AI_Tech부스트캠프 week14...[5] Image Generation 1 : Image Generation Models Overview
AI_tech_CV트랙 여정
1. Generative Adversarial Networks, GANs
1.1 GANs
판별자와 생성자를 적대적으로 학습하는 모델 구조

:
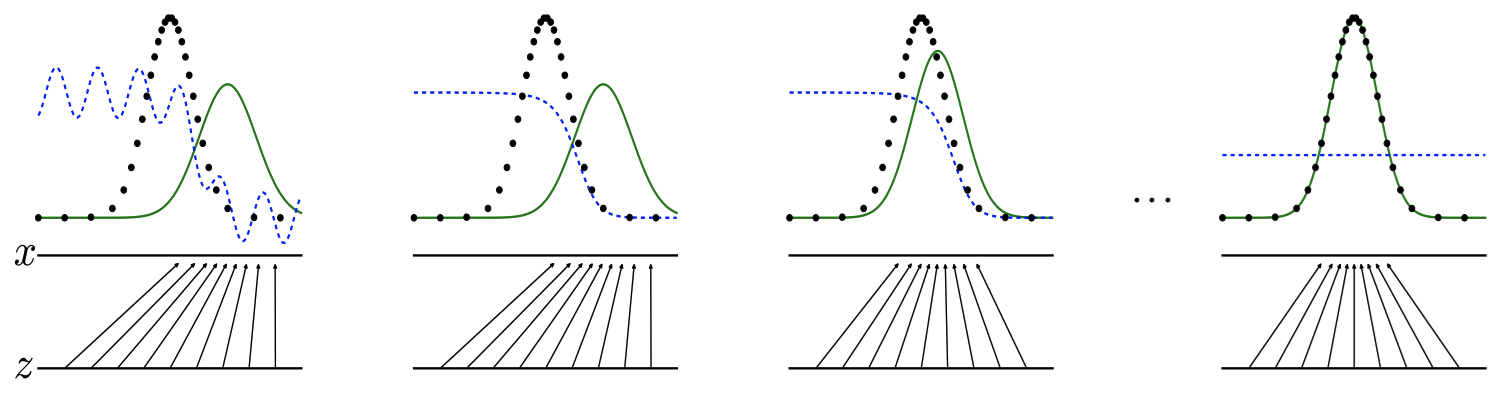
- 검은점 : 실제데이터 분포
- 초록곡선: 생성된 데이터 분포
- 파란점선: Discriminator의 출력 -> 각 데이터 포인트가 실제 데이터인지 또는 생성된 데이터인지 판단하여 확률로 나타냄
-> 위 이미지로 보면 학습 초기에는 Discriminator가 두 분포를 명확히 구별할 수 있지만, 학습이 진행되면서 생성된 데이터 분포가 실제 데이터 분포에 가까워지면 구별이 어려워짐
1.2 cGAN, Pix2Pix
Conditional Gnerative Adversarial Networks
