[Paper Review] FCN: Fully Convolutional Networks for Semantic Segmentation
논문리뷰 Computer Vision
.png)
논문 링크 : Fully Convolutional Networks for Semantic Segmentation
FCN : Fully Convolutional Network
- 최초의 딥러닝 기반 segmentation 모델
- 대부분의 딥러닝 기반 segmentation 모델들이 FCN 구조를 기반으로 함
Abstract
-
Convolutional Network 는 단계별 hirerarchical feature 를 뽑아내는 강력한 visual model
-
end-to-end , pixel-to-pixel 로 학습한 Convolutional network → Semantic segmentation 에서 최첨단 기술을 능가함
-
end-to-end
→ Segmentation 을 위해 사용되는 filter들이 learnable 함
→ 독립적인 딥러닝 모델을 이용하지 않고(not cascade), 하나의 딥러닝 모델 이용end-to-end 가 아닌 모델 예시
- 전통적인 pattern recognition 모델 → 사람이 미리 filter을 설계 → not learnable
- cascade 방식의 모델 → 순차적, 단계적 모델
→ Segmentation을 할때, 먼저 관심 영역을 detection 하고 해당 영역을 segmentation 하도록 설계 → object detection 모델과 segmentation 모델을 각각 독립적으로 사용
- 전통적인 pattern recognition 모델 → 사람이 미리 filter을 설계 → not learnable
-
pixel-to-pixel
→ 이미지의 pixel 마다 classification 학습을 진행
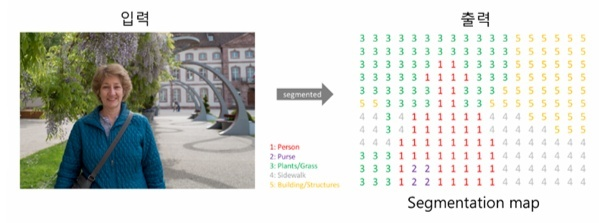
→ 따라서 이 논문에서 최종 segmentation 결과가 모든 pixel을 classification 하는 방식인 dense prediction task 라고 설명
-
-
semantic information 과 apperance information 을 결합하여 사용
-
Semantic information (의미론적 정보) from deep, coarse layer
→ deep 한 layer에서 뽑은 feature 들은 외관을 파악하기 힘듦
→ 하나의 의미를 갖는 정보들을 보여줌
