[Paper Review] R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation
논문리뷰 Computer Vision

논문 링크 : Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN : Region Proposal + CNN
Abstract
-
Object Detection 성능 평가를 위한 데이터셋 VOC 2012 에서 당시 모델 성능을 30% 향상
- Object Detection 성능 평가 기준 (mean Average Precision (mAP) 53.3% 달성
-
Key Insights
-
Region Proposal + CNN
-
라벨 데이터가 부족한 부분 → pre-training, fine-tuning 을 통해 성능 향상
OverFeat (sliding-window detecter 을 제시) 보다 성능이 좋다고 함 (200-class ILSVRC2013 detection dataset 기준)
-
Introduction
-
기존 Visual Recognition 분야에서는 SIFT, HOG, ensemble를 이용 → 발전 속도 느림
-
이후 back propagation을 통한 SGD로 CNN을 효율적으로 학습 가능
→ ILSVRC image classification 에서 CNN을 이용하여 큰 성능 향상
→ PASCAL VOC 에서 CNN 을 활용한 Object Detecttion 성능 향상 도전
성능 향상을 위해 집중한 문제
1. Deep Network 를 이용해 객체를 Localizing

- Approach 1. Localizing 을 Regression 문제로 간주 → 실용가능성 적음
- Approach 2. Sliding-window detector 방식 사용 → 너무 큰 recptive fields 를 가짐
- Approach 3. Regions 을 이용해 Recognition
- Selective Search 를 통해 2000개 정도의 region 을 뽑아냄
- AlexNet 이용, CNN 특성상 input 값이 고정 → warp 를 시킴
- Classify 단계에서 softmax 대신 linear SVM 이용 (mAP 성능 좋아서)
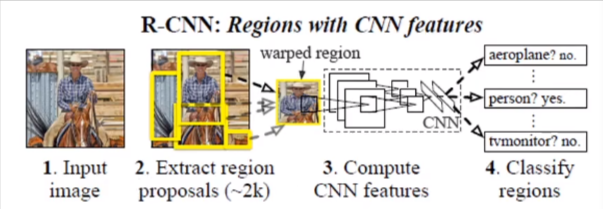
2. 적은 양의 annotated detection data 로 높은 수용성을 가진 모델을 학습
- 보조 데이터로 ILSVRC 데이터를 이용해 pre-training
- Object detection 을 위한 fine-tuning → 8% 성능 향상
Object Detection with R-CNN
-
Region proposals
-
CNN을 이용하여 각 Region 에서 feature vector 을 추출
-
linear SVM 을 이용하여 분류
Region Proposals
: 주어진 이미지에서 물체가 있을법한 위치를 찾는 것
-
Selective Search
주변 픽셀 간의 유사도를 기준으로 Segmentation을 만들고, 이를 기준으로 물체가 있을법한 2000개의 region 후보를 선정

Feature Extraction
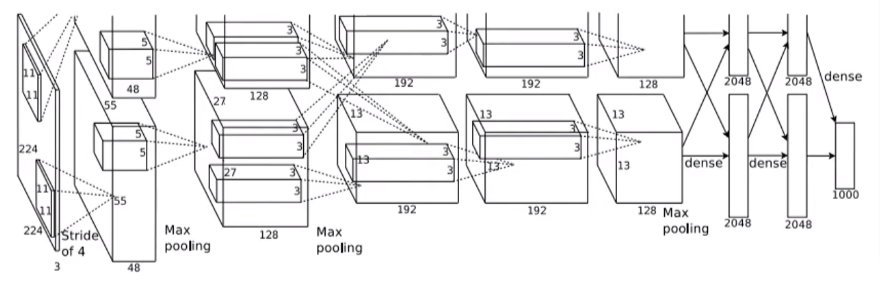
-
Selective Search를 통해서 찾아낸 region 후보들을 227 x 227 크기로 wrap → 이 과정에서 정보 손실, 왜곡 많이 일어남
-
CNN 구조(Alex-Net)를 사용해서 각 region 에서 4096 차원의 feature vector 를 추출
Classification
-
추출한 feature 벡터를 linear SVM 를 이용해 class 별 어떤 물체일 확률 값 score 를 계산
왜 softmax 말고 linear SVM ? → SVM을 이용했을때 mAP 성능이 더 좋게 나와서
-
Non-Maximum Suppression
: 동일한 물체에 여러 개의 region이 겹쳐있을때, 가장 score가 높은 region만 남기고 나머지는 제거하는 과정
→ 이때, Score 가 가장 높은 region 을 기준으로 IoU 가 threshold(여기서는 0.5) 보다 크면 동일 물체로 판단
Training
크게 3가지 부분으로 나눠서 학습
- Pre-training 된 CNN 모델을 가져와 fine tuning
- SVM Classifier 학습
- Bounding Box Regression
-
Supervised pre-training
ILSNRC2021 classification dataset 을 이용해 pre-training
- Fine-tuning
- Object detection task 에 맞게 classification class 개수(N)에 background 를 추가하여 (N+1) 개 사용
- positive sample (IoU 0.5 이상) : negative sample (background) 을 1:3의 비율로 SGD 학습
-
Object category classifiers
-
class 별로 Linear SVM 을 구성해서 학습 → training data 가 너무 크기 때문
-
class 별로 training 을 하기 위해서 IoU threshold 값을 0.3으로 지정
→ Ground truth box를 positive sample , 0.3 미만이면 negative sample -
앞에서 얻은 fine-tuned CNN 으로 얻은 피처 벡터로 학습
-
-
Bounding Box Regression
- Selective Search를 통해서 찾은 box 위치는 상당히 부정확함 → 성능을 끌어올리기 위해서 이 box 위치를 교정해주는 부분을 Bounding Box Regression

