데이터셋 출처
데이터 구성
- Pregnancies : 임신 횟수
- Glucose : 2시간 동안의 경구 포도당 내성 검사에서 혈장 포도당 농도
- BloodPressure : 이완기 혈압 (mm Hg)
- SkinThickness : 삼두근 피부 주름 두께 (mm), 체지방을 추정하는데 사용되는 값
- Insulin : 2시간 혈청 인슐린 (mu U / ml)
- BMI : 체질량 지수 (체중kg / 키(m)^2)
- DiabetesPedigreeFunction : 당뇨병 혈통 기능
- Age : 나이
- Outcome : 768개 중에 268개의 결과 클래스 변수(0 또는 1)는 1이고 나머지는 0입니다.
1. 라이브러리 로드
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt2. 데이터 로드
df = pd.read_csv("http://bit.ly/data-diabetes-csv")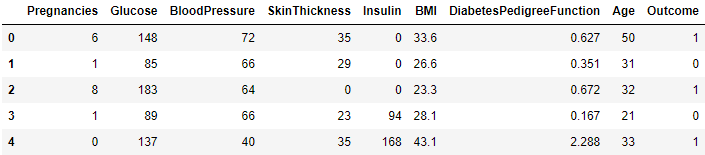
3. 전처리
- 인슐린이 0인 값을 중앙값으로 대체하기 : median() 이용
- 평균값으로 대체하려면 : mean() 이용
insulin_median = df[df["Insulin"] > 0].groupby("Outcome")["Insulin"].median()
df["Insulin_fill"] = df["Insulin"]
df.loc[(df["Outcome"] == 0) & (df["Insulin_fill"] == 0), "Insulin_fill"] = insulin_median[0]
df.loc[(df["Outcome"] == 1) & (df["Insulin_fill"] == 0), "Insulin_fill"] = insulin_median[1]
4. 학습, 예측 데이터셋 나누기
4-1. 정답값이자 예측해야 할 값
label_name = "Outcome"
4-2. 학습, 예측에 사용할 컬럼
- 데이터프레임의 컬럼들을 모두 가져오기
- 전처리되지 않은 'Insulin' 컬럼과 정답값이 있는 'Outcome' 컬럼 제거
feature_names = df.columns.tolist()
feature_names.remove("Insulin")
feature_names.remove("Outcome")
feature_names: ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Insulin_fill']
4-3. feature와 label 나누기
- X : feature, 독립변수
- y : label, 종속변수
X = df[feature_names]
y = df[label_name]4-4. 학습, 예측 데이터셋 만들기
- X_train : Training Data
- y_train : Training Label
- X_test : Test Data
- y_test : Test Label
- sklean의 train_test_split을 통해 무작위로 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)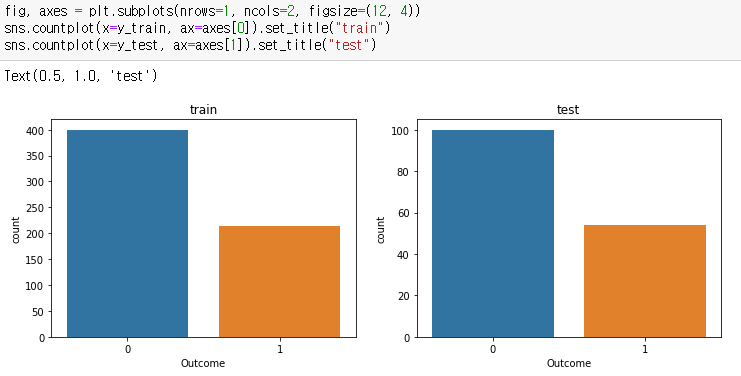
5. 머신러닝 모델
결정트리
- 결과를 해석하고 이해하기 쉽다.
