ViT: https://arxiv.org/abs/2010.11929
😮 한 이미지는 16x16 단어만큼의 "가치"가 있다
👉 Transformer 모델이 NLP 에서 각 단어 간의 관계를 학습하는 것처럼, ViT에서는 이미지 패치들 간의 관계를 학습하는 방식. 즉, 16x16 단어만큼의 가치란, 이미지의 각 패치가 마치 언어의 "단어"처럼 중요한 정보를 담고 있다는 의미.
0. Abstract
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
📖 저자는 Vision에서 CNNs가 꼭 필요하지 않고 순수한 트랜스포머(pure transformer)만을 이미지 패치의 시퀀스에 직접적으로(directly) 적용하여 image classification에 잘 작동함을 보여주었다고 주장!
1. Introduction
In computer vision, however, convolutional architectures remain dominant (LeCun et al., 1989; Krizhevsky et al., 2012; He et al., 2016). Inspired by NLP successes, multiple works try combining CNN-like architectures with self-attention (Wang et al., 2018; Carion et al., 2020), some replacing the convolutions entirely (Ramachandran et al., 2019; Wang et al., 2020a). The latter models, while theoretically efficient, have not yet been scaled effectively on modern hardware accelerators due to the use of specialized attention patterns. Therefore, in large-scale image recognition, classic ResNet like architectures are still state of the art
📖 attention의 특수한 패턴사용 때문에 사용되지 못하고 있어서 여전히 ResNet 같은 architecture가 최신 기법으로 사용되고 있음.
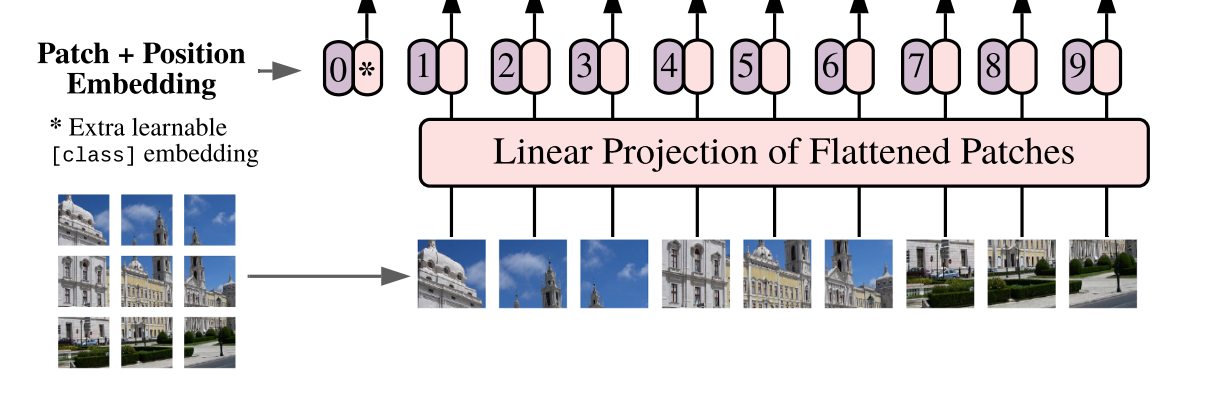
Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP applica88tion. We train the model on image classification in supervised fashion
📖 위에 보이는 것처럼 image 를 patches 로 나누고 -> sequence linear embedding를 transformer encoder에 전달
When trained on mid-sized datasets such as ImageNet without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size. This seemingly discouraging outcome may be expected: Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data
📖 같은 규모의 데이터셋에 대해서 Transformer 가 CNN 보다 성능이 낮을 수 있는데 그 이유로는
① 변환 등가성(translation equivariance)
② 지역성 (locality) 이라는 2가지 귀납적 편향(inductive bias)를 가지고 있기 때문이다.
🤔 변환 등가성이랑 지역성이 무슨 말인가??
👉 ① 변환등가성이란, 이미지가 이동하더라도 이를 잘 인식할 수 있는 특성이고
② 지역성이란, 이미지 내 인접 픽셀들이 더 연관되어 있다는 특성.
-> 즉, CNN은 이러한 2가지 특성 덕분에 일반화(general)하게 되지만 Transformer는 아니다.
However, the picture changes if the models are trained on larger datasets (14M-300M images). We find that large scale training trumps inductive bias
📖 하지만 충분한 데이터셋이 많다면 transformer 가 cnn보다 더 좋은 성능을 나타냄을 보였다.