GAN 학습에 조건condition을 주입하여 학습하는 구조
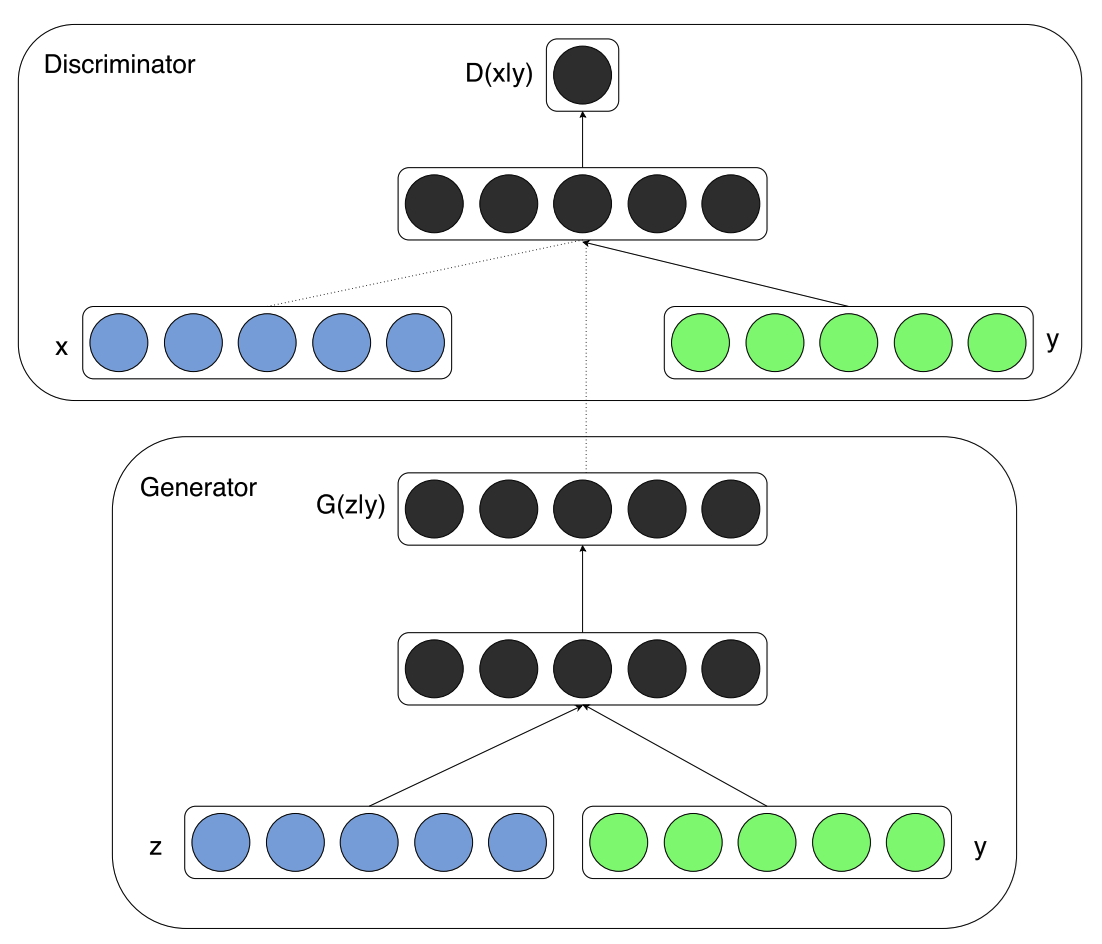
- 위쪽 박스 (Discriminator):
실제 데이터(x)와 조건(y)를 입력으로 받아 데이터의 진위 여부를 판단합니다. - 아래쪽 박스 (Generator):
노이즈(z)와 조건(y)를 입력으로 받아 조건에 맞는 데이터를 생성합니다
Pix2Pix
이미지를 조건으로 이미지를 변환하는 방법
학습을 위해 서로 매칭되는 paired image가 필요함
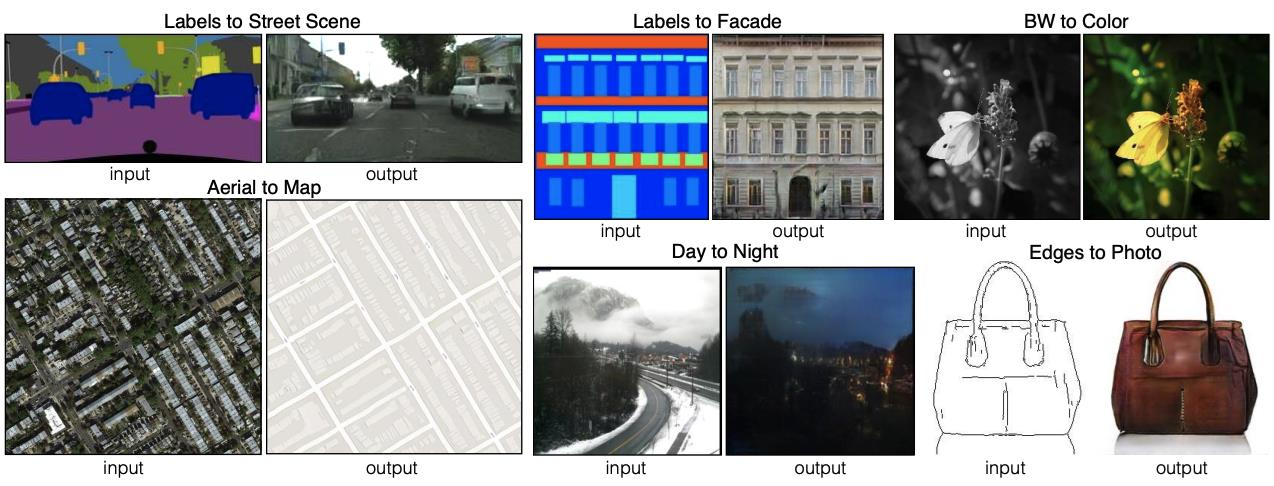
Conditional GAN를 따름
아래 이미지는, edge 이미지를 조건으로 생성자G를 통해 사진을 생성하고, 판별자D는 생성된 사진 또는 진짜 사진을 판별하도록 학습함.

Pix2Pix는 Paired image가 많이 필요하다는 단점이 있음 -> 이를 극복한게 CycleGAN