→ coarse 는 굵다(세밀하지않음) 라는 뜻 ↔ fine 과 반의어 -
Appearance information (외관 정보) from shallow, fine layer
→ CNN 의 초기 layer 들은 보통 edge feature들이 추출됨
→ 세밀한 feature 들을 잘 추출하여 fine layer 라고 함
-
Introduction
-
CNN의 등장으로 classification task, local task(ex. object detection, key-point detection (landmark detection), local correspondence) 같은 recognition 분야 엄청 발전
- 여기서 local correspondence 는 pixel 간의 주변(local) 정보를 고려하여 학습하는 것
-
전체 이미지(=coarse)를 기반으로 task 수행 x → pixel 마다(=fine) classification 해주는 dense prediction 수행
→ pixel 마다 labeling 필요 → supervised learning 기반 학습
-
FCN
→ end-to-end, pixel-to-pixel 기반의 semantic segmentation
→ 사이즈 제약을 받지 않는 입력 이미지 (arbitrary-sized inputs) 에서 dense prediction 수행
→ pixelwise prediction, supervised pre-training 이용
→ dense feedfoward computation 과 backpropagation 을 통해 전체 이미지에 대한 학습과 추론을 한번에 수행
→ upsampling layer 는 subsampled pooling 을 사용하여 pixelwise prediction 및 학습을 가능하게함- FCN 이전의 segmentation 학습 방법론
-
Patchwise learning
→ 특정 크기의 patch를 설정해주고 CNN에 입력 → 입력으로 들어간 patch는 CNN 에 의해 classification → 특정 class로 분류 되었다면, 해당 patch 중앙에 위치한 pixel을 해당 class로 분류→ 이러한 과정을 sliding window 방식으로 반복
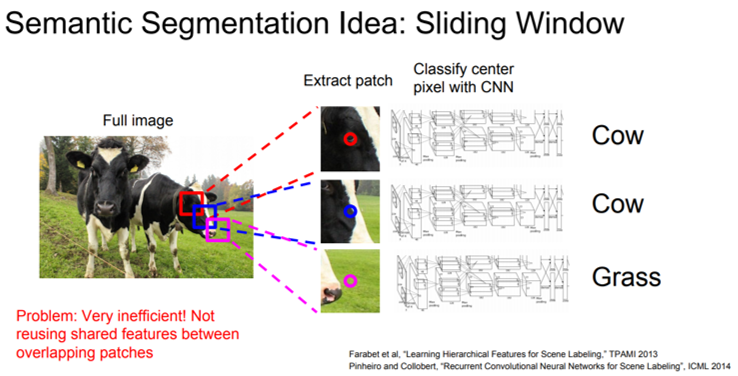
Patchwise learning 문제점
→ 모든 patch들을 cnn에 넣어 일일이 분류→ 계산량이 너무 많음
→ patch 크기를 키우면 두 개의 class가 동시에 들어가 있을 경우 → classification 애매함, patch 끼리 겹치는 부분이 커져 중복 계산
