Scikit-learn : python을 대표하는 머신러닝 라이브러리
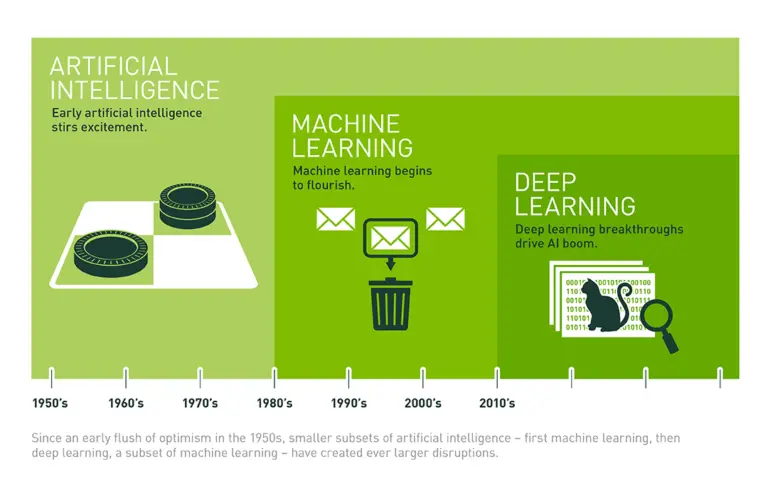
머신러닝 알고리즘 유형
지도학습
- 정답이 주어지는 학습 방식
- 선형회귀, 정규화, 로지스틱 회귀, 서포트 벡터 머신, 커널 기법을 적용한 서포트 벡터 머신, 나이브 베이즈 분류, 랜덤 포레스트, 신경망, k-최근접 이웃 알고리즘
범주형 : 분류
- 개체가 속한 범주 식별
- 적용 : 스팸 감지, 이미지 인식
- 알고리즘 : SVM, nearest neighbors, 랜덤포레스트 등
수치형 : 회귀
- 개체와 연결된 연속 값 속성 예측
- 적용 : 약물 반응 수치, 주가 예측
- 알고리즘 : SVR, nearest neighbors, 랜덤포레스트 등
비지도학습
- 정답이 주어지지 않는 학습 방식
- 주성분 분석, 잠재 의미 분석, 음수 미포함 행렬 분해, 잠재 디리클레 할당, k-평균 알고리즘, 가우시안 혼합 모델, 국소 선형 임베딩, t-분포 확률적 임베딩
범주형 : 군집화
- 유사한 개체를 세트로 자동 그룹화
- 적용 : 고객 세분화, 실험 결과 그룹화
- 알고리즘 : k-means, spectral clustering, mean-shift 등
수치형 : 차원축소
- 고려할 확률 변수의 수를 줄임
- 적용 : 시각화, 효율성 향상
- 알고리즘 : PCA, feature selection, non-negative matrix factorization 등
머신러닝 과정
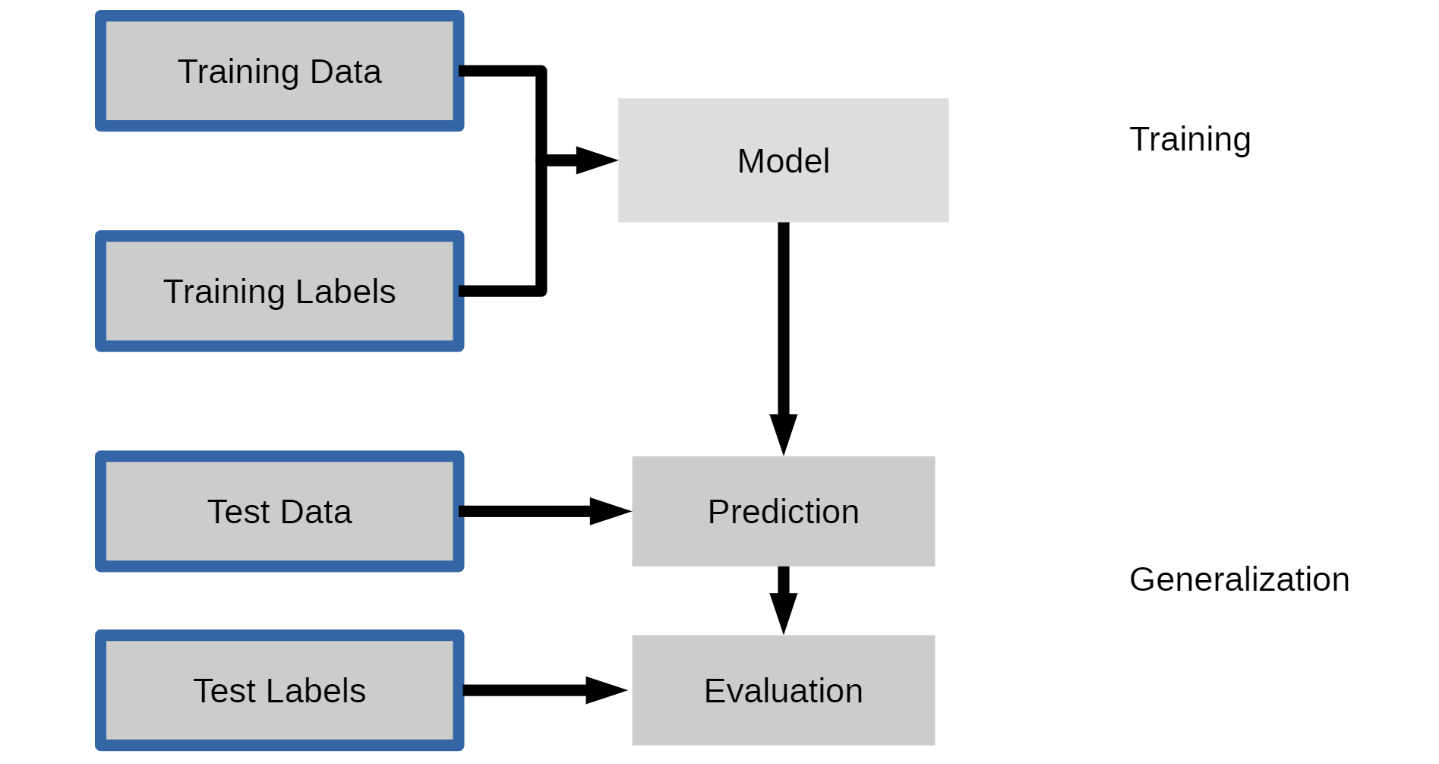
지도학습
-Training Data와 Training Labels를 통해 모델 생성
-Test Data의 결과를 모델을 통해 예측
-Test Labels와 예측 결과를 비교하여 평가
scikit-learn 개발자 안드레아스 밀러가 만든 슬라이드
1. 데이터 불러오기
2. 데이터 전처리