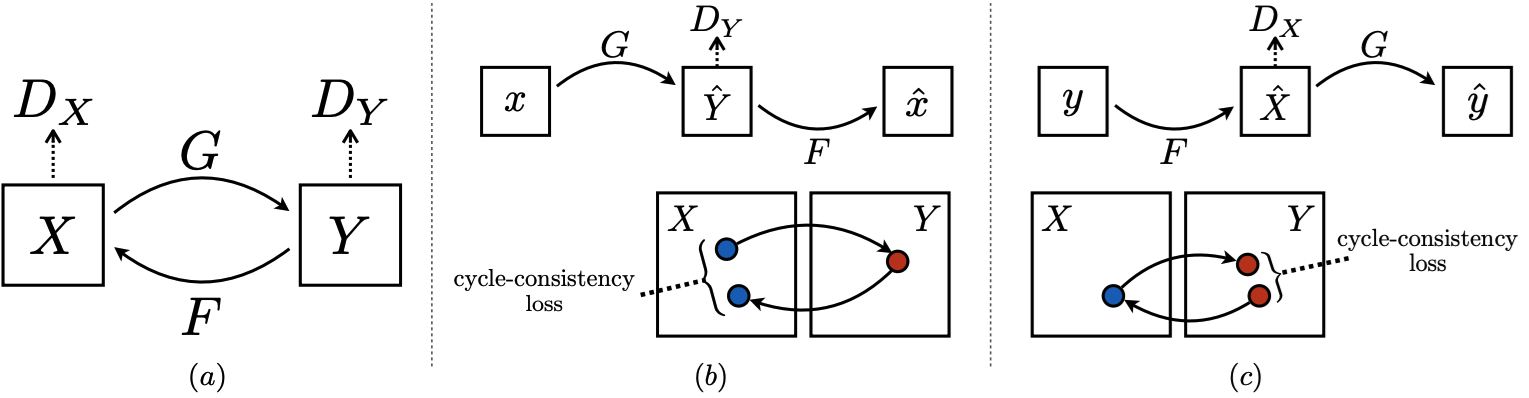
1.3 CycleGAN, StarGAN
CycleGAN
CycleGAN에서는 unpaired images로 학습하기 위해 cycle consistency
loss를 제안함
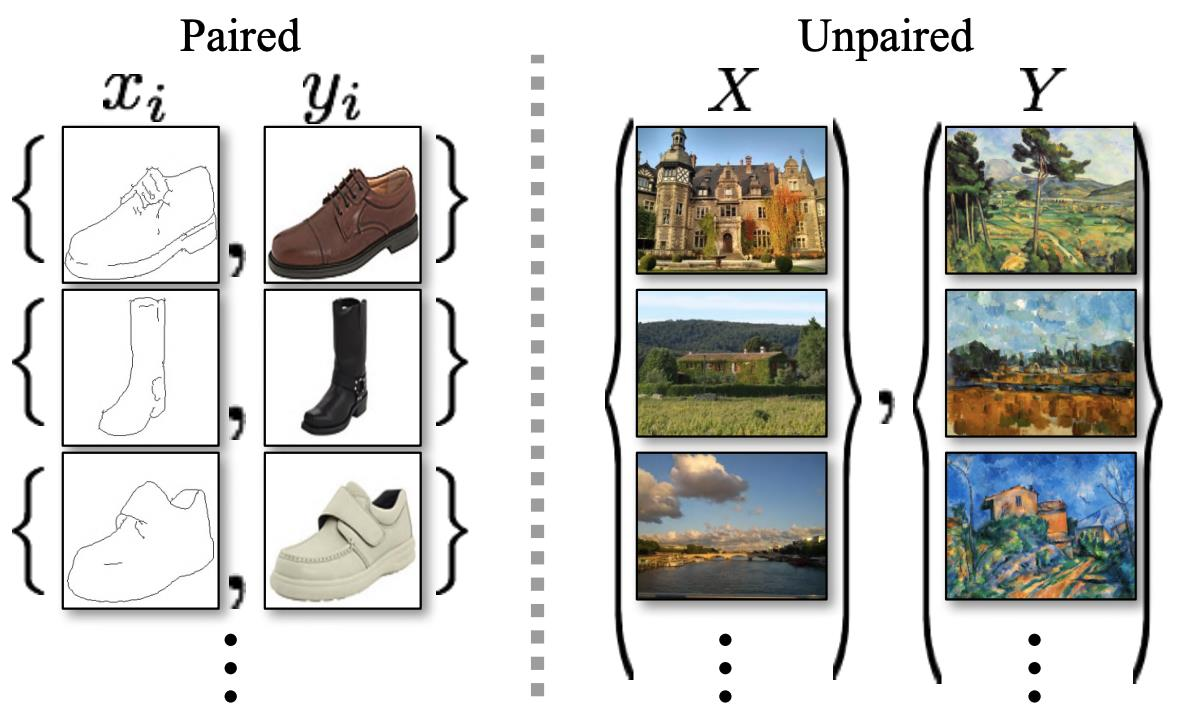
Unpaired images로 학습하여 이미지를 원하는 형태로 변환하는 것이 가능한 방법

CycleGAN loss function
1. Cycle Consistency의 직관적 이해
Cycle Consistency Loss는 다음 두 가지 조건을 만족하도록 학습합니다:
1. 를 로 변환한 뒤 다시 로 변환하면, 와 동일한 값이 나와야 함:
여기서:
- : (도메인 에서 로의 매핑)
- : (도메인 에서 로의 매핑)
- 를 로 변환한 뒤 다시 로 변환하면,와 동일한 값이 나와야 함:
즉, 한 번 변환한 후 다시 원래 도메인으로 돌아왔을 때 입력과 동일한 출력이 되도록 학습합니다.
