types and Conversion
여러 종류의 데이터를 분석 가능한 형태로 변환 후 사용 -
정규화(Nomalization)
데이터 변수들의 단위가 크게 다른 경우 모델 학습에 영향을 줄 수 있다. -
이상치(Outliers)
관측치 중에서 다른 관측치와 크게 차이가 나는 것 -
Feature Selection
많은 변수 중에서 모델링을 할 때 중요하지 않은 변수는 제외하고 중요한 변수는 선택 -
데이터 샘플링
모델을 검증하거나 이상치를 찾는 모델링을 할 때, 앙상블 모델링을 할 때 가지고 있는 데이터를 일부 추출
📝 모델링
- Model: 입력변수와 출력변수 간의 관계를 정의해줄 수 있는 추상적인 함수 구조
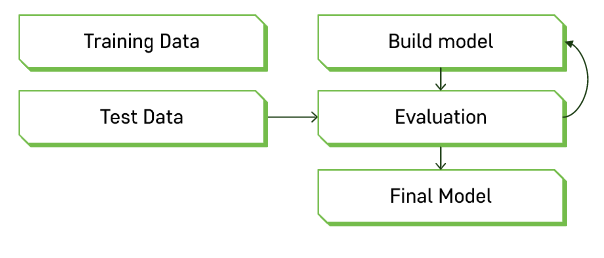
검증
-
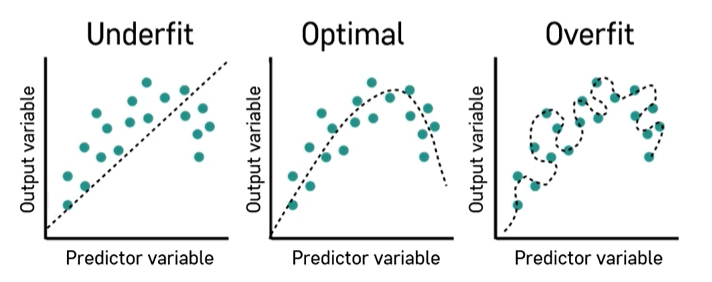
Underfit : 모형을 너무 간단하게 학습한 경우
-
Overfit : 모형을 너무 복잡하게 학습하여 일반화가 잘 되지 않는 경우
-
검증 방식
① 학습 데이터만
② 학습 데이터, 훈련 데이터
③ 학습, 검증, 훈련 데이터
④ 교차 검증
💻 실습
1. 라이브러리 불러오기
import sys
assert sys.version_info >= (3, 5)
# Scikit-Learn: 머신러닝 패키지
import sklearn
assert sklearn.__version__ >= "0.20"
import pandas as pd
import numpy as np
import os
# 시각화 라이브러리
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Ignore useless warnings (see SciPy issue #5998)
import warnings
warnings.filterwarnings(action="ignore", message="^internal gelsd")- 만든 figure를 저장하는 코드
