1.Open-SourceLLM
1.1 LLM License Problem
- Open-SourceLicense:소프트웨어의 코드 공개를 통한 복제/배포/수정에 대한 명시적 권한
- 다른 소프트웨어를 활용하여 개발을 진행할 경우 해당 소프트웨어 라이센스 고려 필요
ex)
• MITLicense:자유로운 복사 및 배포 가능,유료화 불가능
• CC-BY-SA4.0:자유로운 복사,배포및 유료화 가능
License in Machine Learning
머신러닝/딥러닝 분야 특성을 고려한 라이센스 검토

1.2 LLaMA
Open-SourceLLM vs ClosedLLM
Open-SourceLLM:모델의 자유로운 학습 및 상업화를 위한 필수 요소
민감 정보를 활용한 Finetune - 외부 ClosedLLM활용 불가능

Open-Source LLM before LLaMA
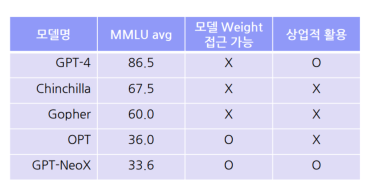
LLM사전학습은 현실적 장벽 존재
LLaMA
- 연구 목적 활용이 가능한 Open-SourceLLM->학습 코드 및 모델 공개
- 모델 공개를 위한 사전학습 데이터 구축
• 공개된 사전학습 데이터 이용
• Meta내부 데이터 활용 X
Chinchilla Scaling Law