참고 : Data Preprocessing Concepts with Python
- 정규화
- 이상치 처리
- Scaling
- 결측치 처리
- Encoding
3. Feature Engineering
: Feature Selection, Feature Extraction, Feature Transform & Scaling
4. 모델링
5. Fit / Predict
6. Evaluation
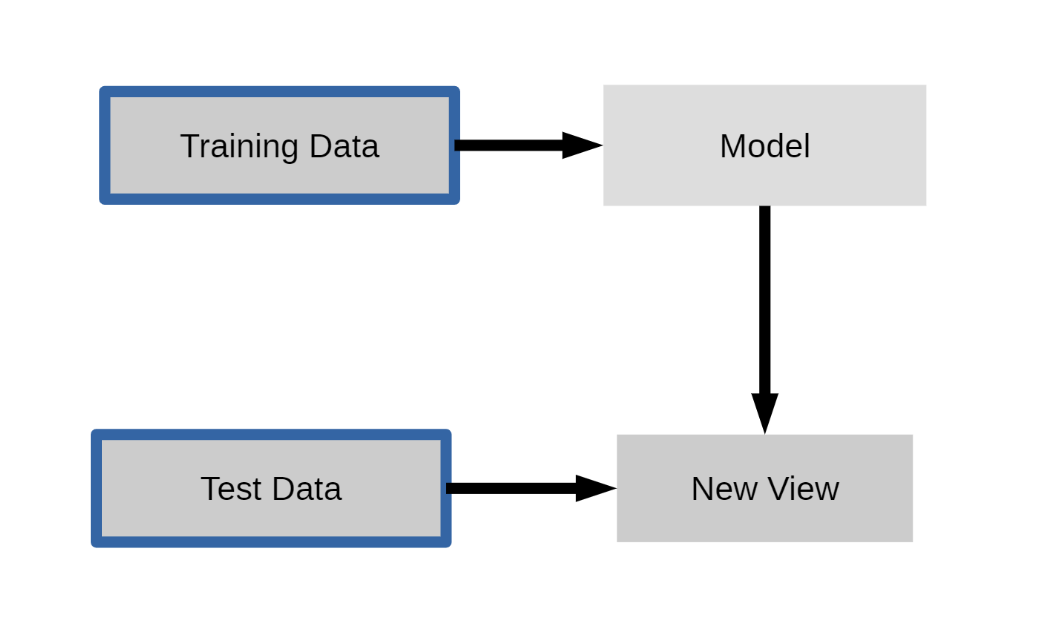
비지도학습
-Training Data를 통해 비슷한 것끼리 묶거나 차원 축소하여 모델 생성
-Test Data에 모델 적용
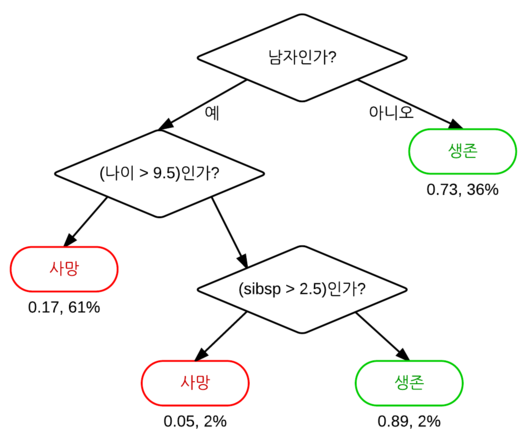
결정 트리 학습법 (Decision tree learning)
어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델
분류트리 : 트리 모델 중 목표 변수가 유한한 수의 값을 가짐
회귀트리 : 결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수
장점
- 결과를 해석하고 이해하기 쉽다.
- 자료를 가공할 필요가 거의 없다.
- 수치 자료와 범주 자료 모두에 적용할 수 있다.
- 화이트박스 모델을 사용한다.
=> 모델에서 주어진 상황이 관측 가능하다면 bool 논리를 이용하여 조건에 대해 쉽게 설명할 수 있다.
(블랙박스모델 : 인공신경망과 같이 결과에 대한 설명을 이해하기 어려운 것) - 안정적이다.
- 대규모의 데이터셋에서도 잘 동작한다.
과소적합 (Underfitting)
모델이 충분히 복잡하지 않고, 최적화가 제대로 수행되지 않아서 학습 데이터의 구조나 패턴을 정확히 반영하지 못하는 것
과대적합 (Overfitting)
모델을 지나치게 복잡하게 학습하여 학습 데이터셋에서는 성능이 높게 나타나지만 새로운 데이터에 대해서는 정확한 예측이나 분류를 수행하지 못하는 것


안녕하세요