📝 Nonlinear SVM Classification
다항식 변수들을 추가함으로써 직선으로 분류할 수 있는 형태로 데이터 만들기
Polynominal Kernel
다항식의 차수를 조절할 수 있는 효율적인 계산 방법
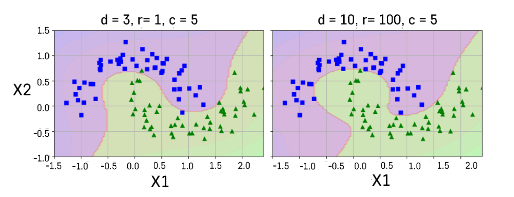
Gaussian RBF Kernel
무한대 차수를 갖는 다항식으로 차원을 확장시키는 효과
(gamma - 고차항 차수에 대한 가중 정도)

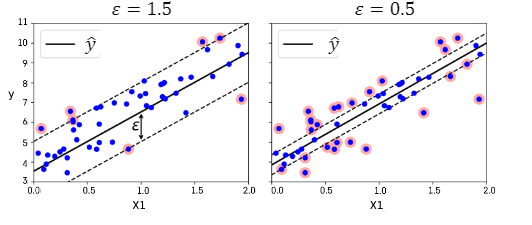
📝 SVM Regression
-
선형회귀식을 중심으로 이와 평행한 오차 한계선을 가정
-
오차한계선 너비가 최대가 되면서 오차 한계선을 넘어가는 관측치들에 페널티 부여
-
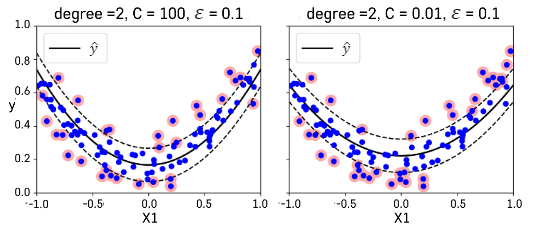
다항식 변수항을 추가하여 비선형적인 회귀모형을 적합할 수 있다.
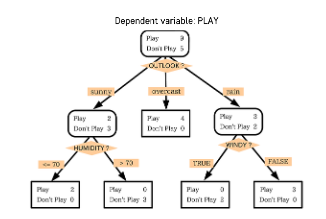
📝 의사결정나무(Decision Tree)
- 분류와 회귀 작업 및 다중 출력 작업
- 한 번에 한 개의 변수 사용 => 정확한 예측이 가능한 규칙들의 집합 생성
- IF-THEN 룰에 기반해 결과물에 대한 해석이 용이
- 일반적으로 예측 성능이 우수한 랜덤 포레스트 방법론의 기본 구조
- CART 훈련 알고리즘을 이용해 모델 학습
IF-THEN 규칙
- 데이터 공간 상에서는 각 변수를 수직 분할한 것과 동일
- 데이터 공간의 순도가 증가되게끔 영역을 구분하는 방법
- 데이터 공간을 분할해서 분류나 예측을 하기 때문에 높은 해석력
- 한계: 데이터의 작은 변화에 민감 (Ensemble로 해결)
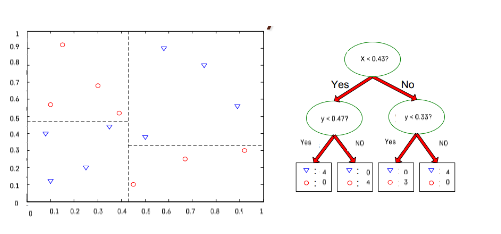
📝 Decision Tree 학습
불순도
한 노드에 속하는 샘플들의 클래스 비율을 이용하여 특정 노드가 얼마나 잘 구분이 되었는지 측정
(p : i번째 노드에 있는 훈련샘플 중 클래스 k에 속한 샘플의 비율)
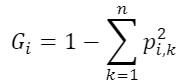
불순도 계산 실습
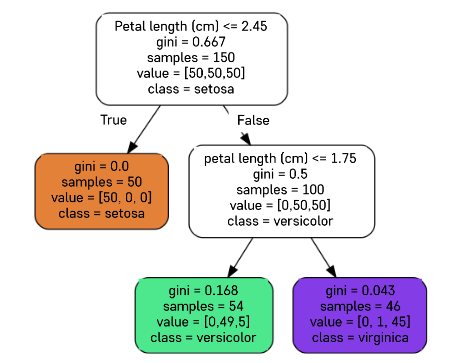
-
첫번째 노드의 불순도 (주황)
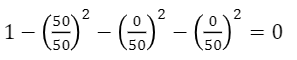
-
두 번째 노드의 불순도 (초록)
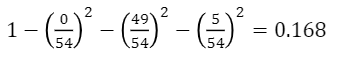
-
세 번째 노드의 불순도 (보라)
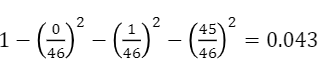
CART
- Classification And Regression Tree
- 불순도를 최소화하도록 최종 노드를 계속 이진분할하는 방법론
- 최대 깊이가 되면 중지하거나 불순도를 줄이는 분할을 찾을 수 없을 때 멈춘다.
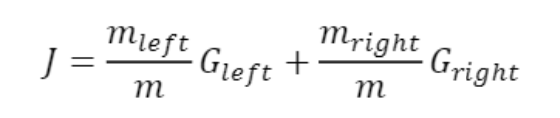
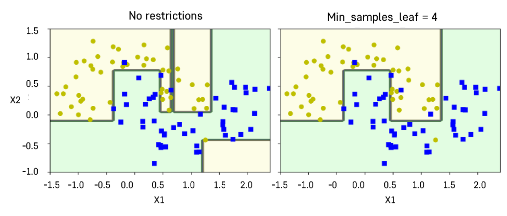
하이퍼파라미터
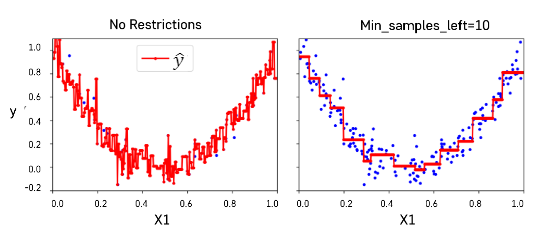
- 훈련 데이터에 대한 제약 사항이 없다 => 과대적합 위험
- max_depth: 트리의 최대 깊이 제어
- min_samples_split: 분할되기 위해 노드가 가져야하는 최소 샘플 수
- min_samples_leaf: 리프 노드가 가지고 있어야 할 최소 샘플 수
- max_leaf_nodes: 리프 노드의 최대 수
📝 Decision Tree Regression
- 각각의 노드에 속한 관측치들의 평균 타겟값(y)으로 예측
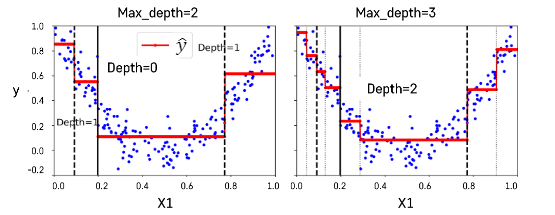
- CART 알고리즘
최대 깊이가 되면 중지하거나 오차를 줄이는 분할을 찾을 수 없을 때 멈춘다.
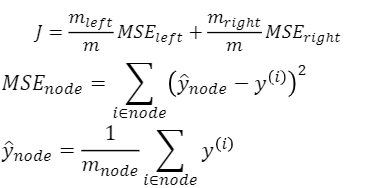

안녕하세요