- feature vector 로 얻은 box 와 실제 ground truth box 와의 차이를 최소화 하는 box 를 만들어내도록 w를 학습 → Linear Regression
- Selective Search를 통해서 찾은 box 위치는 상당히 부정확함 → 성능을 끌어올리기 위해서 이 box 위치를 교정해주는 부분을 Bounding Box Regression
Results
Results on PASCAL VOC
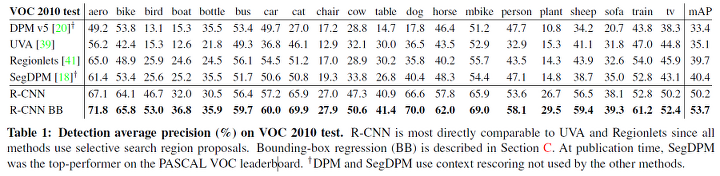
- R-CNN이 다른 모델보다 좋은 성능을 보임
- Bounding Box regression 을 활용하여 더 좋은 성능을 보임
Results on ILSVRC2013 detection
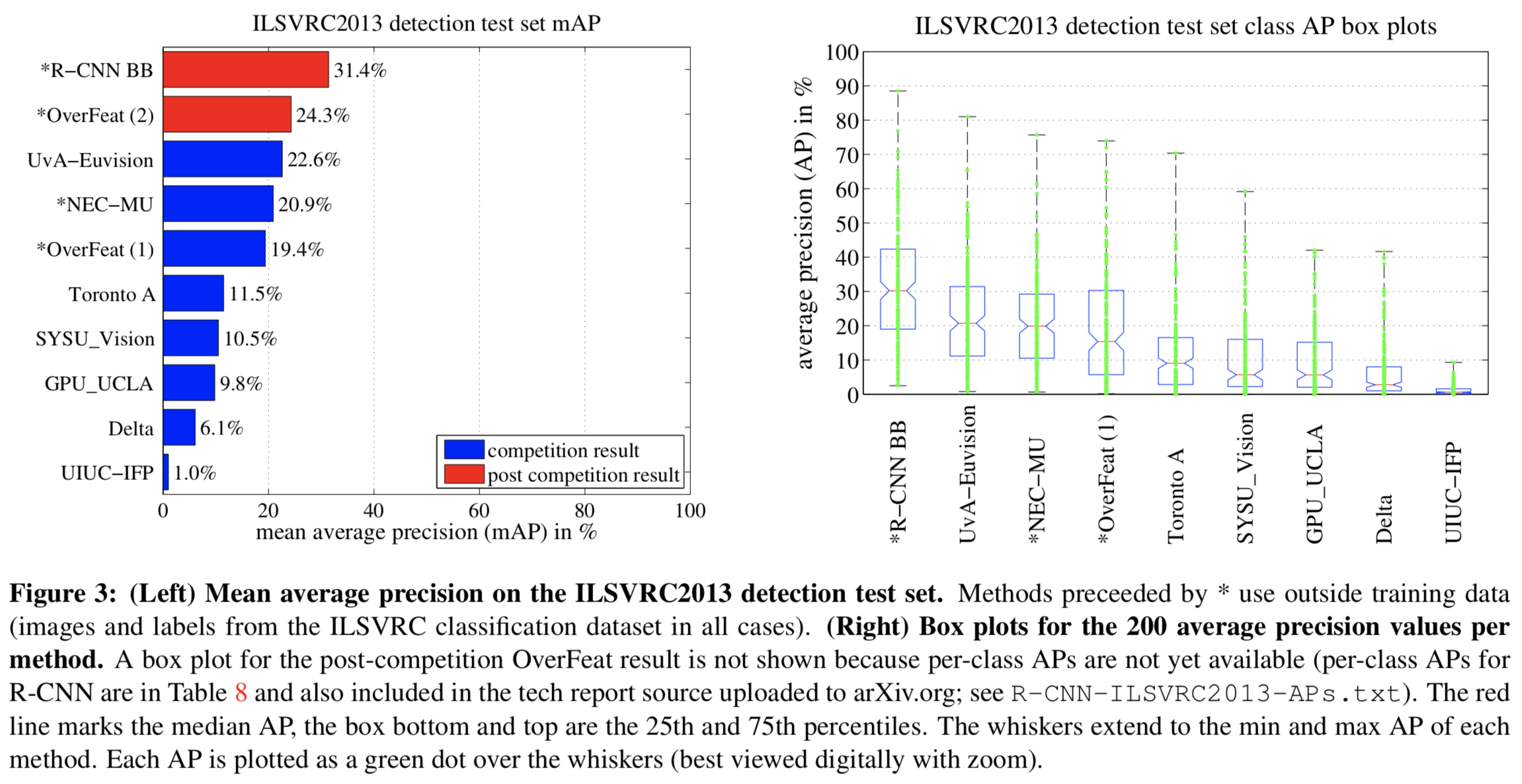
- R-CNN이 다른 모델보다 좋은 성능을 보임
- class 별로 얻어낸 precision value 값 또한 다른 모델에 비해 높은 수치
