Pandas
Python Data Analysis Library
파이썬에서 데이터 조작 및 분석을 하기 위해 작성된 소프트웨어 라이브러리
파이썬에서 사용하기
import pandas as pd
import를 통해서 pandas를 불러온다.
as = alias : pandas의 별명을 설정
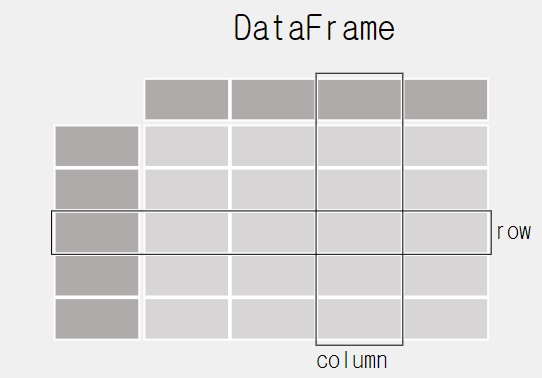
DataFrame과 Series
DataFrame: 행렬, 2차원구조
Series: 벡터, 1차원 구조

1. DataFrame 생성하기
빈 프레임 생성
df = pd.DataFrame()
2. 컬럼 생성하기
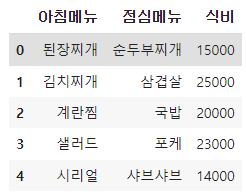
df["아침메뉴"] = ["된장찌개", "김치찌개", "계란찜", "샐러드", "시리얼"]

3. 컬럼 추가하기
df["점심메뉴"] = ["순두부찌개", "삼겹살", "국밥", "포케", "샤브샤브"]

df["식비"] = 20000
값을 하나만 입력해주면 모든 행에 공통적으로 작성된다.

df["아침메뉴"]
컬럼 하나만 가져오면 시리즈 형태로 출력된다


4. 컬럼 값 변경하기
컬럼 추가/생성할 때와 같은 방식으로 값을 변경할 컬럼에 데이터를 입력해준다.
df["식비"] = [15000, 25000, 20000, 23000, 14000]
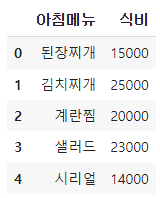
5. 컬럼 삭제하기
df = df.drop("아침메뉴", axis=1)
*drop()을 사용할 때는 df에 drop결과를 할당해주어야 컬럼 삭제가 완료된다.
*axis=0: 행, axis=1: 열

6. 데이터 요약하기
df.info() : 데이터프레임의 정보 출력
df.shape : (행, 열) 형태로 데이터프레임의 크기 출력
df.dtypes : 데이터의 타입만 출력
df.describe : 데이터프레임의 요약 정보 출력
-수치형 데이터의 기술통계 값
-개수, 평균, 편차, 최소값, 사분위수, 최대값
df.describe(include="object")
-범주형 데이터의 기술통계 값
-빈도수, 고유값, 최빈값, 최빈값의 빈도수
7. 데이터 가져오기
컬럼명으로 데이터 가져오기
df["점심메뉴"]
2개 이상의 컬럼 가져오기
리스트 자료형 이용
df[["메뉴", "식비"]]
행을 기준으로 데이터 가져오기
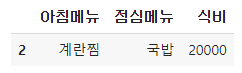
df.loc[0]

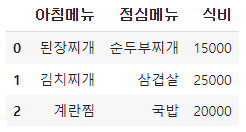
여러 개 가져오기:
df.loc[[0, 1, 2]]
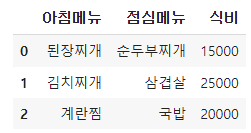
슬라이싱 사용:
df.loc[0:2]
행과 열 함께 가져오기
df.loc[0, "점심메뉴"]
-> 결과 : '순두부찌개'
여러 개 가져오기
df.loc[[0, 1, 2], "점심메뉴"]

특정 데이터가 포함된 행 가져오기
df[df["아침메뉴"].str.contains("계란찜")]
8. bool indexting
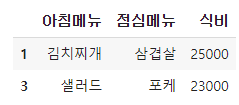
df["식비"]>20000

위 결과를 인덱스로 활용하면 True에 해당하는 데이터만 출력된다.
df[df["식비"]>20000]
9. 정렬하기
df.sort_values("컬럼명") : 오름차순 정렬
df.sort_values(by="컬럼명", ascending=False) : 내림차순 정렬
정렬 기준을 여러 개 설정하기
df.sort_values(by=["아침메뉴", "식비"], ascending=[True])
-> 정렬 기준과 정렬 방식의 개수가 맞지 않아 Error
df.sort_values(by=["아침메뉴"], ascending=[True, False])
-> 정렬 기준과 정렬 방식의 개수가 맞지 않아 Error
df.sort_values(by=["아침메뉴", "식비"], ascending=True)
-> 아침메뉴, 식비 모두 오름차순 정렬
df.sort_values(by=["아침메뉴"], ascending=[True])
-> 아침메뉴만 오름차순 정렬
df.sort_values(by=["아침메뉴", "식비"], ascending=[False, True])
-> 아침메뉴는 내림차순, 식비는 오름차순 정렬
10. 파일
파일로 저장하기
df.to_csv("drug.csv", index=False)
*index=False : index 컬럼을 생성하지 않음
저장된 파일 불러오기
pd.read_csv("drug.csv")
