앤스컴 콰르텟
기술통계량은 유사하지만 분포나 그래프는 매우 다른 4개의 데이터셋
시각화의 중요성, 특이치 및 주영향관측값의 영향을 보여주기 위해 만들어진 데이터셋
앤스컴콰르텟_위키백과
1. 라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns2. 데이터 로드
직접 불러오기
df = sns.load_dataset("anscombe")
url을 통해 불러오기
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/anscombe.csv")
3. 데이터 확인하기
처음 5개의 행 확인
df.head()
마지막 5개의 행 확인
df.tail()
무작위로 하나의 행 확인
df.sample()
위의 함수들 모두 괄호 안에 숫자를 입력하여 원하는 행의 수만큼 출력할 수 있다.
4. 기본 정보 보기
요약 정보
- column 개수
- null이 아닌 값의 수
- 데이터 타입
- 메모리 사용량
df.info()

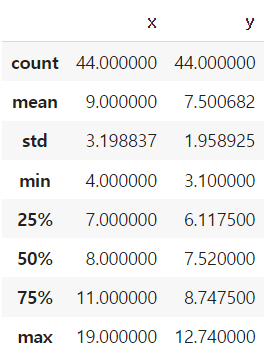
기술통계_수치형 데이터
df.describe
- 빈도수
- 평균
- 표준편차
- 최소값, 최대값
- 사분위수
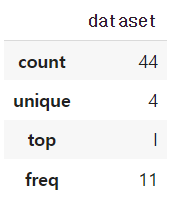
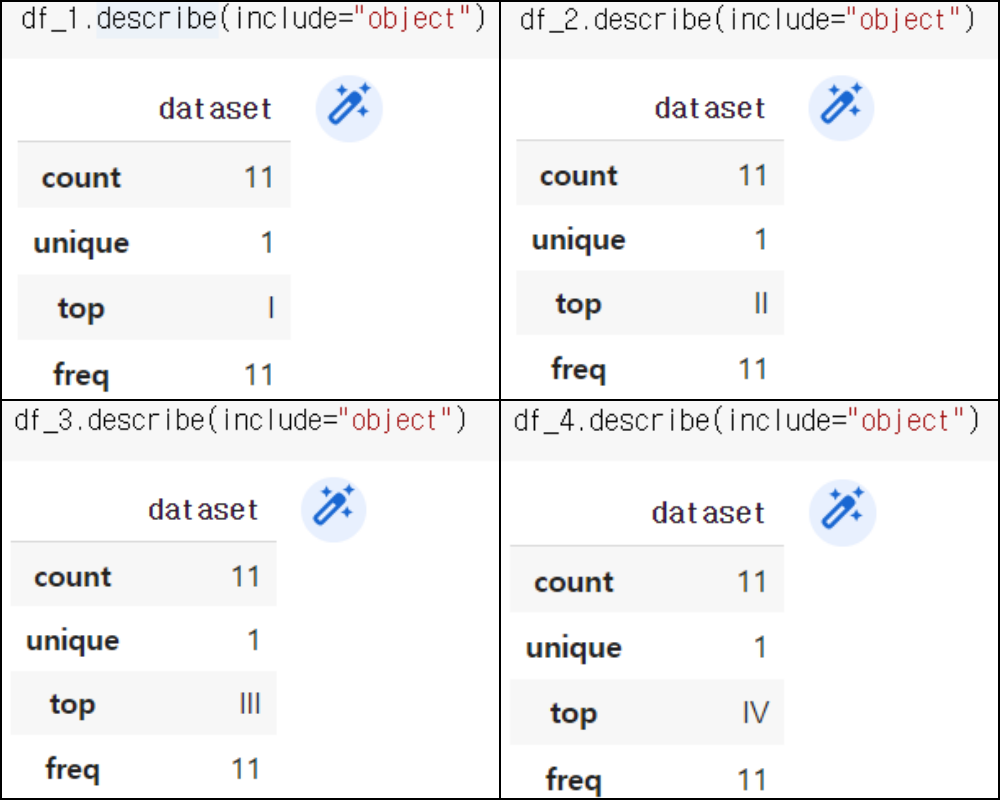
기술통계_범주형 데이터
df.describe(include="object")
- 빈도수
- 유일값
- 최빈값
- 최빈값의 빈도수
유일값 확인
df.nunique()
-컬럼별 유일값 개수