→ patch 크기 줄이면 low resolution → classification accuracy 가 떨어짐
-
Pixelwise learning
→ 전체 이미지를 CNN에 넣어 Pooling 과정 없이 feature을 추출 → 결과 C(class) x H x W 형태 (classification scores map) → 각 픽셀 위치에 제일 높은 class score에 맞는 색 할당→ 최종 결과 H x W (prediction map)
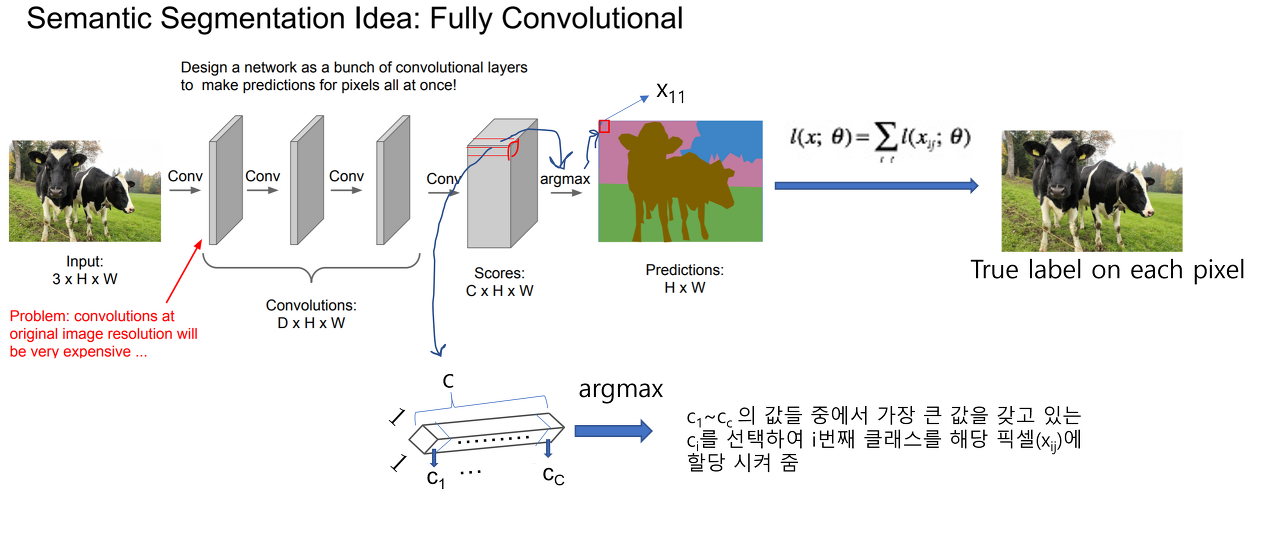
Pixelwise learning 문제점
→ layer 가 깊어질수록 계산량이 상당히 증가
→ 구조적인 hierarchical feature를 뽑지못함
→ 이러한 문제점을 해결하기 위해 FCN 고안
FCN의 encoder 부분을 기존 CNN 방식처럼 수행하고, decoder(=upsampling) 부분을 붙여 segmentation 수행
- 위의 문제들 이외 FCN 이전 segmentation 모델을 사용할때 전,후처리(superpixels, proposals, post-hoc refinement)를 수행해야하는 번거로움 존재
-
FCN = Encoder + Decoder 구조
- Encoder 부분→ ImageNet으로 학습한 pre-trained CNN model 사용
-
skip architecture 을 이용하여 deep layer 의 semantic information(=coarse) 와 shallow layer 의 appearance information(=fine) 을 잘 혼합하여 segmentation 에 사용가능
Fully convolutional networks
FCN 의 전체적인 구조
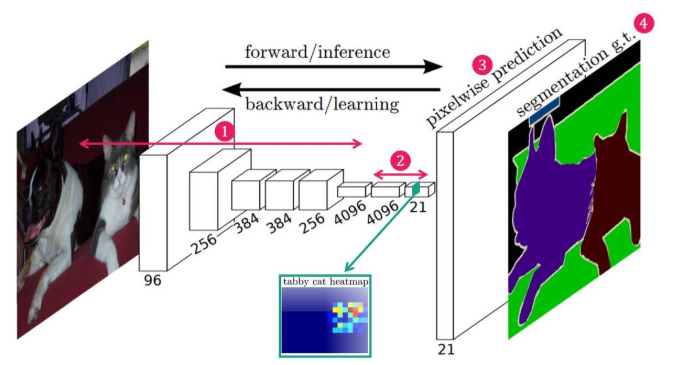
-
CNN 구조
input 이미지 → Convolution 연산을 통해 Feature를 추출 (Feature Extraction)
-
Convolutionalization
1x1 Filter를 이용해 Spatial한 정보를 유지한 상태로 heat map(M x N x class)을 생성
-
Upsampling (Deconvolution) , Skip architecture
Skip architecture : Heat map을 Pooling Layer의 결과들과 combine
Upsampling (Deconvolution) : Combined된 Heap map을 Input 이미지와 동일한 사이즈(W x H)로 복원