Total loss:
: GAN 학습을 위한 adversarial training loss
: 생성한 이미지𝐺(𝑥)를 다시 원본 이미지로 생성 𝐹(𝑥) 했을 때 consistency를 유지하기 위한 loss
-> G(x)로 넣어서 생성했다가 다시 F(G(x))를 통해서 역변환해서 x와 차이가 작을 수록 좋은거임
(y일경우는 반대로)
StarGAN
단일 생성 모델만으로 여러 도메인을 반영할 수 있는 구조를 제안
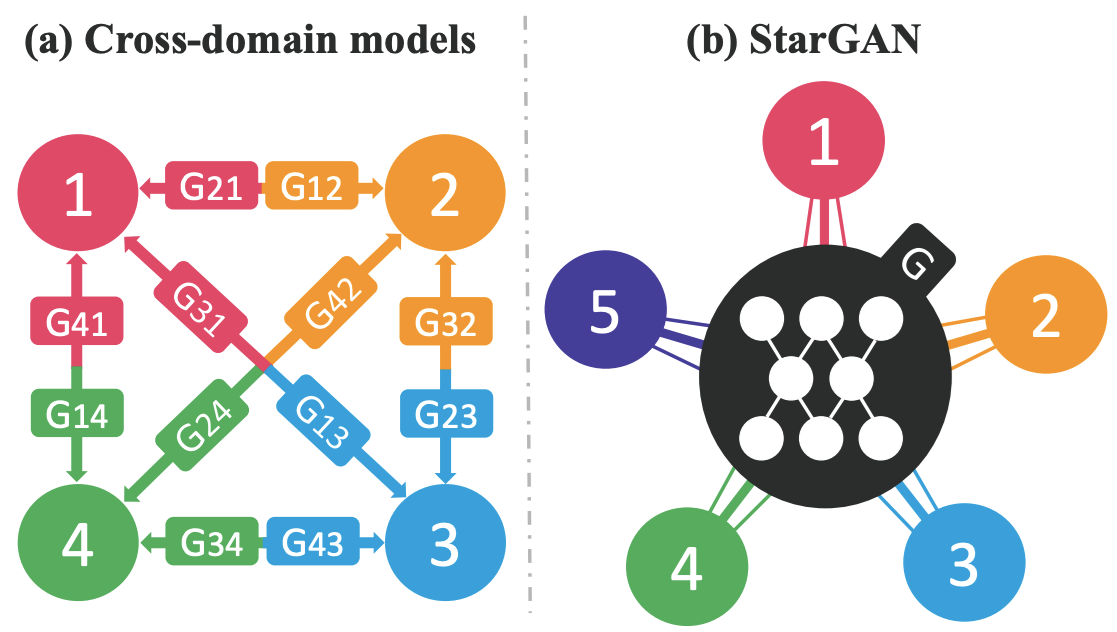
CycleGAN에서 제안된 cycle consistency loss와 domain classification을 활용하여 여러도메인을 반영할 수 있는 모델 구조
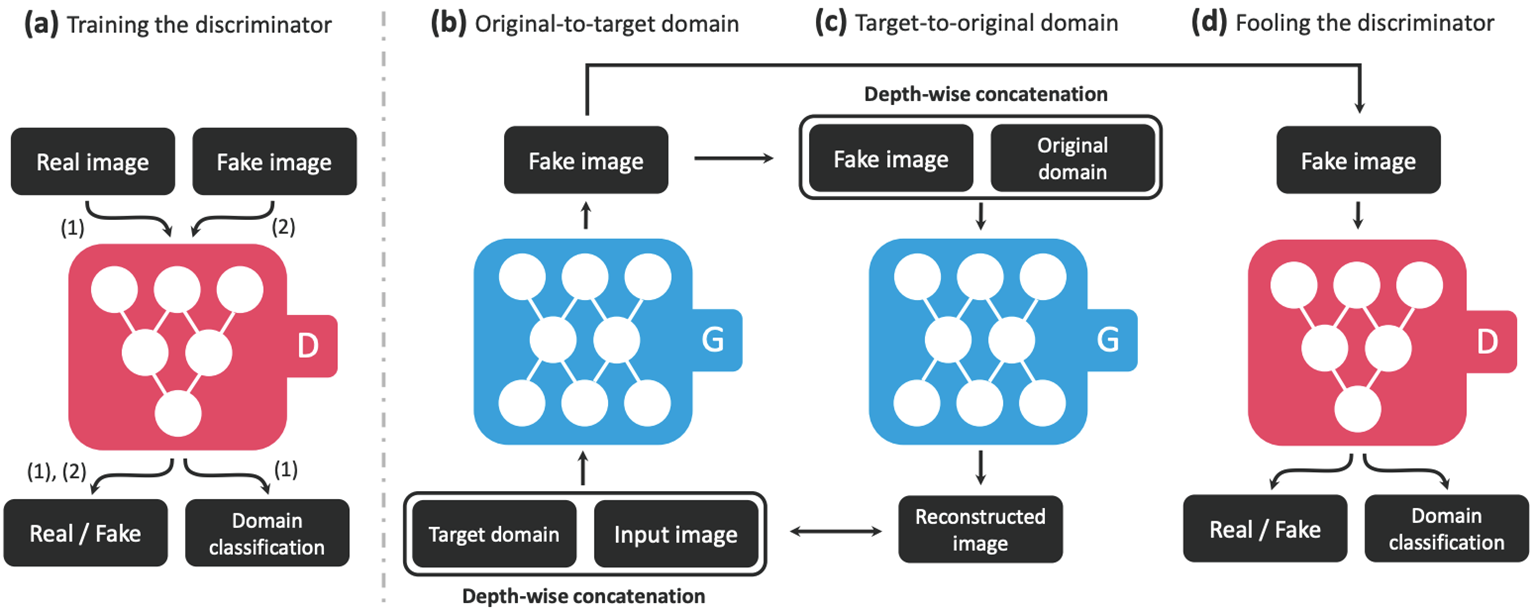
모델 학습을 위해 세 가지 목적 함수를 사용함
- : adversarial training loss
- : 도메인을 판단하기 위한 loss
- : cycle consistency loss
1.
- : 판별자가 $ x$를 진짜(real)로 판단하는 확률
- : 생성자가 입력 와 타겟 도메인 를 사용해 변환된 결과
설명:
- 첫 번째 항: 실제 데이터 를 진짜로 판별하도록 학습
- 두 번째 항: 생성된 데이터 를 가짜로 판별하도록 학습
2.
Domain Classification Loss의 구성:
-
Discriminator를 위한 Domain Classification Loss ()
- 여기서 : 원래의 도메인
-
Generator를 위한 Domain Classification Loss ()
- 여기서 : 타겟 도메인
설명:
- 판별자(Discriminator): 입력 데이터가 어떤 도메인인지 분류하도록 학습
- 생성자(Generator): 변환된 데이터가 타겟 도메인에 속하도록 학습
3.