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "end_to_end_project"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)2. 데이터 불러오기
- 링크를 통해 데이터 다운로드 & 압축 해제
import tarfile
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()fetch_housing_data()
- Pandas => 파일을 정형화된 데이터로 처리
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
print(csv_path)
return pd.read_csv(csv_path)housing = load_housing_data()
housing
housing.head()
3. 데이터 탐색 & 시각화
- 요약
housing.info()
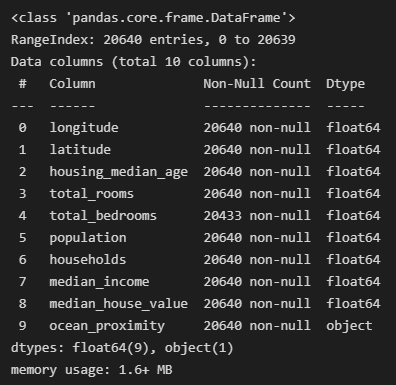
- object 데이터 확인해보기
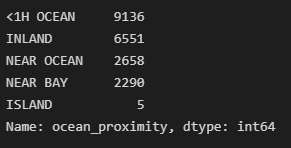
housing["ocean_proximity"].value_counts()
- 기술통계
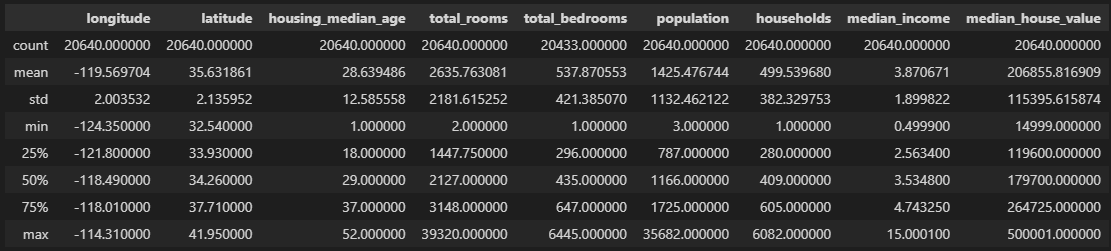
housing.describe()
- 히스토그램
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
save_fig("attribute_histogram_plots")
plt.show()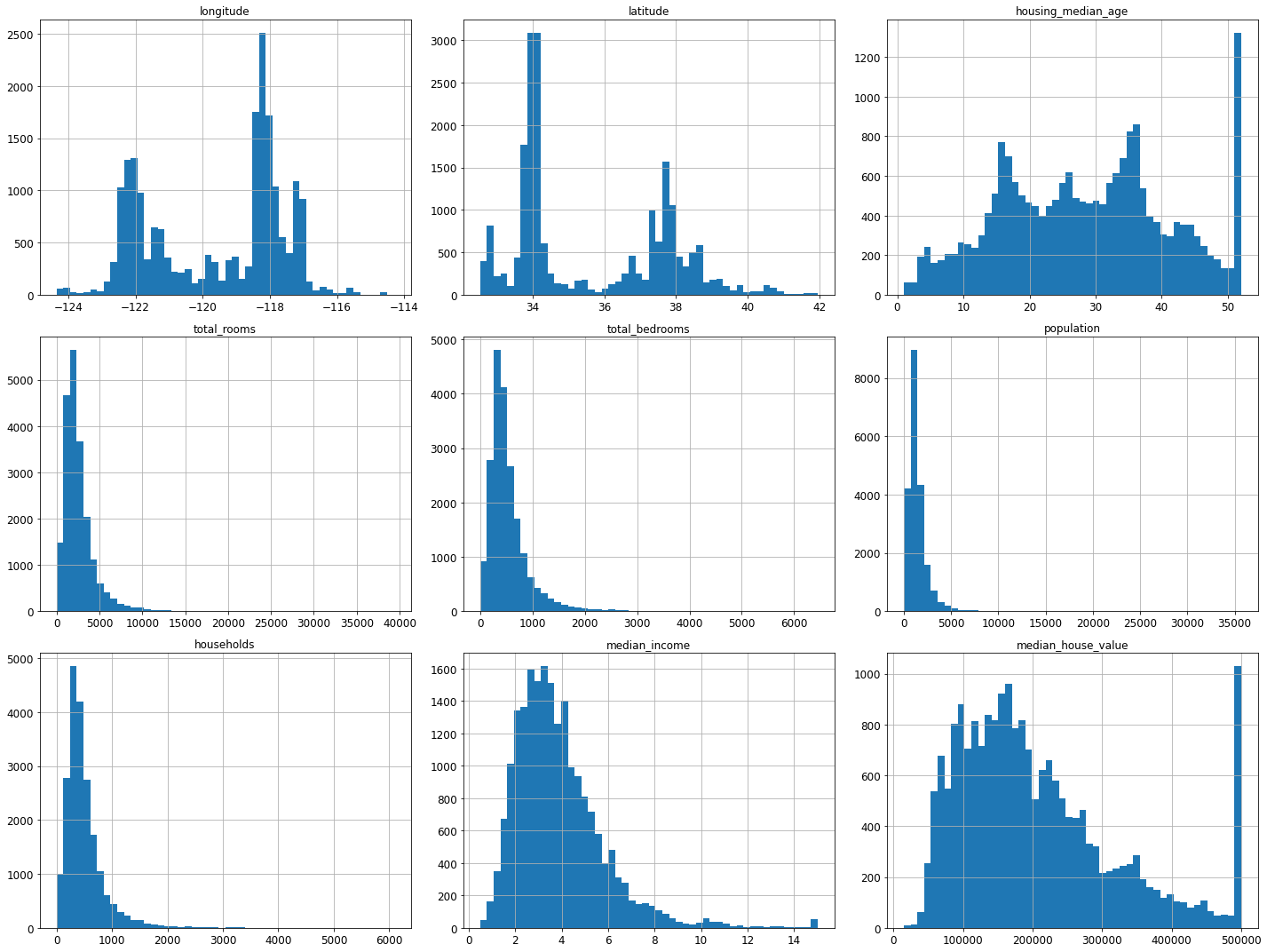
4. 데이터 나누기
# to make this notebook's output identical at every run
np.random.seed(42)# For illustration only. Sklearn has train_test_split()
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]train_set, test_set = split_train_test(housing, 0.2)

안녕하세요