
1. 배운점
(0) cuda
0-0) cuda 를 사용할 수 있는 환경인지 검토
torch.cuda.is_available()0-1) cuda device이름을 확인하는 코드
torch.cuda.get_device_name(device=0)0-2) Tensor를 GPU 에 할당하는 코드표현
torch.tensor([1,2,3]).to("cuda")(1) torch
1-0) torch.cat()함수는 기존의 차원을 유지하면서 Tensor들을 연결함
입력
torch.cat()1-1) torch.stack() 함수는 차원을 하나 추가하면서 Tensor들을 연결함.
torch.stack()1-2) torch.repeat() Tensor 요소들을 반복해서 크기를 확장하는데 사용
torch.repeat()(2) 선형회귀분석
2-0) 정의
주어진 train data 를 이용하여 feature와 target 사이의 선형관계를 분석하고 이를 바탕으로 모델을 학습시켜 트레이닝에 포함되지 않은 새로운 데이터의 결과를 연속적인 숫자값으로 예측하는 과정
2-1) 상관관계분석
- 각 피쳐가 얼마나 관계가 있는지 파악하는 분석
2-2) 코드
import torch
import pandas as pd0) # 데이터 불러오기
data = pd.read_csv("Salary_dataset.csv", sep = ",", header =
1) 특징 변수와 목적 변수로 분리
x = data.iloc[:, 1].values # 두 번째 열을 특징 변수로 사용 (YearsExperience)
t = data.iloc[:, 2].values # 세 번째 열을 목적 변수로 사용 (Salary)
2) 상관 관계 분석 코드 표현 실습
import numpy as np
correlation_matrix = np.corrcoef(x, t)
correlation_coefficient = correlation_matrix[0, 1]
print(correlation_matrix)
print('Correlation Coefficient between YearsExperience and Salary :', correlation_coefficient)
3) 1차원 numpy 배열을 2차원 Tensor로 변환
x_tensor = torch.tensor(x, dtype=torch.float32).view(-1, 1) # 2차원 형태로 변환
t_tensor = torch.tensor(t, dtype=torch.float32).view(-1, 1) # 2차원 형태로 변환
4) 선형 회귀 모델 코드 표현 실습
import torch.nn as nn
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 입력과 출력이 모두 1개인 선형 회귀 모델
def forward(self, x_tensor):
y = self.linear(x_tensor) # 입력 데이터를 선형 계층을 통해 예측값 계산
return y
5) 모델 인스턴스 생성
model = LinearRegressionModel()
6) SGD로 경사하강및 손실함수, 옵티마이저 설정
import torch.optim as optim
loss_function = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr = 0.01) # 학습률을 적절히 설정
7) epoch 설정
num_epochs = 1000
loss_list = []
for epoch in range(num_epochs):
y = model(x_tensor) # 예측 변수 계산
loss = loss_function(y, t_tensor) # 손실 값 계산
# 확률적 경사하강법 작동원리의 코드 표현 실습
optimizer.zero_grad() # 이전 단계에서 계산된 경사(기울기)를 0으로 초기화
loss.backward() # 현재 손실(loss)에 대한 경사(기울기)를 계산 (역전파 수행)
optimizer.step() # 계산된 경사(기울기)를 사용하여 가중치를 업데이트
# 손실 값을 저장
loss_list.append(loss.item())
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 디버깅 정보 출력
for name, param in model.named_parameters():
print(f'{name}: {param.data}')
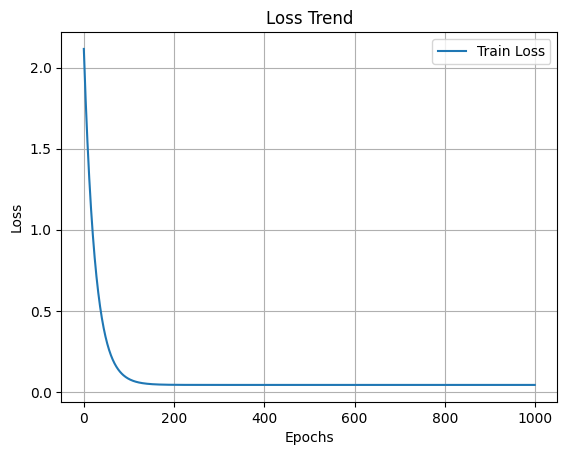
8) 손실함수 시각화
import matplotlib.pyplot as plt
plt.figure()
plt.plot(loss_list, label='Train Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.title('Loss Trend')
plt.show()
(3) 로지스틱회귀분석
3-0) 정의
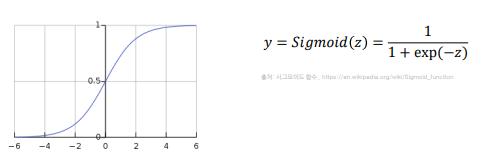
**로지스틱회귀란**, 데이터의 특성과 분포를 바탕으로 최적의 결정 경계를 찾아 시그모이드함수를 통해 이 경계를 기준으로 데이터를 이진분류하는 알고리즘
3-1) 코드
import torch
# 트레이닝 데이터의 코드 표현 실습
import pandas as pd
df = pd.read_csv("Iris.csv", sep = ",", header = 0)[["PetalLengthCm", "Species"]] # 데이터 불러오기
filtered_data = df[df['Species'].isin(['Iris-setosa', 'Iris-versicolor'])]
filtered_df = filtered_data