df["dataset"].unique()
-"dataset" 컬럼의 유일값 출력
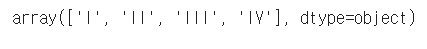
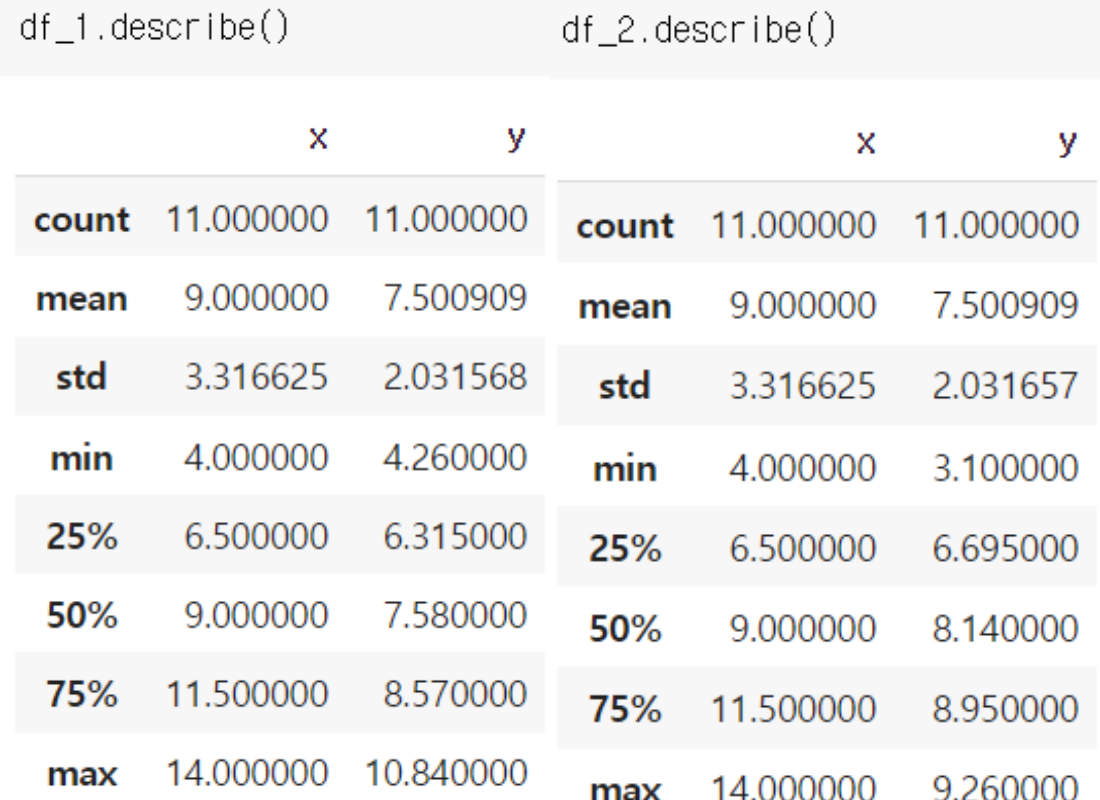
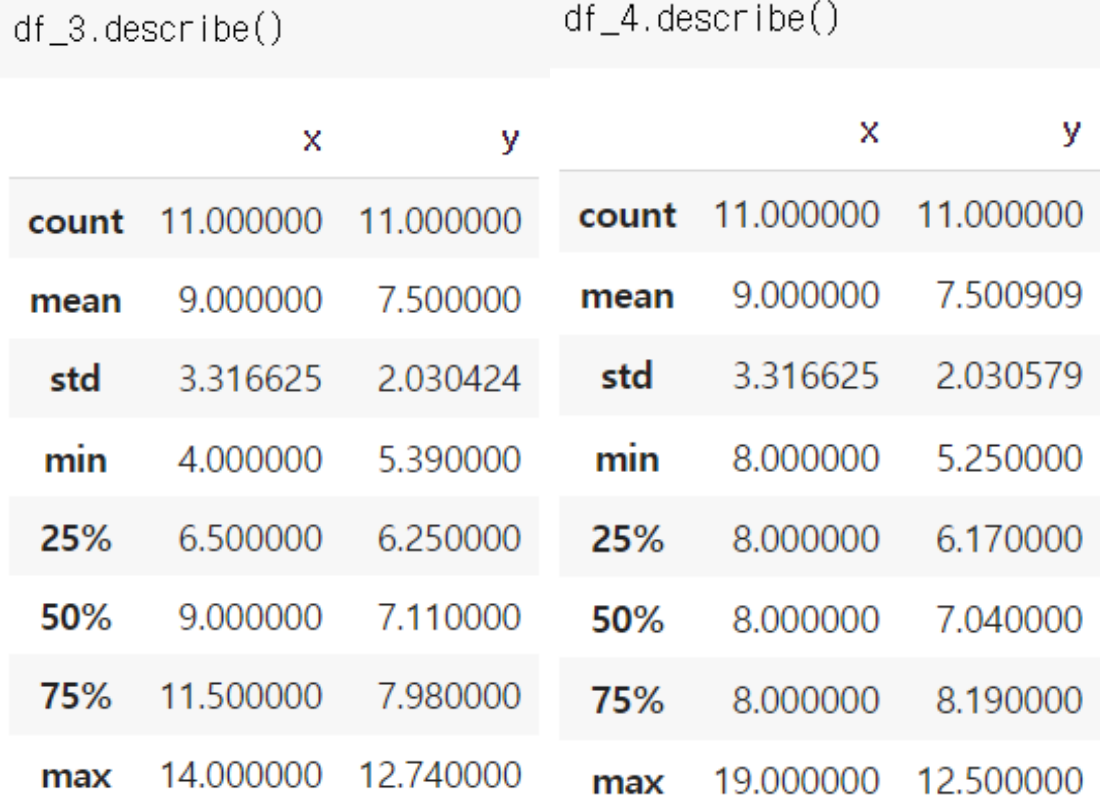
개별 데이터셋의 기술통계
데이터셋 나누기
"dataset" 컬럼에 따라 네 가지 데이터셋으로 나눈다.
# bool indexing 이용하기
df_1 = df[df["dataset"] == "I"]
df_2 = df[df["dataset"] == "II"]
df_3 = df[df["dataset"] == "III"]
df_4 = df[df["dataset"] == "IV"]기술통계
describe()
describe(include="object")
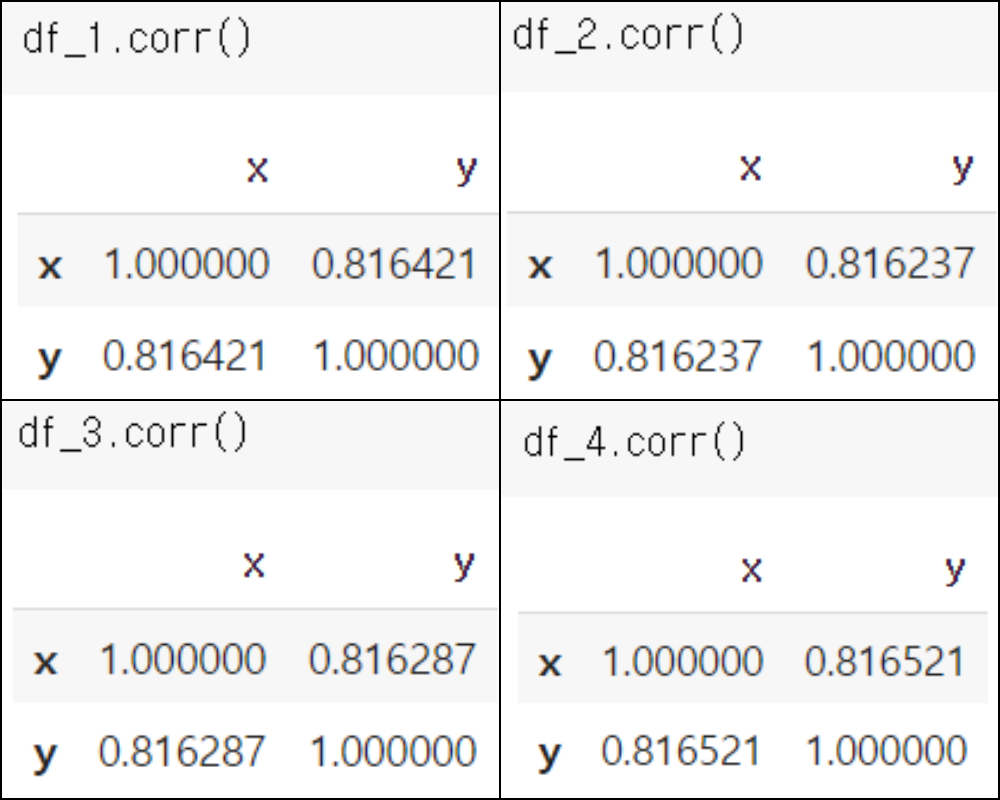
상관계수
corr()
빈도수
df["dataset"].value_counts()