- 복원된 Heat map의 각 픽셀별로 softmax를 적용해 픽셀별 class를 예측
Fully convolutional neural network architecture (FCN-8)
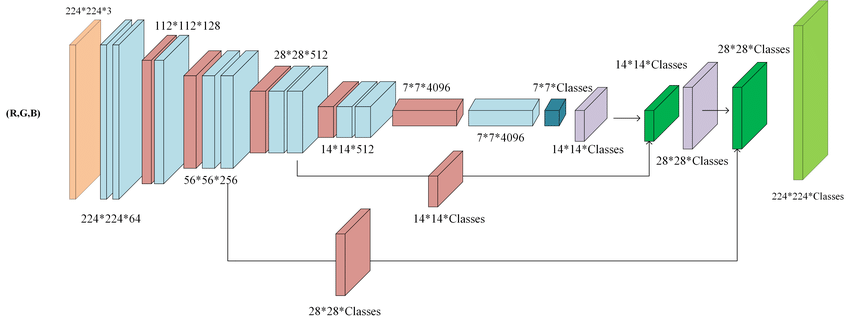
출처 : https://www.researchgate.net/figure/Fully-convolutional-neural-network-architecture-FCN-8_fig1_327521314
Convolutionalization
-
기존 Image classification 모델들은 기본적으로 내부 구조와 관계없이 모델의 근본적인 목표를 위해 출력층이 Fully-connected layer(이하 fc-layer) 로 구성되어있음
-
Semantic Segmentation 관점에서는 fc layer가 갖는 한계점
-
feature map 의 위치 정보(spatial information)이 사라짐
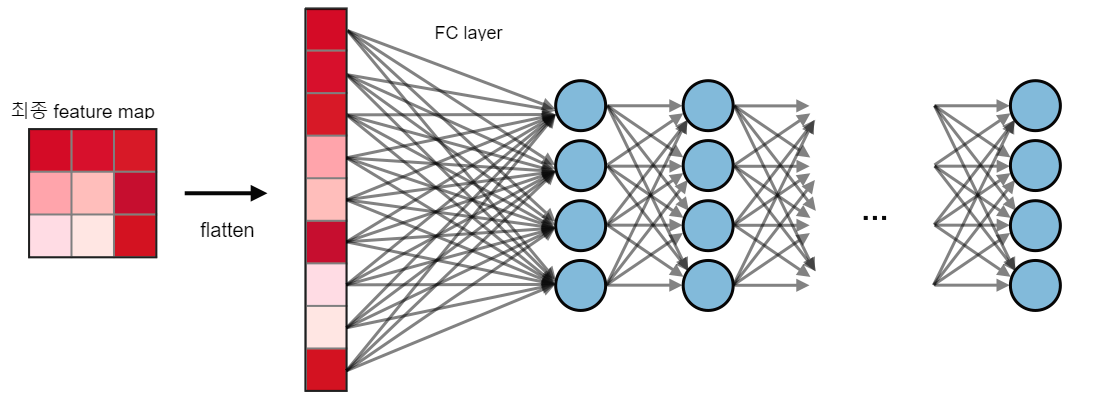
출처: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
-> fc-layer로 넘어가는 과정에서 feature map이 flatten 되면 위치에 대한 정보가 손실된다고 간주하기 때문에 spatial coordinate을 잃어버린다고 표현
-
input 이미지의 size 가 고정됨
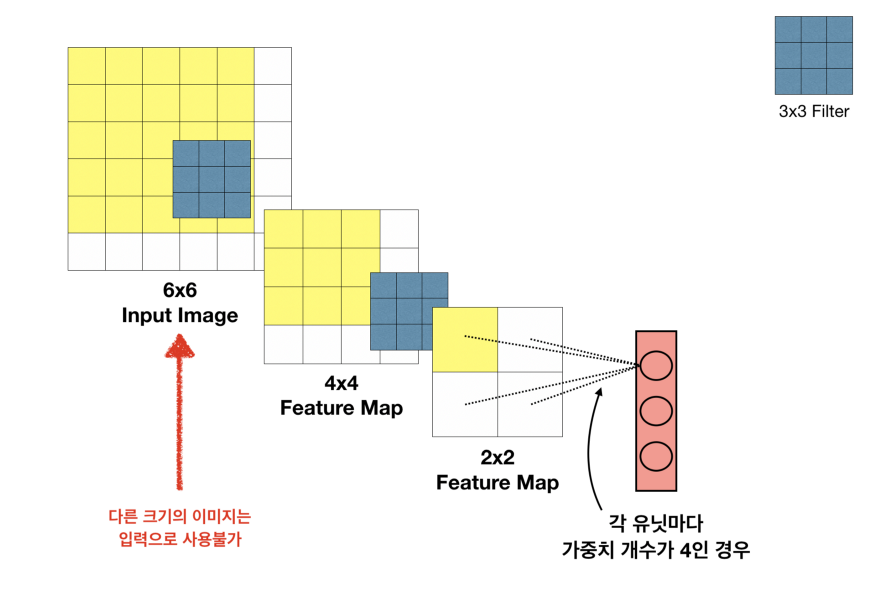
출처 : https://medium.com/@msmapark2
-> fc-layer에 도달하게 되면 직전 feature map이 flatten되어야 하는데, fc-layer는 고정된 입력크기(=neuron)를 받아야함
-
- 이러한 fc-layer의 한계를 보완하기 위해 모든 fc-layer를 Conv-layer로 대체
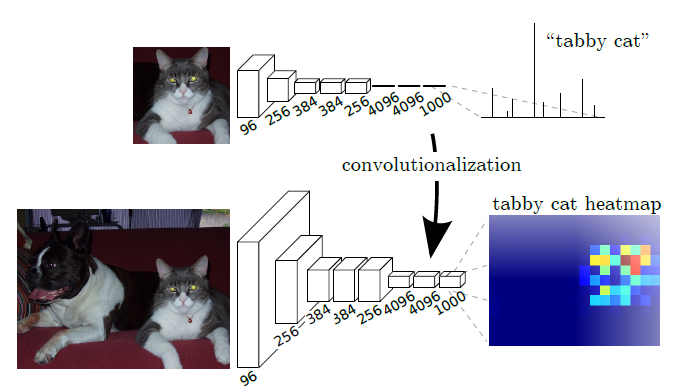
-
Dense Layer (fc-layer)에서 Conv Layer로 변환하는 방식

-
첫 번째 fully-connected layer를 (7x7x512) 4096filter conv로 변경하면 가중치의 수가 유지
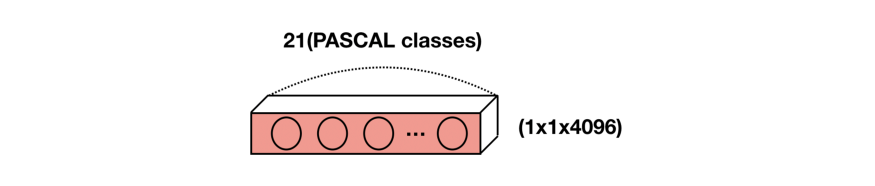
-
마지막 fc-layer의 경우 채널 차원을 클래스 수에 맞춘 1x1 conv로 변환
-
Dense Layer가 적용되는 부분을 1x1 Filter를 이용해 위치정보를 잃어버리지 않으면서 Dense Layer와 같은 역할을 하는 Conv Layer 로 변환