Cycle Consistency Loss:
- : 원래 입력 데이터
- : 타겟 도메인
- : 원래 도메인
설명:
- 입력 데이터 를 타겟 도메인 로 변환한 후, 다시 원래 도메인 로 변환했을 때 와 동일해야 함을 보장
- CycleGAN의 핵심 손실로, 변환의 일관성을 유지하게 만듦
4. 전체 손실 함수
Discriminator 손실 ():
- 판별자는 Adversarial Loss와 Domain Classification Loss를 기반으로 학습
Generator 손실 ():
- 생성자는 세 손실을 기반으로 학습
도메인의 정의:
- : Original domain (원래 도메인)
- : Target domain (변환 대상 도메인)
결과

1.4 ProgressiveGAN, StyleGAN
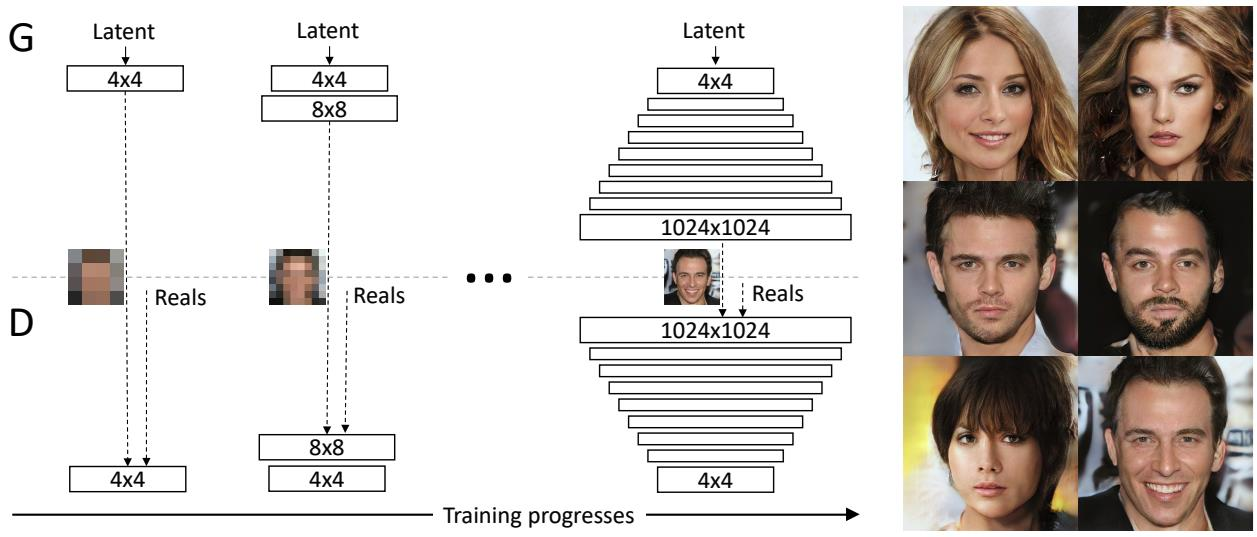
ProgressiveGAN
motivation: 고해상도 이미지 생성 모델을 학습하기 위해서는 많은 비용이 발생함
->고해상도 이미지를 생성하기 위해 저해상도 이미지 생성 구조부터 단계적으로 증강하는 모델 구조를 제안하여 적은 비용으로 빠른 수렴이 가능한 모델 구조를 제안
2. Autoencoders, AEs
2.1 AE(Autoencoder)
Encoder 와 Decoder 로 구성되어 입력 이미지를 다시 복원하도록 학습하는 모델 구조
- Encoder : 입력 이미지를 저차원 잠재 공간Latent space으로 매핑하여 잠재 변수 z로 변환
- Decoder : 잠재 변수를 입력으로 사용하여 원본 이미지를 복원
모델 학습을 위한 목적 함수로는 reconstruction loss를 사용함
- 일반적으로 Mean Squared Error(MSE) 또는 Mean Absolute Error(MAE)를 활용함
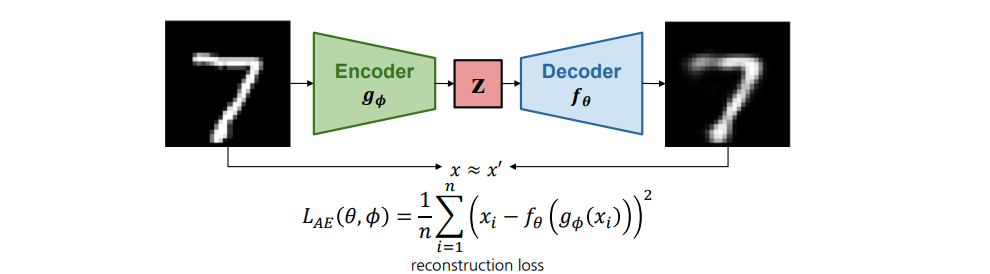
2.2 VAE(Variational AutoEncoder)
Autoencoder와 동일하게 Encoder와 Decoder로 구성되어 있지만 잠재 공간의 분포를 가정하여 학습하는 구조
모델 학습을 위한 목적 함수로는 reconstruction loss 뿐만 아니라 사전에 정의한 잠재 공간에 대한분포를 학습에 반영하기 위해 KL divergence를 함께 정의함