2. Related work
한줄 요약
- Transformer : https://arxiv.org/abs/1706.03762
:We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely
- BERT : https://arxiv.org/abs/1810.04805
:BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers
- GPT : https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
:We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task
3. Method
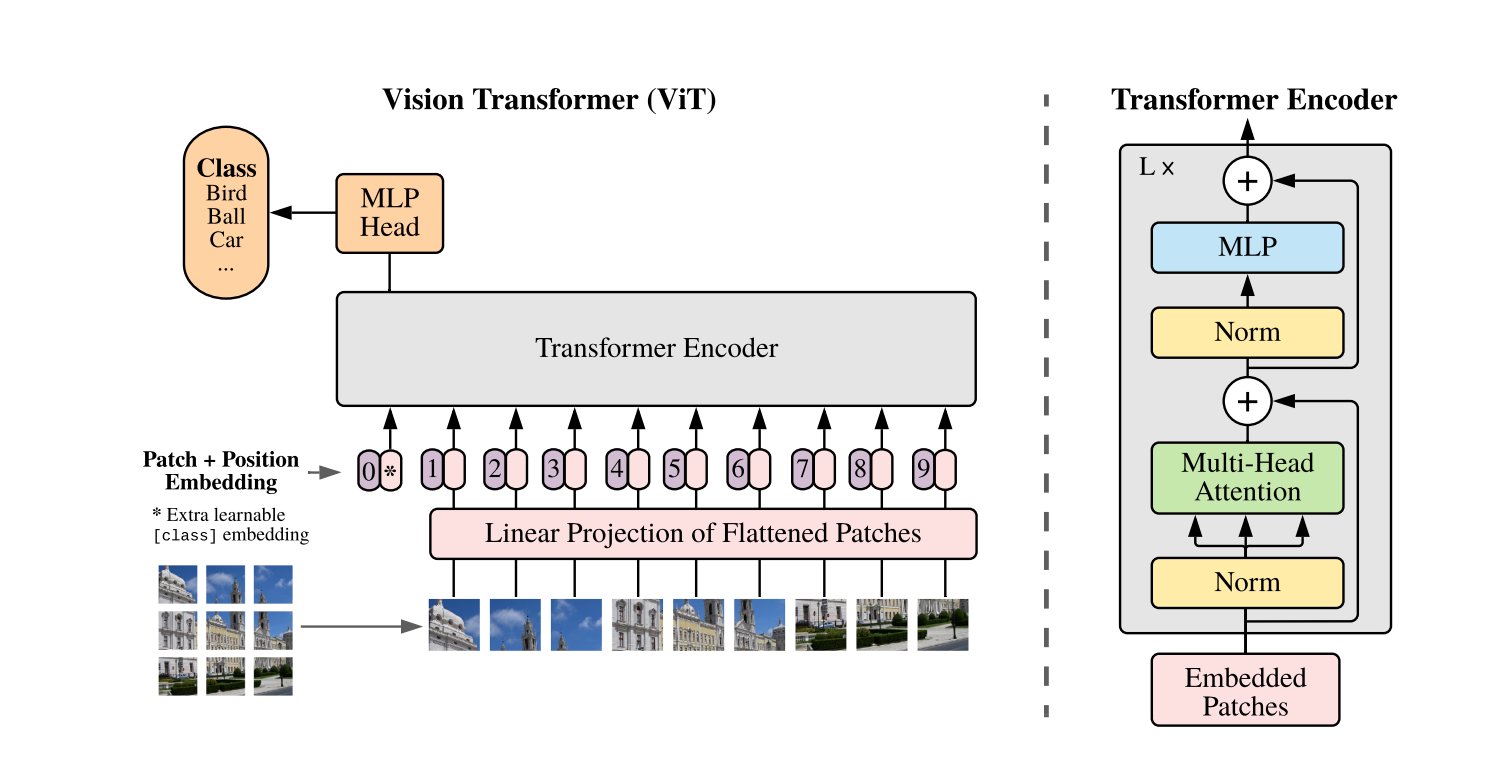
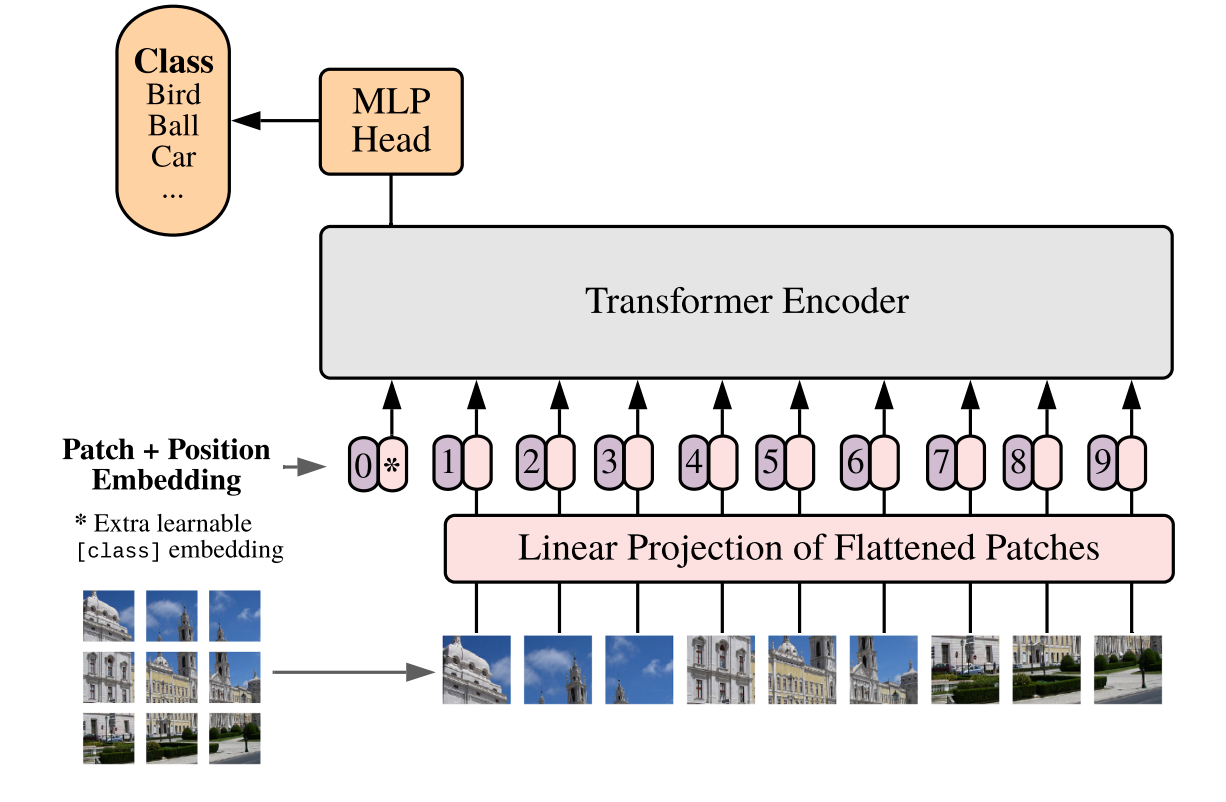
Model overview. We split an image into fixed-size patches, linearly embed each of them, add position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder. In order to perform classification, we use the standard approach of adding an extra learnable “classification token” to the sequence
In model design we follow the original Transformer (Vaswani et al., 2017) as closely as possible.An advantage of this intentionally