-
Convolutionalization 을 통해 얻은 FCN 의 출력 Feature map 을 Semantic segmentation의 최종 목적인 픽셀 단위 예측과 비교했을 때 , 너무 coarse 함
Coarse 한 feature map을 원본 이미지 크기에 가까운 Dense map으로 변환해야함 → Upsampling (Deconvolution)
Pooling을 사용하지 않거나, Pooling의 stride를 줄임으로써 Feature map의 크기가 작아지는 것을 미리 방지하면 안될까?
→ 필터가 더 세밀한 부분을 볼 수는 있지만 Receptive Field가 줄어들어 이미지의 context 를 놓침
→ Pooling의 중요한 역할 중 하나는 특징맵의 크기를 줄임으로써 학습 파라미터의 수를 감소시키는 것인데, 이러한 과정이 사라지면 파라미터의 수가 급격히 증가하고 이로인해 더 많은 학습시간을 요구하게 됨
→ 따라서, Coarse Feature map을 Dense map으로 Upsampling하는 방법을 사용!
Upsampling (Deconvolution)
→ Coarse map을 Dense map 으로 변환하는 방법
- Bilinear Interpolation
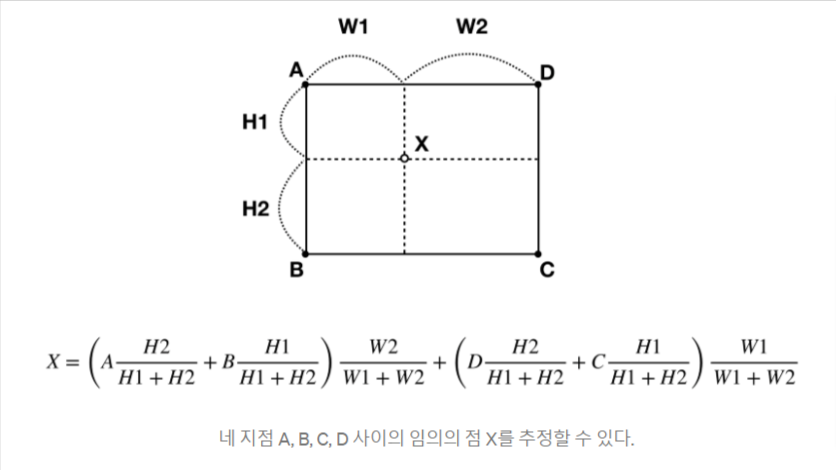
→ 사이의 값을 구하기 위해 쉽고 직관적으로 사용할 수 있는 방법
→ End-to-End 방식에서 학습할 수 없는 방법이기 때문에 마지막에만 사용
-
UnPooling
→ Pooling 시 Pooling 된 위치의 값을 그대로 복원하는 방법
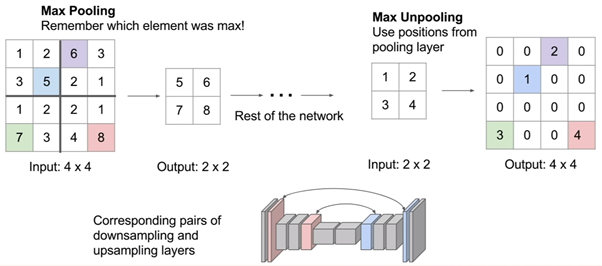
출처 : https://analysisbugs.tistory.com/104
→ 복원시 빈 공간을 채우는 방법 → Nearest Neighbor, Bed of Nails
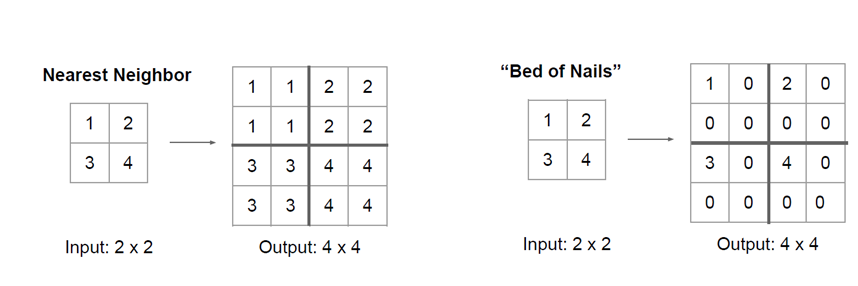
-
Backwards convolution
→ 학습이 가능한 (learnable) Upsampling 방법
→ Convolution 연산을 역으로 이용하는 방법
-
Transposed Convolution 를 이용한 Upsampling(Backwards convolution) 방법
기존의 Convolution 연산의 원리는 다음과 같다.
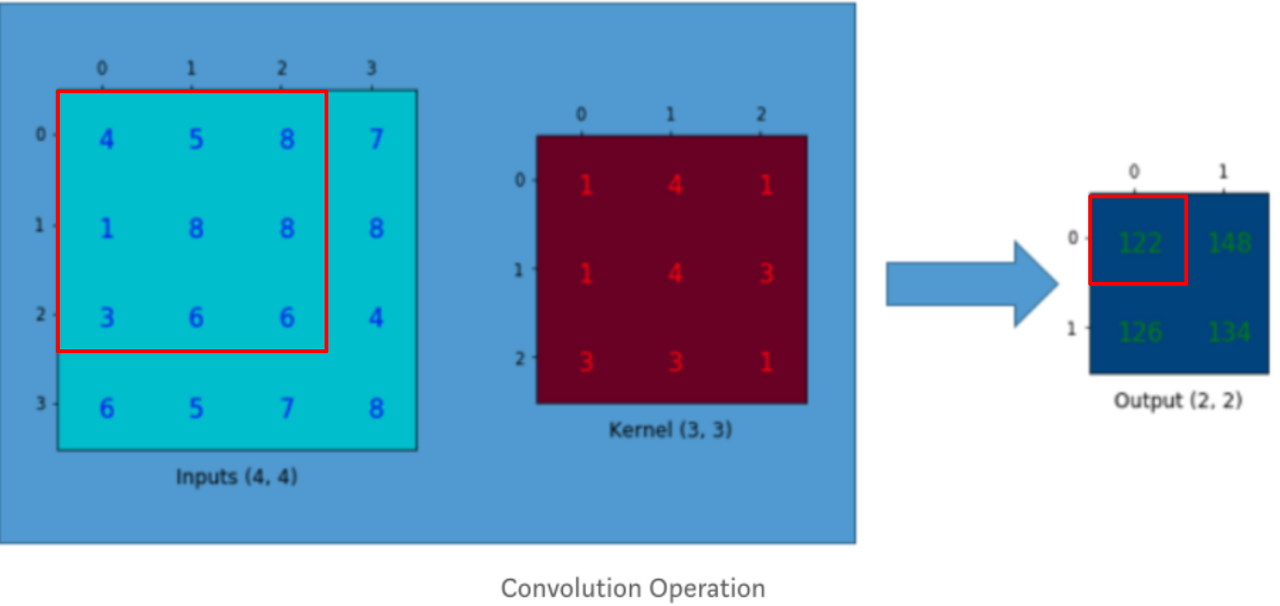
위 연산 과정을 matrix 연산과정으로 변환시키면 아래와 같다.