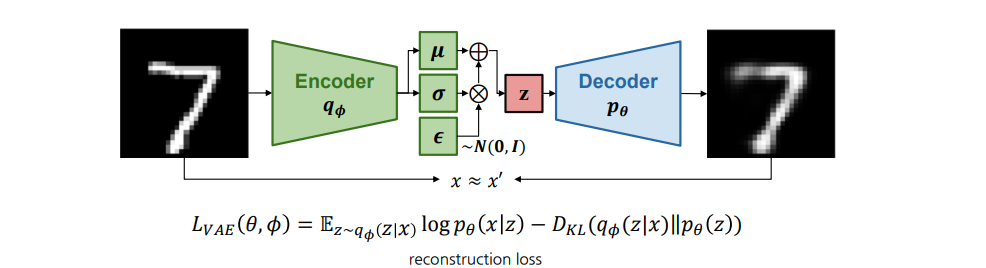
2.3 VQ-VAE (Vector Quantized Variational AutoEncoder)
1. VQ-VAE란?
- 기존 VAE에서 잠재공간(latent space)을 연속(continuous) 대신 이산(discrete)으로 만든 모델 (Autoencoder와 동일하게 Encoder와 Decoder로 구성되어 있지만 잠재 공간의 분포를 가정하여 학습하는 구조)
- Codebook이라는 이산 벡터 테이블을 두고, 인코더에서 나온 임베딩을 가장 가까운 벡터로 양자화(quantize)하여 디코더에 전달
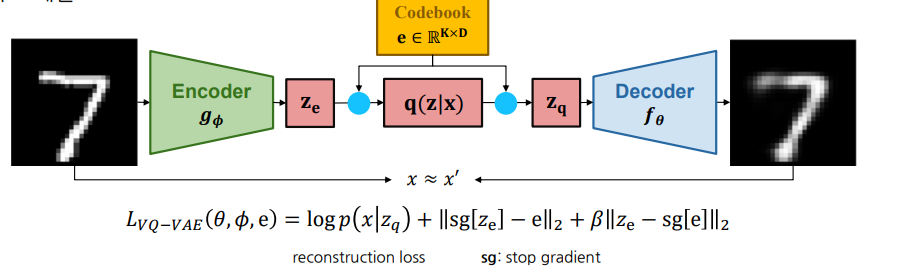
2. 기본 구조
- Encoder
- 입력 를 받아 연속 벡터 를 추출
- Codebook
- (K)개의 이산 임베딩 벡터 집합
- Quantizer →
- 와 가장 가까운 코드벡터 를 선택 → 이를 로 사용
- 역전파가 원활히 이뤄지도록 stop-gradient 트릭(EMA, straight-through) 등을 사용
- Decoder
- (z_q)를 입력받아 원본과 유사한 데이터를 복원
3. 손실 함수
- : 재구성 오류(디코더가 잘 복원하도록)
- $|\mathrm{sg}[z_e] - e|_2^2$*: 코드북을 인코더 출력**에 맞게 업데이트
- : 인코더가 코드북 벡터에 맞춰 조정되도록 유도
- : stop-gradient (해당 부분에 역전파 차단)
4. 과정 정리
- 입력 → Encoder → (연속 벡터)
- 와 가장 가까운 코드벡터 선택 →
- 를 Decoder에 입력하여 복원
- 재구성 손실 + 코드북 업데이트 항들을 합쳐 학습
5. 핵심 요약
- VQ-VAE는 연속 대신 이산 잠재 공간을 사용함으로써 코드벡터 선택이라는 명확한 구조를 얻음
- 코드북 벡터는 학습 과정에서 “분류 토큰”처럼 역할을 수행, 이미지나 오디오 등 복원과 생성에 좋은 성능
- 일반 VAE 대비, 생성 결과가 더 선명하고 학습 안정성도 향상
2.3 VQ-VAE(Vector Quantized)
VQ-VAE는 연속적인 잠재 공간이 아닌 이산적인 잠재 공간을 가정하여 학습에 사용함
이산적인 잠재 공간은 이미지 뿐만 아니라 텍스트, 음성과 같은 데이터에 더 적합함
VQ-VAE에서 정의한 잠재 공간(Codebook)은 사전에 정의한 𝐾개의 embedding으로 정의됨
모델 학습을 위한 목적 함수로는 reconstruction loss에 추가로 e와 encoder를 stop-gradient를 통해 따로 계산
3. Diffusion Models
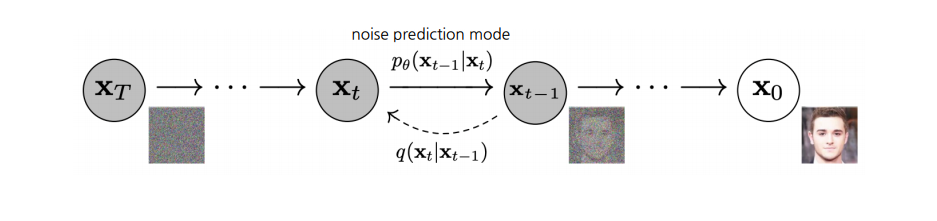
3.1 DDPM(Denoising Diffusion Probabilistic Models)
입력 이미지를 forward process를 통해 잠재 공간으로 변환하고 reverse process로 복원하는 구조
- Forward process: 점진적으로 가우시안 노이즈를 추가하여 잠재공간으로 매핑하는 과정