simple setup is that scalable NLP Transformer architectures – and their efficient implementations – can be used almost out of the box.
📖 전반적인 과정을 요약하면 간단하다.
① image를 고정된 사이즈(fixed-size)인 patches 로 나눈다.
② 선형적으로 각각 embedded 하고 추가로 positional embbedings도 같이 붙인다.
(+추가로 맨 처음에는 classification token를 붙여준다)
③ 그후에 Transformer Encoder에 넣어준다. 이러면 분류 완료.
🤔 근데 맨 처음에 왜 classification token을 붙여주는 것일까?
👉 Transformer 기반 모델에서 이미지 분류 작업을 효과적으로 수행하기 위해서 붙임.
각 패치들(patches)은 이미지를 나눈 조각들로 전체적인 정보를 직접적으로 나타내긴 어려움 그래서 분류를 위해 "classification token"을 추가해서 학습과정에서 전체 이미지의 요약정보다 중요한 특징을 점진적으로 학습하고 모델의 마지막 출력에서 이 "classification token"의 벡터 표현을 사용해 분류작업을 수행.
3.1) Vision Transforemr(ViT)
📖 위 식을 제대로 하나하나씩 살펴보면 viT가 어떠한 과정을 거치는지 완벽하게 알 수 있다. 따라서 제대로 설명을 적어보자.
👉 ①
: 첫번째 층의 입력으로 이미지 패치()와 클래스 토큰()을 임베딩한 후, 위치 임베딩()을 더한 벡터
②
- (Multi-Head Self-Attention) : 입력에 대해 여러개의 독립적인 self-attention을 적용하여 정보 추출.