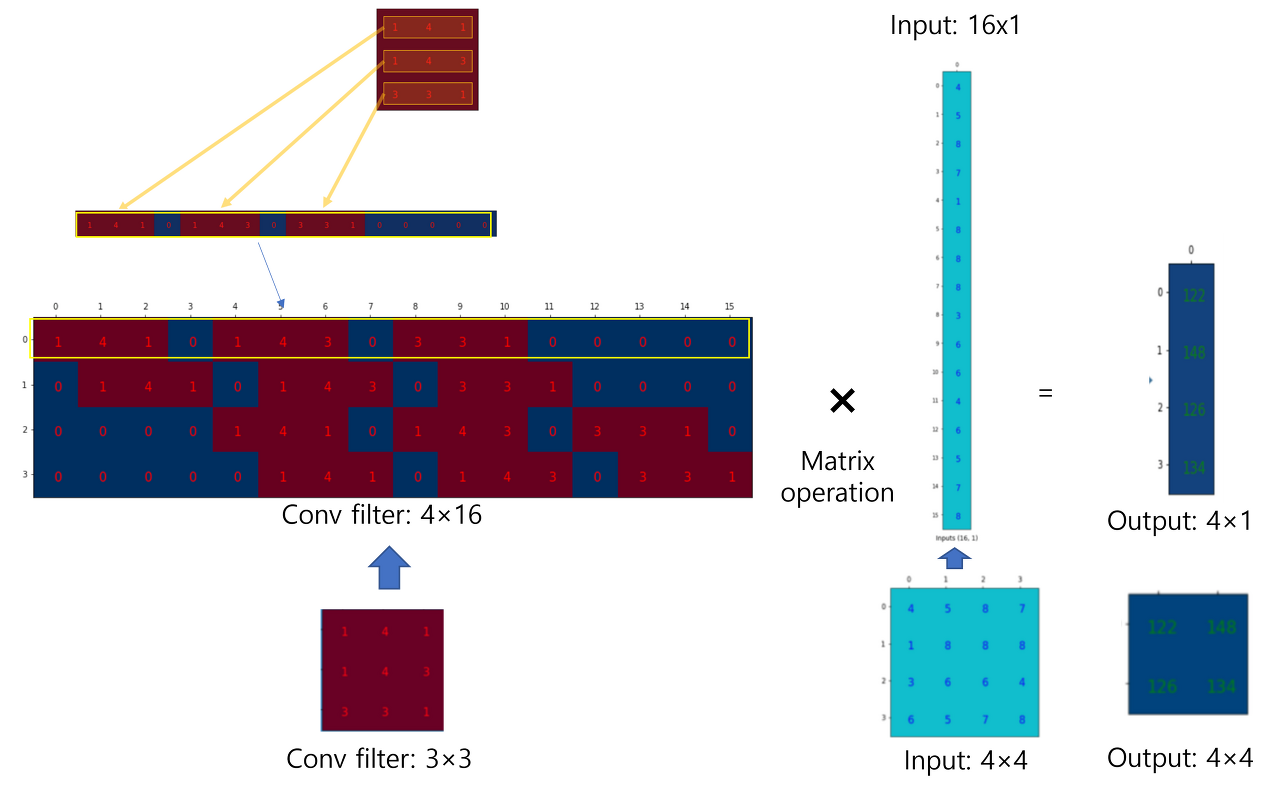
Convolution filter에 해당하는 matrix (=Convolution Matrix) 를 Transpose 한 Convolution Trasnpose Matrix → deconvolution filter를 matrix연산에 맞게 바꿔준 후 upsampling
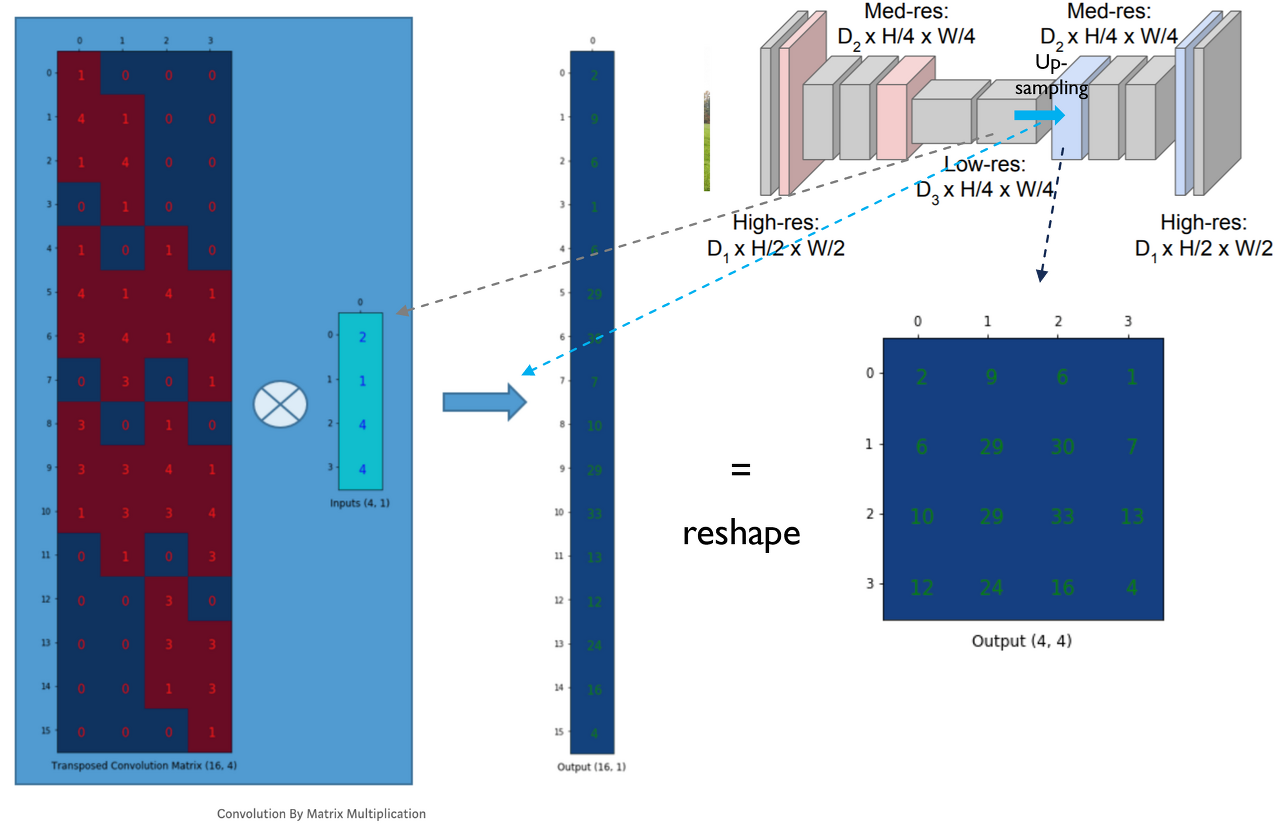
-
Deconvolution 을 이용한 Upsampling(Backwards convolution) 방법
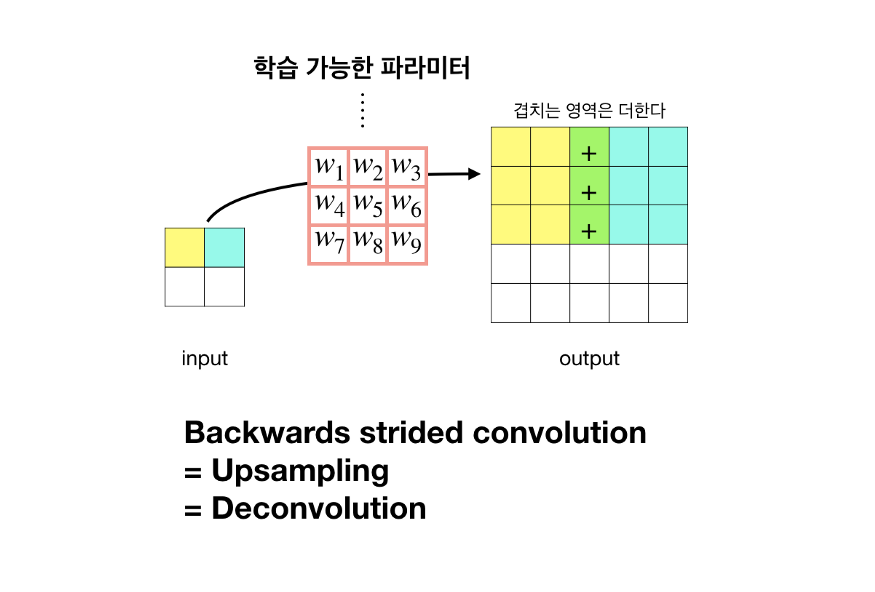
출처 : https://medium.com/@msmapark2
Convolution 연산을 반대로 할 경우 자연스럽게 Up-sampling 효과를 얻을 수 있다. 이때, filiter 에 가중치들을 학습가능한 (learnable) 를 사용한다.
Transposed Convolution 과 Deconvolution 차이점은 무엇일까?
-
Transposed Convolution과 Deconvolution을 혼용해서 사용하기는 하지만, 두 기법은 수학적으로 다른 방식
-
Transposed Convolution
