📝 인공지능
과거의 인공지능
- Knwledge Engineering
- 유용한 함수를 직접 코딩하여 데이터와 함께 컴퓨터에 입력하면 컴퓨터가 이를 바탕으로 학습하여 최종적인 output을 낸다.

현재의 인공지능
- Machine Learning
- 데이터를 컴퓨터에 입력하여 function의 기본적인 형태를 알려주면 컴퓨터가 학습을 통해 스스로 유용한 함수를 만들어내고 이를 활용하여 최종적인 output을 낸다.

인공지능 & 머신러닝 & 딥러닝
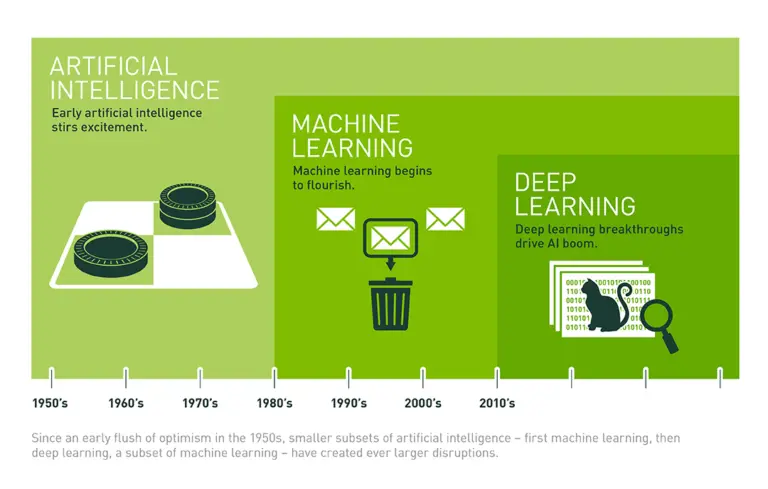
- 인공지능: 인간의 지능을 모방하여 현실 세계의 문제를 해결하는 컴퓨터 시스템
- 머신러닝: 샘플 데이터를 통해 패턴을 학습하는 인공지능 방법론
- 딥러닝: 인공신경망을 기반으로 하는 머신러닝 방법론
왜 머신러닝인가?
우리는 빅데이터 시대에 살고 있다.
머신러닝 모델을 훈련시킬 수 있는 많은 데이터들을 가지고 있다.
- CPU Computing
- 한번에 하나의 task
- 클리우드 컴퓨팅을 통해 많은 양의 컴퓨터 자원을 쉽게 사용 가능
- GPU Computing
- 보다 많은 양의 task를 한번에 처리
- 분산 작업을 통해 빠르게 쉬운 계산을 처리하여 컴퓨터 성능 향상
(GPU: 딥러닝 발전 가속화)
📝 머신러닝
정의
- 컴퓨터가 데이터를 통해 스스로 학습하고 경험을 통해 개선하도록 훈련하는 것
- 구성요소
- 환경(Environment): 머신러닝 알고리즘에 경험 제공
- 데이터(Data): 환경과 상호작용을 하면서 얻은 결과
- 모델(Model): 데이터의 패턴을 나타내는 함수
- 성능(Performance): 함수에 대한 평가 지표
종류
① 지도학습(Supervised Learning): 정답을 알려주면서 학습하는 것
- 분류 (Classification): 최종적인 output이 범주(class) 형태
- 회귀 (Regression): 최종적인 output이 연속적인 값
② 비지도학습(Unsupervised Learning)
③ 강화학습(Reinforcement Learning)
모델 평가와 성능
input변수와 output변수의 관계를 적절하게 보여주는 함수를 훈련해야 한다.
이때 적절하다는 것은 현실의 데이터와 모델의 예측값의 차이가 가장 적은 것을 말한다.
- MSE (Mean Squared Error): 회귀에서 주로 사용되는 평가지표
Linear Regression
선형회귀
- input과 output의 선형관계를 예측
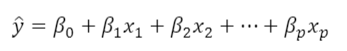
- 손실함수(loss function) 정의
- 실제 값과 예측값의 오차 제곱의 평균 (MSE)
- 제곱: +오차와 -오차를 모두 반영하기 위해
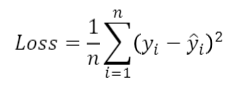
- 최적화 => 가장 작은 오차 찾기
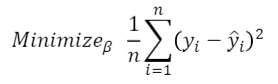
머신러닝 최적화
Minimize Loss Function
① 대략적인 알고리즘적 접근을 통해 손실함수가 최소화가 되도록 유도 (Heuristic)
- K-Nearest Neighbor
- Decision Tree
② 수학적으로 로스함수를 정의하여 최적화 (Nemerical Optimization)
- Linear Regression
- Logistic Regression
- Support Vector Machine
- Neural Network (딥러닝)
Generalization
- Training error: 학습시키는 데이터 내에서 발생하는 오차 (Loss)
- Validation error: 검증 데이터와 실제 값의 차이 (일반화 오류)
- 모델 복잡도: 데이터를 곡선으로 미세하게 표현할수록 복잡도가 높아진다.
- Overfitting(과대적합): 모형이 너무 복잡해서 불필요한 패턴까지 학습하여 일반화가 잘 되지 않음
- Underfitting(과소적합): 모형이 너무 단순해서 데이터에 들어있는 전체 패턴을 표현하지 못함
Hyperparameter
모형의 형태나 특성을 규정하는 모형의 외적인 요소
Model Validation
1. 훈련데이터만

2. 훈련, 테스트 데이터

3. 훈련, 검증, 테스트 데이터 (best)
train 데이터로 데이터 학습
-> validation 데이터에 적용
-> 하이퍼파라미터 튜닝
-> 가장 좋은 하이퍼파라미터로 test 데이터에 최종 적용

이미지 출처: https://velog.io/@guns/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EC%8A%A4%ED%84%B0%EB%94%94-2%EC%9D%BC%EC%B0%A8-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D%EC%9D%98-%EA%B0%9C%EB%85%90%EA%B3%BC-%EC%A2%85%EB%A5%98-24. 교차 검증 (Cross-Validation)
- train 데이터를 분할하여 train 데이터 내에서 번갈아가며 학습, 검증 반복
- 데이터 양이 적을 때 이용


안녕하세요