- (Layer Normalization) : 입력층 정규화
- : 전 층에서의 출력
- : Self-Attention 후의 중간 결과
③
- (Multi_Layer_Perceptron) :Fully connected layer (완전 연결층)를 여러 층 쌓은 신경망 구조
- :Self-Attention을 통과한 중간 결과
④
- : Transformer 의 마지막 출력층
- : 정규화 층 거치고 나서 마친 최종결과.
The standard Transformer receives as input a sequence of token embeddings. To handle 2D images, we reshape the image into a sequence of flattened 2D patches , where is the resolution of the original image, is the number of channels, is the resolution of each image patch, and is the resulting number of patches, which also serves as the effective input sequence length for the Transformer. The Transformer uses constant latent vector size through all of its layers, so we flatten the patches and map to dimensions with a trainable linear projection (Eq. 1). We refer to the output of this projection as the patch embeddings
Similar to BERT’s [class] token, we prepend a learnable embedding to the sequence of embedded patches ( = ), whose state at the output of the Transformer encoder () serves as the image representation (Eq. 4). Both during pre-training and fine-tuning, a classification head is attached to . The classification head is implemented by a MLP with one hidden layer at pre-training time and by a single linear layer at fine-tuning time
Position embeddings are added to the patch embeddings to retain positional information. We use standard learnable 1D position embeddings, since we have not observed significant performance gains from using more advanced 2D-aware position embeddings (Appendix D.4). The resulting sequence of embedding vectors serves as input to the encoder.
📖 빨간색만 보면 되요~!
① 3D 이미지를 2D 로 flatten하게 함. 원본이미지를 에서 크기의 1D 시퀀스 패치로 변환합니다. 여기서 는 패치의 수이며, 각 패치는 크기
② Transformer 는 모든 레이어에서 일정한 크기의 vector size 를 사용. 따라서 패치를 flatten 한후 차원으로 변환하는 선형변환을 통해 패치 임베딩을 함
③ 에 학습가능한 임베딩을 붙여줌
④ 포지셔널 임베딩도 당연히 붙여줘서 이미지의 각 위치값을 잃어버리지 않게 함.
viT에서 positional embedding 시각화.

Inductive bias. We note that Vision Transformer has much less image-specific inductive bias than CNNs. In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model. In ViT, only MLP layers are local and translationally equivariant, while the self-attention layers are global. The two-dimensional neighborhood structure is used very sparingly: in the beginning of the model by cutting the image into patches and at fine-tuning time for adjusting the position embeddings for images of different resolution (as described below). Other than that, the position embeddings at initialization time carry no information about the 2D positions of the patches and all spatial relations between the patches have to be learned from scratch.
📖 ViT는 CNNs 보다 훨씬 적은 귀납적 편향(inductive bias)를 가진다는 것을 알았다.
ViT에서 MLP layers 만이 지역성과 변형 등가성을 가지고 self-attention 레이어는 전역적이기 때문이다.
3.2) Fine-Tuning and Higher resolution
Typically, we pre-train ViT on large datasets, and fine-tune to (smaller) downstream tasks. For this, we remove the pre-trained prediction head and attach a zero-initialized feedforward layer, where K is the number of downstream classes. It is often beneficial to fine-tune at higher resolution than pre-training (Touvron et al., 2019; Kolesnikov et al., 2020). When feeding images of higher resolution, we keep the patch size the same, which results in a larger effective sequence length. The Vision Transformer can handle arbitrary sequence lengths (up to memory constraints), however, the pre-trained position embeddings may no longer be meaningful. We therefore perform interpolation of the pre-trained position embeddings, according to their location in the original image. Note that this resolution adjustment and patch extraction are the only points at which an inductive bias about the 2D structure of the images is manually injected into the Vision Transformer
4. Experiment
-생략) 논문참조.
5. Conclusion.
We have explored the direct application of Transformers to image recognition. Unlike prior works using self-attention in computer vision, we do not introduce image-specific inductive biases into the architecture apart from the initial patch extraction step. Instead, we interpret an image as a sequence of patches and process it by a standard Transformer encoder as used in NLP. This simple, yet scalable, strategy works surprisingly well when coupled with pre-training on large datasets. Thus, Vision Transformer matches or exceeds the state of the art on many image classification datasets, whilst being relatively cheap to pre-train(..이후생략..)
📖 초기에 patch extraction step을 제외하고는 image-specific inductive bias 를 주입하지 않았고 대신에 이미지 패치의 시퀀스를 스스로 해석하고 NLP 에서 transformer encoder 로 처리했다.
6. Code