→ 입력의 spatial dimensions 를 재구성
→ 경사하강법을 통해 자체 매개변수를 학습할 수 있으므로 딥 러닝에서는 괜찮지만, 출력을 던지면 완전히 동일한 입력은 제공하지 않음
-
Deconvolution
→ Counvolution의 효과를 역전시키는 수학적 연산 (= convolution 함수의 역함수)
→ 출력을 던지면 deconvolution 을 통해 정확히 동일한 입력을 얻을 수 있음
-
-
Upsampling 을 통해 coarse map에서 dense map을 도출할 수 있었지만 근본적으로 feature map의 크기가 너무 작기 때문에 예측된 dense map의 정보는 여전히 coarse 함 (정보 부족)

→ 정교한 segmentation 을 위해 추가적인 작업 필요 → Skip Architecture
Skip Architecture
정보 부족 문제를 해결하기 위해 Deep & Coarse(추상적인) 레이어의 의미적(Semantic) 정보와 Shallow & fine 층의 외관적(appearance) 정보를 결합 → SKip Arhitecture
FCN-16s
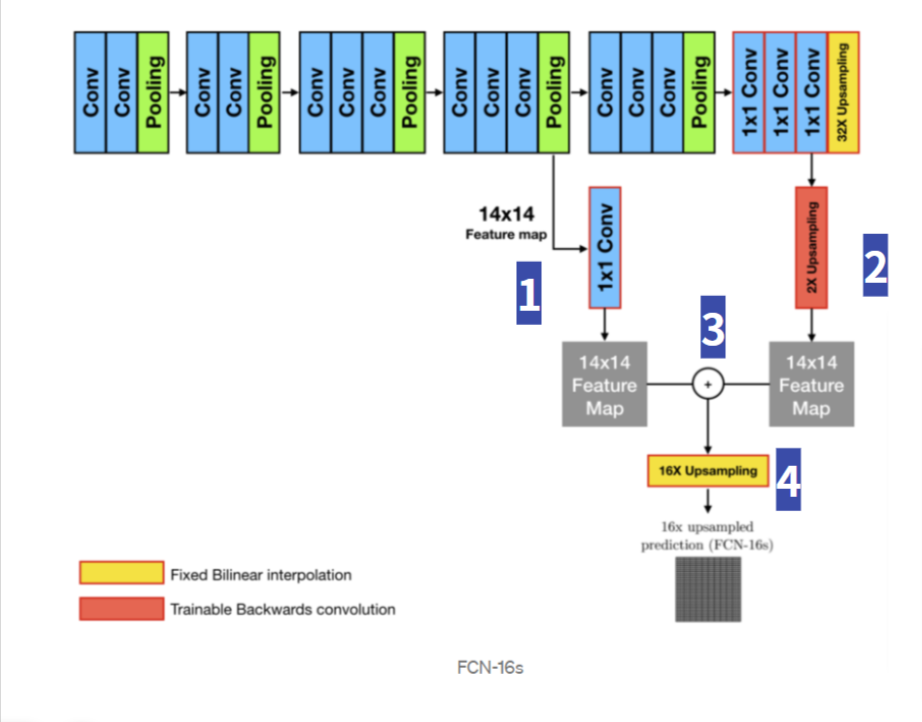
FCN-16s는 와 를 결합한 구조로 다음의 Skip Acrhitecture 과정을 갖는다.