- Reverse process: forward process에서 추가된 노이즈를 추정하여 제거하는 과정
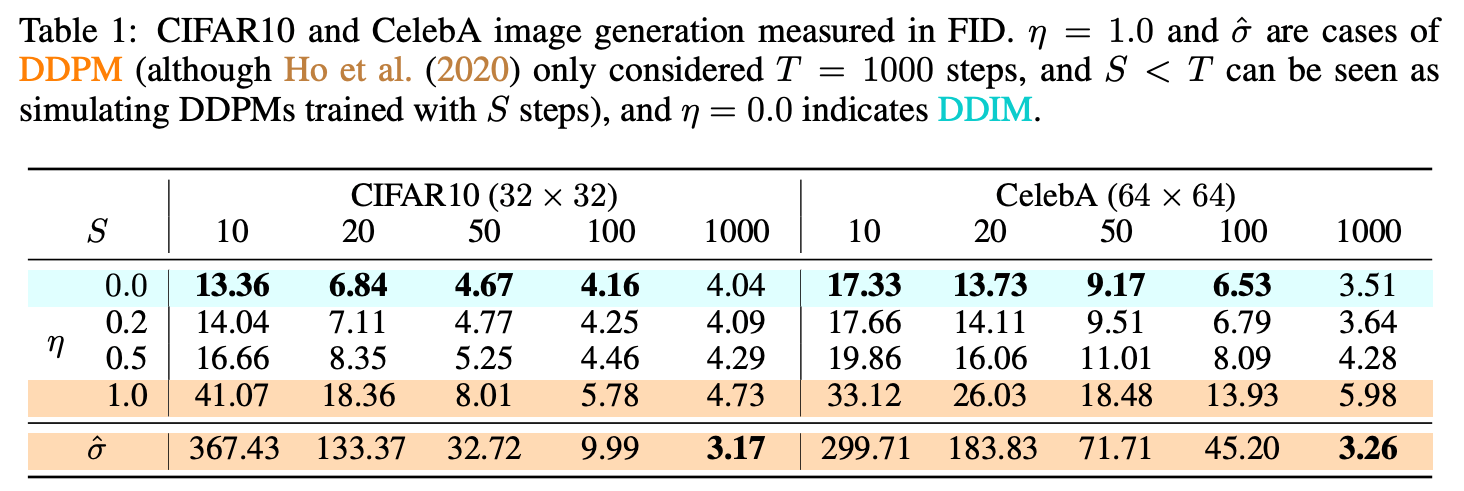
3.2 DDIM(Denoising Diffusion Implicit Models)
DDPM에서의 process는 많은 step 수로 인해 이미지 생성을 위한 시간이 많이 소요됨
DDPM에서 추정 방식의 변화
- DDIM은 stochastic sampling process를 deterministic sampling process로 정의함
- 따라서,생성 과정에서 모든 step을 거치는 것이 아닌 일부만 reverse process를 적용할 수 있게됨

Non-Markovian diffusion process를 적용하여 전체 process의 subset 만으로 좋은 성능을 보임
3.3 CFG(Classifier Free Guidance)
Classifier Guidance
Diffusion Models Beat GANs on Image Synthesis 에서는 GAN보다 더 나은 fidelity를 보이기 위해 모델 구조를 업데이트하고 Classifier Guidance를 활용하여 SOTA를 달성함
Classifier Guidance는 backward process에서 의 noise를 추정할 때 학습한 classifier의 기울기를 통해 임의의 클래스 y로 샘플링을 가이드 하는데 사용됨

- DDIM에 Classifier Guidance를 적용하기 위해 score-based conditioning trick을 적용함
- Score function은 노이즈를 제거하는 과정에서 데이터에 대한 likelihood가 높아지는 방향을 제시함
- Classifier Guidance는 score function에 class y를 조건부로 주입하는 방법

Conditioned score function은 Bayes Rule에 의해 아래와 같이 전개될 수 있음

Classifier Guidance의 문제점
- Classifier Guidance 방식은 기존 diffusion pipeline에 별도의 classifier가 추가되어 복잡해짐
- 모든 step에 대한 classifier가 필요함
Classifier Free Guidance
Classifier-free Guidance에서는 Classifier Guidance의 식을 conditional / unconditional score로 분해하여 재정의함

Noise level 마다 classifier 학습 없이 class에 대한 guidance를 가중치 𝑤 로 조절할 수 있게 됨

3.4 LDM(Latent Diffusion Models)
Latent Diffusion Model (LDM)의 장점
- Diffusion 학습 시 image 사용하는 것이 아닌 encoder를 통해 추출된 저차원의 잠재 변수를 사용함
- 고해상도 이미지 학습에 적은 비용