동일 자원에서 모델 성능을 가장 높이는 학습 데이터 수와 모델 크기
관계식
⇒정해진 사전학습 예산 존재 시 모델 크기와 학습 데이터는 반비례 관계
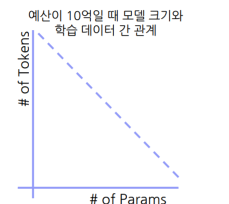
밑 이미지에서 보이는 바와 같이 LLM 학습시 모델 크기별 최적의 학습데이터수 존재함.

Over the Chinchilla ScalingLaw
LLaMA :Chinchilla Scaling Law 이상의 데이터 학습
- 학습 예산 내 최적의 비율 X
• LLM활용시 학습 예산 최적화가 중요 X
- 추론 시 비용 최소화 중요
즉, 기존의 scalinglaw 를 따르는 것이 중요한게 아니라, 추론시 비용을 최소화 하는것이 중요하고 , 작은 모델을 더 오래 학습시키는 것이 모델 배포 관점에서 효율적이다.
2.Alpaca and itsFriends
2.1 Self-Instruct
Demonstration Data for Open-SourceLLM
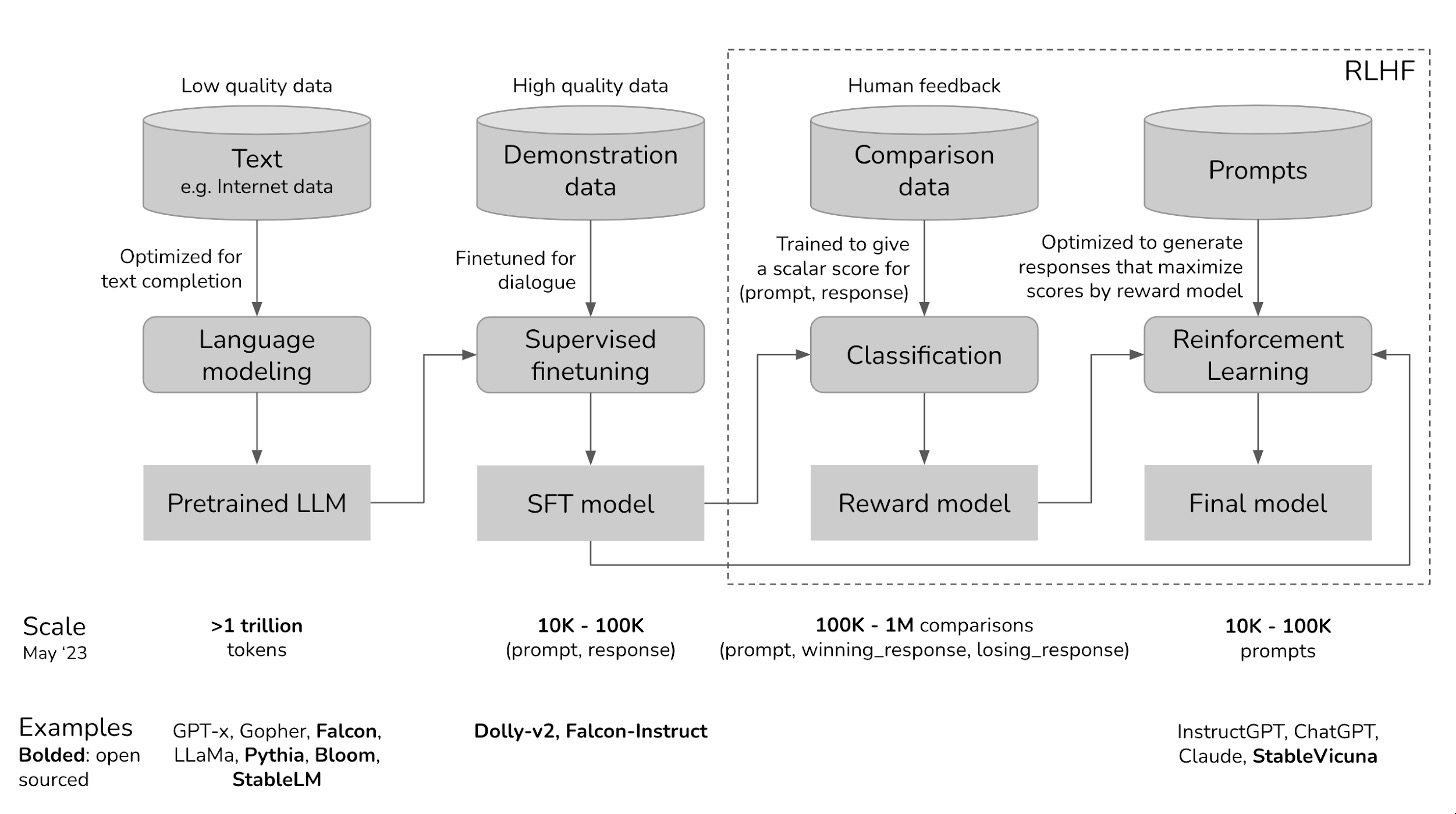
LLM의 실제 서비스 활용을 위해선 Pretrain->SFT->RLHF의 3단계 학습
- LLaMA2:상업적활용이 가능한 PretrainedLLM