- 자료를 가공할 필요가 거의 없다. (정규화, 임의 변수 생성, 결측치 처리 등)
- 수치 자료와 범주 자료 모두 적용 가능
- 화이트박스 모델 사용 => 모델에서 주어진 상황이 관측 간으하다면 Bool 논리를 이용하여 조건에 대해 쉽게 설명 가능
(블랙박스 모델 : 결과에 대한 설명을 이해하기 어렵다, 인공신경망이 대표적) - 대규모의 데이터 셋에서도 잘 동작 => 방대한 분량의 데이터를 일반적인 컴퓨터 환경에서 합리적인 시간안에 분석 가능
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42)DecisionTreeClassifier
Scikit-learn DecisionTreeClassifier
DecisionTreeClassifier(
*,
criterion='gini',
splitter='best',
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0,
)주요 파라미터
- criterion : 가지의 분할의 품질 측정 {"gini", "entropy", "log_loss"}
- max_depth : 트리의 최대 깊이
- min_samples_split : 내부 노드를 분할하는 데 필요한 최소 샘플 수
(int=최소 숫자, float=각 분할에 대한 최소 샘플 수) - min_samples_leaf : 리프 노드에 있어야 하는 최소 샘플 수
- max_leaf_nodes : 리프 노드 숫자의 제한치
- random_state : 추정기의 무작위성 제어 (실행했을 때 같은 결과가 나오도록 합니다.)
- max_features : feature를 얼마나 사용할 것인지
(int형 입력: feature의 수, float형 입력: 비율)
6. 하이퍼파라미터 튜닝
하이퍼파라미터 (Hyper Parametrer)
- 머신러닝 모델을 생성할 때 사용자가 직접 설정하는 값
- 모델의 성능을 좌우한다.
수동 튜닝
- 하이퍼파라미터를 직접 설정하여 만족할 만한 조합을 찾아나간다.
GridSearchCV()
- 모델의 하이퍼파라미터 후보군들을 완전 탐색하여 하이퍼파라미터 검색
- 조합의 수만큼 실행
- 장점 : 하이퍼파라미터의 수치를 지정하면 모든 수치별 조합을 검증하여 최적의 파라미터 검색의 정확도 향상
- 단점 : 후보군의 개수가 많을수록 기하급수적으로 찾는 시간이 늘어나며 후보군들을 정확히 설정해야할 필요가 있다.
RandomizedSearchCV()
- GridSearch와 동일한 방식으로 사용하지만 모든 조합 X
- 정해진 횟수(n_iter) 안에서 정의된 하이퍼파라미터의 후보군들로부터의 조합을 랜덤 샘플링- 하여 최소의 오차를 갖는 모델의 하이퍼파라미터를 검색
- (k-fold 수 * n_iter 수) 만큼 실행
- 장점 : 무작위로 값을 선정하고 그 조합을 검증 => 빠른 속도로 최적의 파라미터 조합 검색
- 단점 : 후보군을 신중하게 결정해야한다.
- 랜덤한 조합들로부터 최적의 하이퍼파라미터를 찾는다는 보장이 없음
- 횟수를 늘리면 시간도 비례하여 증가
6-1. GridSearchCV
GridSearchCV(estimator,
param_grid,
*,
scoring=None,
n_jobs=None,
refit=True,
cv=None,
verbose=0,
pre_dispatch='2*n_jobs',
error_score=nan,
return_train_score=False)주요 파라미터
- estimator : 평가할 모델
- param_grid : 튜닝을 위한 파라미터 목록의 딕셔너리 형태
- scoring : 예측 성능을 측정할 평가 방법 입력
- 분류 알고리즘 : 'accuracy' , 'f1'
- 회귀 알고리즘 : 'neg_mean_squared_error' , 'r2' - n_jobs : 사용할 코어 설정 (-1 : 모두 사용)
- refit : True -> 최적의 하이퍼파라미터를 찾아 estimator를 재학습시킨다.
- cv : 교차검증에서 분할 개수 지정
- verbose : 로그 표시
- [> 1] : 각 fold와 파라미터 후보의 계산시간 표시
- [> 2] : 점수도 표시
- [> 3] : fold 및 파라미터 후보의 인덱스도 계산 시작 시간과 함께 표시 - pre_dispatch : 병렬실행 중 디스패치되는 작업의 수
- error_score : 오류가 발생하는 경우 점수에 할당할 값 (raise / 숫자 / np.nan)
- returntrain_score : False -> cv_results 속성에 훈련 점수가 포함되지 않는다.