- Classifier-free guidance 방식을 통해 이미지 생성에 condition을 반영할 수 있음 (Cross-attention)
- 다양한 생성 task (super-resolution, inpainting 등) 가능
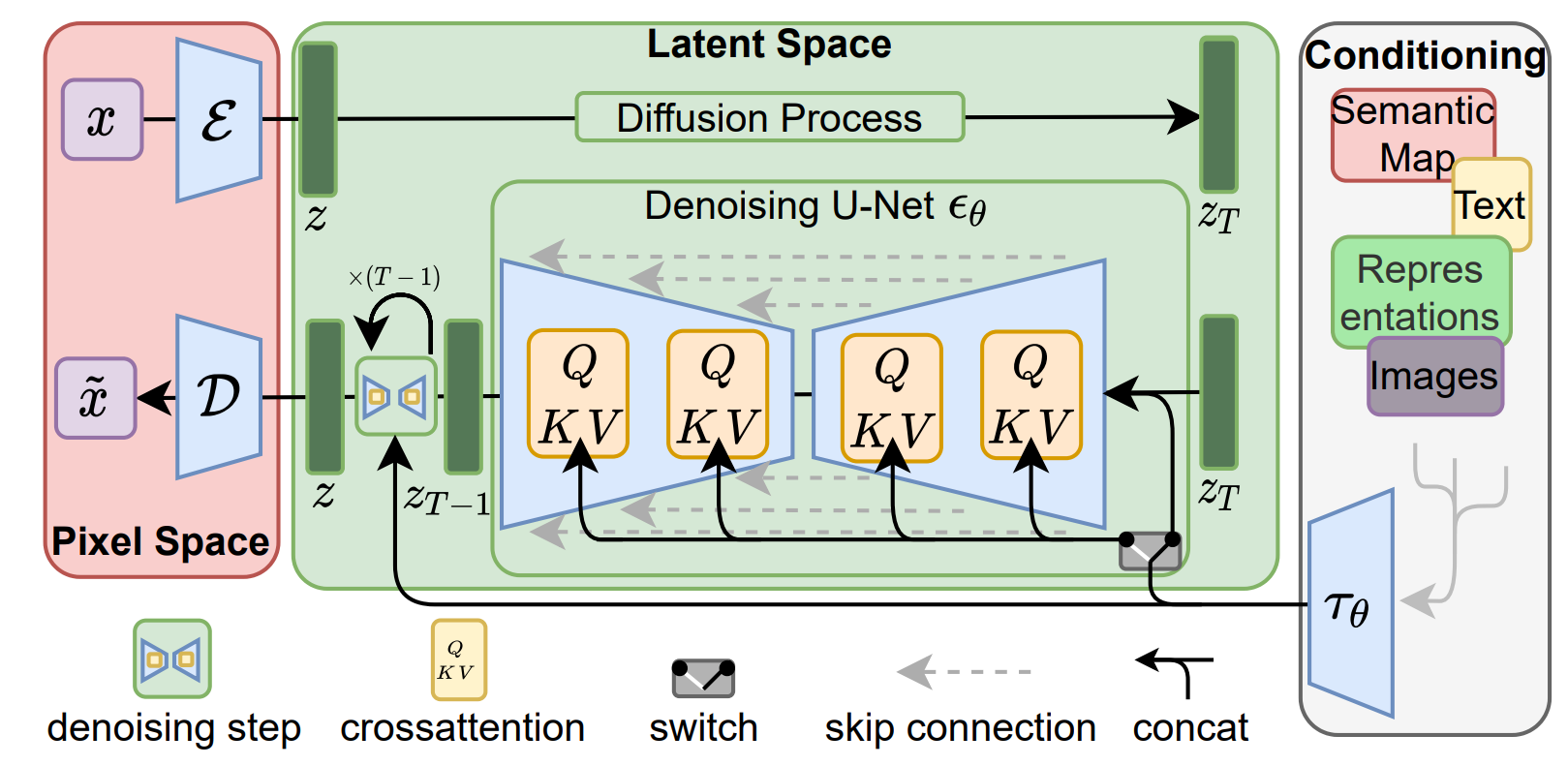
Cross-attention을 통해 condition embedding 반영
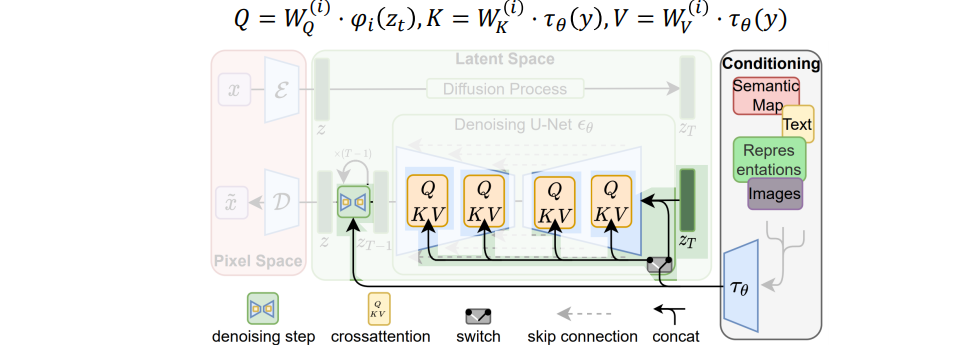
Text-to-Image

Layout-to-Image

Super-resolution

Inpainting

4. 참고사항
-
Generative Adversarial Networks
https://arxiv.org/abs/1406.2661 -
Conditional Generative Adversarial Nets
https://arxiv.org/abs/1411.1784 -
Image-to-Image Translation with Conditional Adversarial Networks
https://arxiv.org/abs/1611.07004 -
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
https://arxiv.org/abs/1703.10593 -
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
https://arxiv.org/abs/1711.09020 -
Progressive Growing of GANs for Improved Quality, Stability, and Variation
https://arxiv.org/abs/1710.10196 -
A Style-Based Generator Architecture for Generative Adversarial Networks
https://arxiv.org/abs/1812.04948 -
Auto-Encoding Variational Bayes
https://arxiv.org/abs/1312.6114 -
Neural Discrete Representation Learning
https://arxiv.org/abs/1711.00937 -
Denoising Diffusion Probabilistic Models
https://arxiv.org/abs/2006.11239 -
Denoising Diffusion Implicit Models
https://arxiv.org/abs/2010.02502 -
Diffusion Models Beat GANs on Image Synthesis
https://arxiv.org/abs/2105.05233 -
Classifier-Free Diffusion Guidance
https://arxiv.org/abs/2207.12598 -
High-Resolution Image Synthesis with Latent Diffusion Models
https://arxiv.org/abs/2112.10752