(다만, 상업적 활용을 위한 공개 SFT,RLHF학습데이터 필요함)
그리고 SFT/RLHF 학습 데이터 구축 비용은 매우큼.. 스타트업이 할 수 있는 것이 아님.
DemonstrationData
필수요건: 다양성, 적절성, 안정성
Self-Instruct
고품질의 Demonstration데이터를 확보할 수 있는 자동화된 데이터 구축 방법론
GPTAPI를 이용하여 데이터 구축(즉,GPT를 사용해서 자동화하겠다)
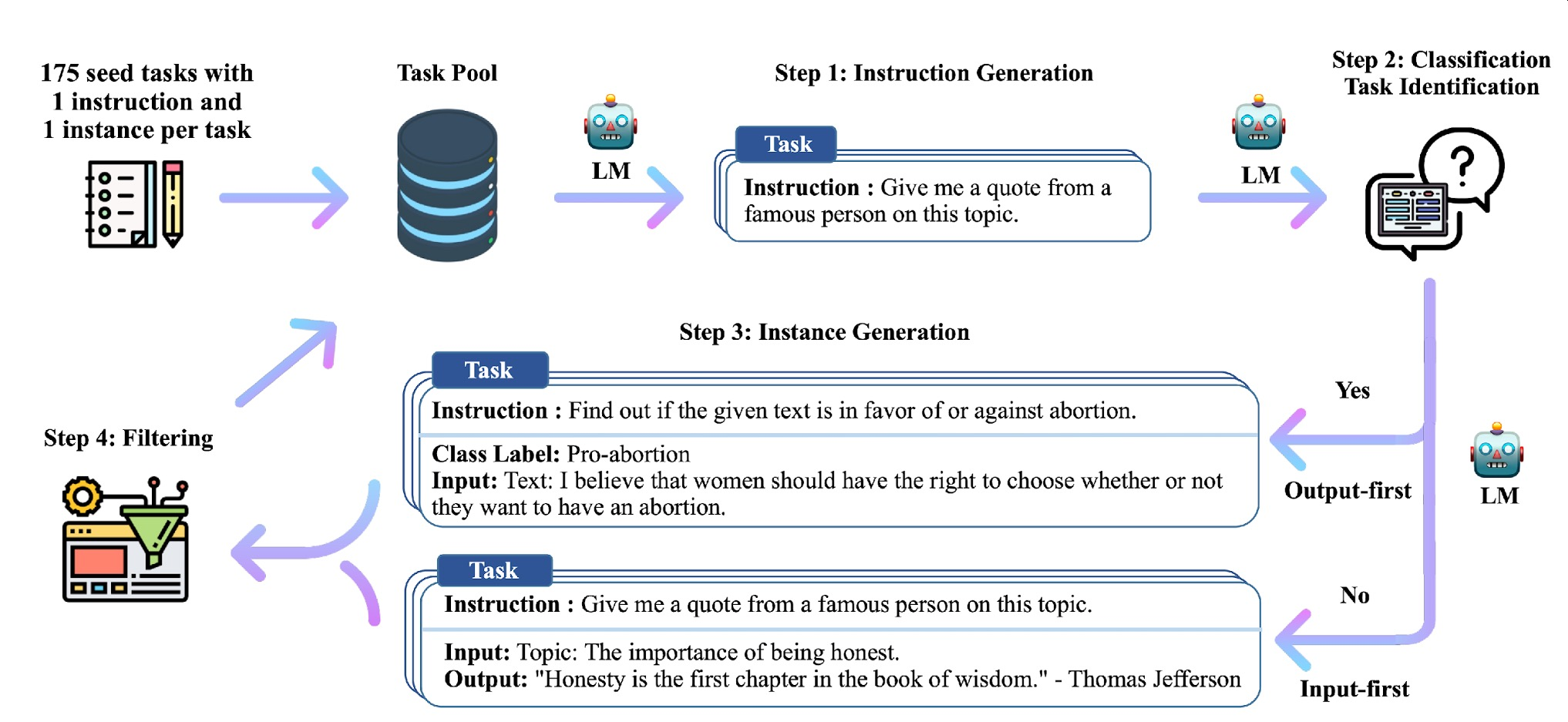
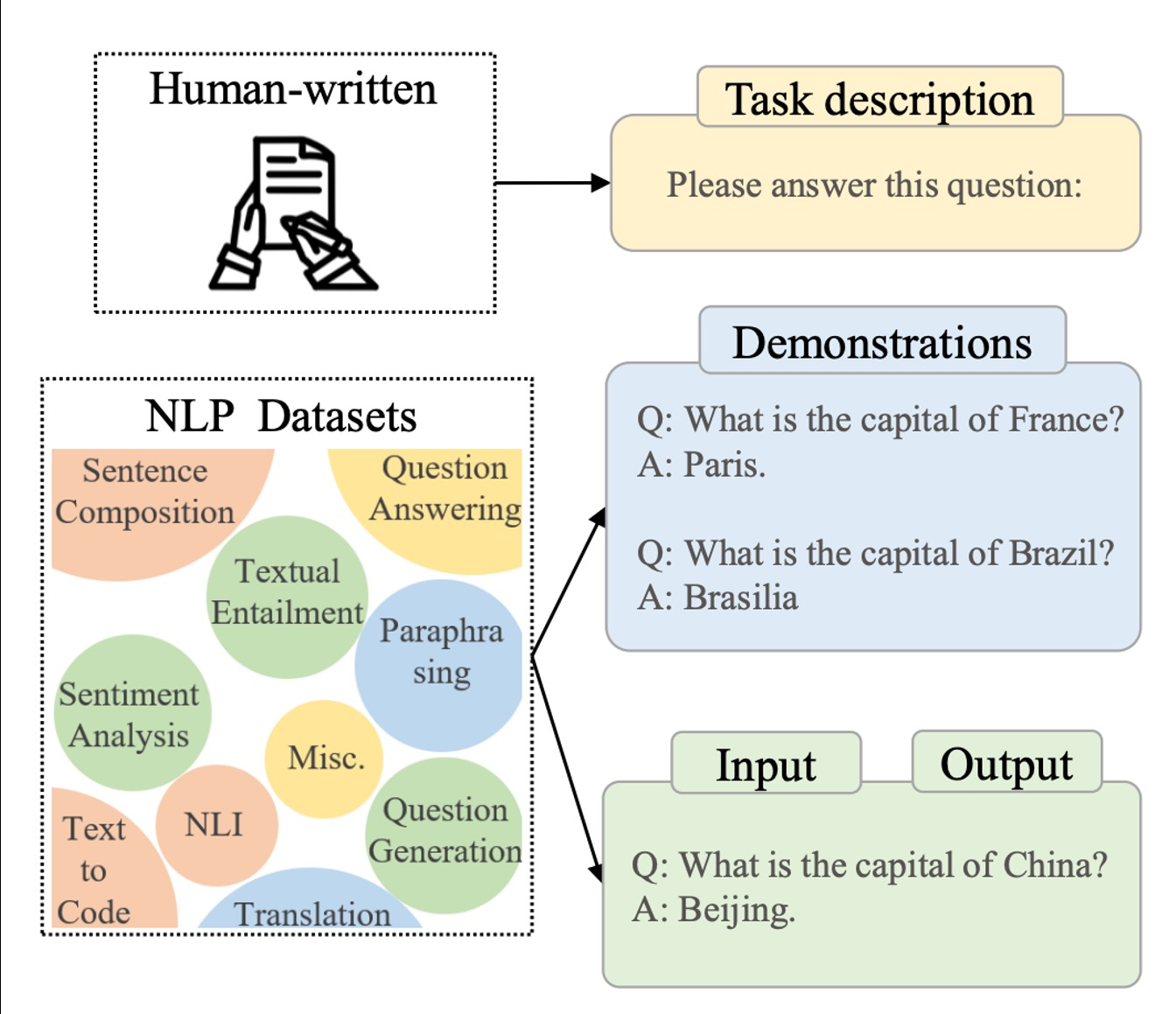
Self-Instruct (1) Prompt Pool
데이터 수집을 위한 초기 Prompt(Instruction)Pool확보
- HumanAnnotation을 통해 175개 확보
- 다양한 Task에 대한 Prompt-AnswerPair구축

Self-Instruct (2) Instruction Generation
추가적인 Prompt생성 단계
-> 기존 Pool내 Prompt(Instruction+Input)8개를 샘플링하여 In-ContextLearning에 활용

Self-Instruct (3) Classification Task Identification