df["dataset"].value_counts(normalize=True)
-빈도수의 비율 구하기

Groupby를 통한 기술통계
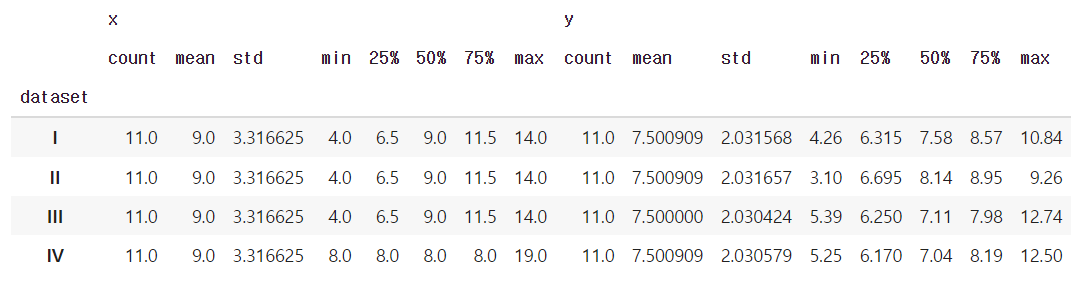
dataset별 x, y의 기술통계
df.groupby("dataset").describe()
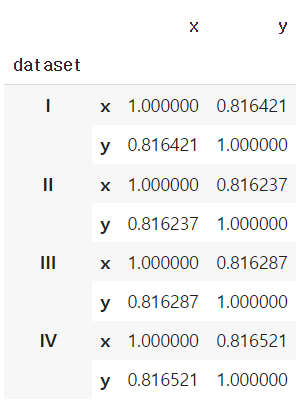
dataset별 상관계수
df.groupby("dataset").corr()

안녕하세요