# 트리의 깊이 설정
max_depth = list(range(3, 20, 2))
# max_features의 비율 설정
max_features = [0.3, 0.5, 0.7, 0.8, 0.9]
# 딕셔너리 형태로 저장
parameters = {"max_depth":max_depth, "max_features":max_features}
from sklearn.model_selection import GridSearchCV
clf = GridSearchCV(model, parameters, n_jobs=-1, cv=5)
clf.fit(X_train, y_train)-
bestscore : 예측 정확도
clf.best_score_
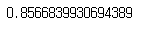
-
bestestimator : 최고 성능 모델
clf.best_estimator_
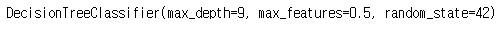
결과를 데이터프레임으로 확인하기
- cvresults : 결과 데이터
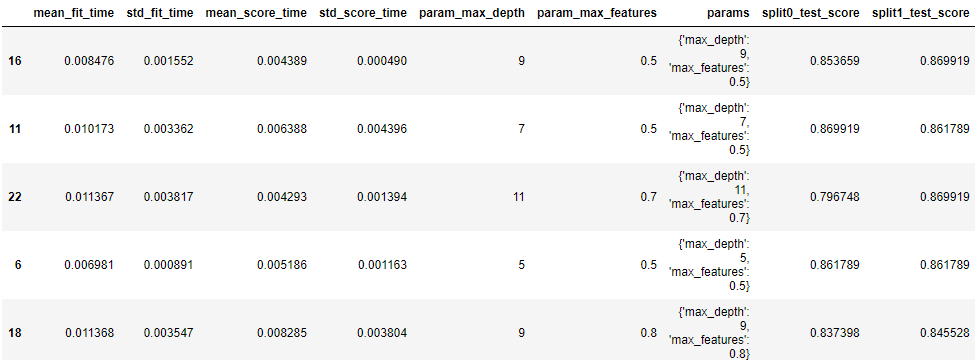
pd.DataFrame(clf.cv_results_).sort_values("rank_test_score")
{
'param_kernel', 'param_gamma', 'param_degree',
'split0_test_score', 'split1_test_score', 'mean_test_score', 'std_test_score', 'rank_test_score',
'split0_train_score', 'split1_train_score', 'mean_train_score', 'std_train_score',
'mean_fit_time', 'std_fit_time', 'mean_score_time', 'std_score_time', 'params'
}
6-2. RandomizedSearchCV
Scikit-learn RandomizedSearchCV
RandomizedSearchCV(estimator,
param_distributions,
*,
n_iter=10,
scoring=None,
n_jobs=None,
refit=True,
cv=None,
verbose=0,
pre_dispatch='2*n_jobs',
random_state=None
error_score=nan,
return_train_score=False)주요 파라미터
- pram_distributions : 파라미터 목록의 딕셔너리 형태
- n_iter : 반복 실행 횟수
- random_state : random seed 값 => random 값 고정
from sklearn.model_selection import RandomizedSearchCV
param_distributions = {"max_depth":np.random.randint(3, 20, 10), "max_features":np.random.uniform(0.5, 1, 10)}
clfr = RandomizedSearchCV(model, param_distributions=param_distributions, scoring="accuracy", n_jobs=-1, n_iter=10, cv=5, random_state=42, verbose=1)
clfr.fit(X_train, y_train)- bestestimator : 최고 성능 모델
clfr.best_estimator_ - bestparams : 최적의 파라미터
clfr.best_params_ - bestscore : 예측 정확도
clfr.best_score_
결과를 데이터프레임으로 확인하기
- cvresults : 결과 데이터
pd.DataFrame(clfr.cv_results_).nsmallest(5, "rank_test_score")
7. Best Estimator
학습 시키기
-
GridSearchCV
best_model = clf.best_estimator_ -
RandomizedSearchCV
best_model = clfr.best_estimator_ -
데이터를 머신러닝 모델로 학습시킨다.
best_model.fit(X_train, y_train)
예측하기
y_predict = best_model.predict(X_test)
8. 모델 평가하기
8-1. 모델 feature 중요도 확인
best_model.feature_importances_
sns.barplot(x=best_model.feature_importances_, y=best_model.feature_names_in_)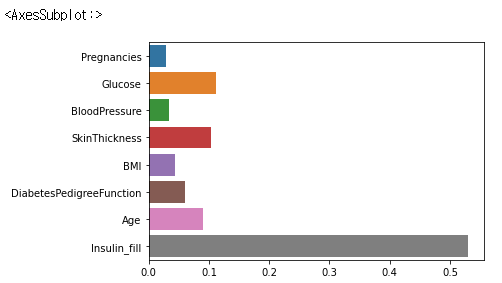
8-2. 점수 측정
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)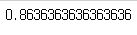
from sklearn.metrics import classification_report
print(classification_report(y_test, y_predict))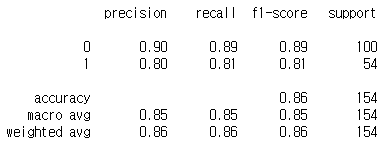

안녕하세요