# 1. 목표 변수를 이산형 레이블로 매핑하는 코드 표현 실습
filtered_df.loc[:, 'Species'] = filtered_df['Species'].map({'Iris-setosa': 0, 'Iris-versicolor': 1})
# 2. 특징 변수(features)와 목표 변수(target)을 추출하는 코드 표현 실습
x = filtered_df[['PetalLengthCm']].values
t = filtered_df['Species'].values.astype(int)
# 3. 데이터 분할의 코드 표현 실습
from sklearn.model_selection import train_test_split
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size=0.2, random_state=42)
# 4. 데이터 표준화의 코드 표현 실습
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 5. 데이터를 Tensor로 변환하는 코드 표현
x_train = torch.tensor(x_train, dtype=torch.float32)
x_test = torch.tensor(x_test, dtype=torch.float32)
t_train = torch.tensor(t_train, dtype=torch.float32).unsqueeze(1)
t_test = torch.tensor(t_test, dtype=torch.float32).unsqueeze(1)
# 6. Dataset 클래스의 코드 표현 실습
from torch.utils.data import Dataset, DataLoader
class IrisDataset(Dataset): # CustomDataset 클래스
def __init__(self, features, labels):
self.features = features
self.labels = labels
def __len__(self):
return len(self.features)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]
# 7. DataLoader 생성 코드 표현 실습
train_dataset = IrisDataset(x_train, t_train)
test_dataset = IrisDataset(x_test, t_test)
batch_size = 4 # 배치 크기를 4로 설정
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 8. 이진 분류 모델 코드 표현 실습
import torch.nn as nn
class BinaryClassificationModel(nn.Module):
def __init__(self):
super(BinaryClassificationModel, self).__init__()
self.layer_1 = nn.Linear(1, 1) # 입력 차원과 출력 차원을 1로 설정
self.sigmoid = nn.Sigmoid()
def forward(self, x):
z = self.layer_1(x)
y = self.sigmoid(z)
return y
\
# 9. 모델 초기화
model = BinaryClassificationModel()
# 10. 이진 교차 엔트로피 코드 표현 실습
import torch.optim as optim
loss_function = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 11. 이진 분류 모델 학습 코드 표현 실습
num_epochs = 500
loss_list = []
for epoch in range(num_epochs):
model.train()
epoch_loss = 0
for batch_features, batch_labels in train_loader:
optimizer.zero_grad()
outputs = model(batch_features)
loss = loss_function(outputs, batch_labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
loss_list.append(epoch_loss / len(train_loader))
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 테스트 데이터의 코드 표현 실습
# 12. 모델을 사용하여 예측
model.eval()
with torch.no_grad():
predictions = model(x_test)
predicted_labels = (predictions > 0.5).float()
# 예측 결과와 실제 라벨을 출력하는 코드 표현 실습
actual_labels = t_test.numpy()
predicted_labels = predicted_labels.numpy()
print("Predictions:", predicted_labels.flatten())
print("Actual Labels:", actual_labels.flatten())
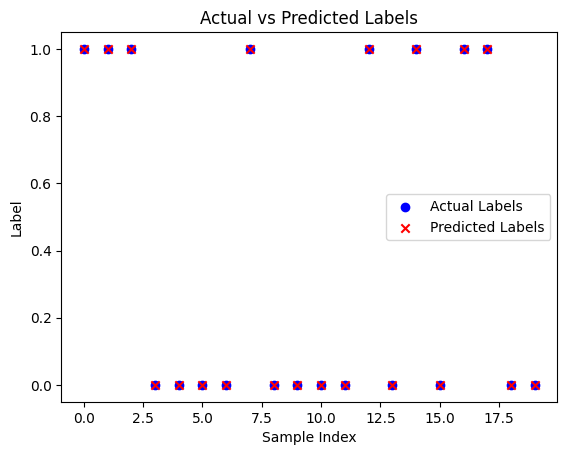
# 13. 예측 결과를 시각화하는 코드 표현 실습
plt.figure()
plt.scatter(range(len(actual_labels)), actual_labels, color='blue', label='Actual Labels')
plt.scatter(range(len(predicted_labels)), predicted_labels, color='red', marker='x', label='Predicted Labels')
plt.xlabel('Sample Index')
plt.ylabel('Label')
plt.legend()
plt.title('Actual vs Predicted Labels')
plt.show()

Lee_AA