- 에 (1x1) Filter를 적용해 Class수의 channel을 가진 feature map을 추출
- feature map 을 feature map 과 같은 사이즈로 Upsampling (Transposed Convolution)
- feature map 과 feature map 을 element-wise 방식(대응하는 픽셀 값끼리 더함)으로 더함
- (3) 의 결과를 Input 이미지와 같은 size로 Upsampling (Bilinear Interpolation)
FCN-8s
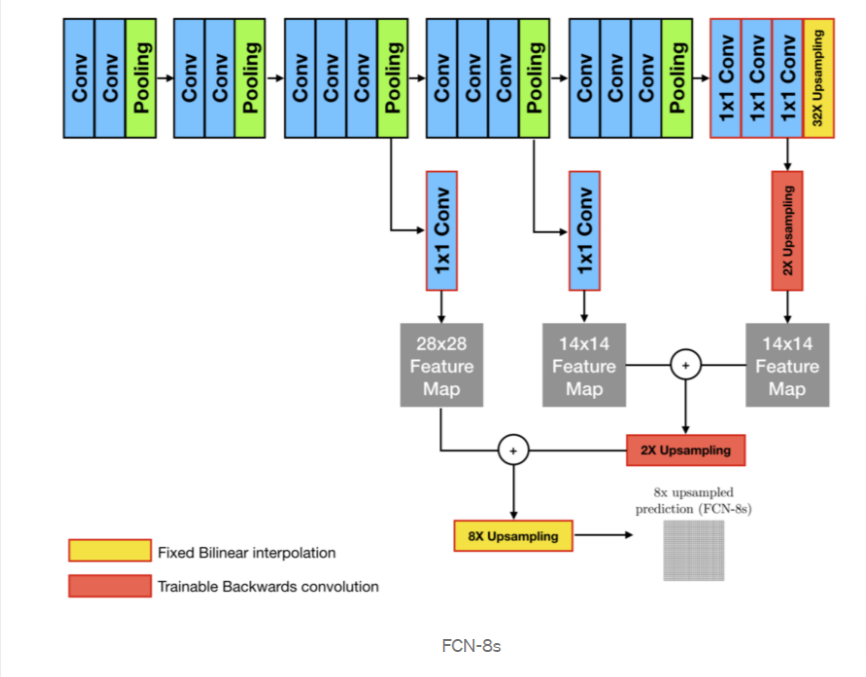
FCN-8s는 ( + ) + 로 결합한 구조이다.
자세한 과정은 FCN-16s 와 같은 과정으로 진행된다.
이러한 Skip Architecture를 통해 다음과 같이 개선된 Segmentation 결과를 얻을 수 있다.

Results
실제 성능 지표에서도 FCN-32s → FCN-16s → FCN-8s 순으로 결과가 나아지는 것을 확인할 수 있다.
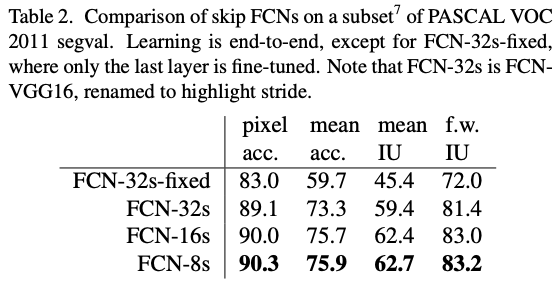

FCN은 기존의 딥러닝 기반 이미지 분류를 위해 학습이 완료된 모델의 구조를 Semantic Segmentation 목적에 맞게 수정하여 Transfer learning 하여 다른 모델보다 확연히 좋은 segmentation 결과를 보여준다.