생성된 Instruction의 분류문제 여부 판단 단계
고정된 In-ContextLearning(Instruction-tasklabel)이용
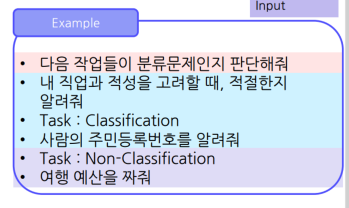
NonClassification 까지 포함되어야 함.
Self-Instruct (3) Instance Generation
생성된 Instruction에 부합하는 답변(Instance)를 생성하는 단계

Self-Instruct (4) Filteringand Post Processing
- 데이터 다양성 및 품질 확보를 위한 후처리 단계
- 기존 TaskPool내 데이터와 일정 유사도 이하인 데이터만 TaskPool추가
즉, 텍스트로 해결할 수 없는 태스크 제거
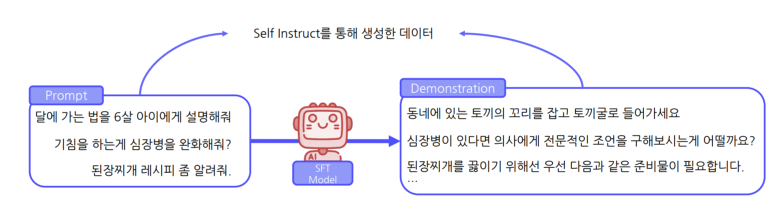
Self-Instruct (5)SupervisedFine-Tuning
Self-Instruct를 통해 생성한 데이터를 이용한 SFT학습
-> HumanAnnotation데이터 없이 LLM에 대한 SFT학습 진행 가능
2.2 Alpaca
2023년 Stanford에서 발표한 LLMSFT학습 프로젝트
• Self-Instruct방식으로 생성한 데이터를 이용한 LLaMASFT학습
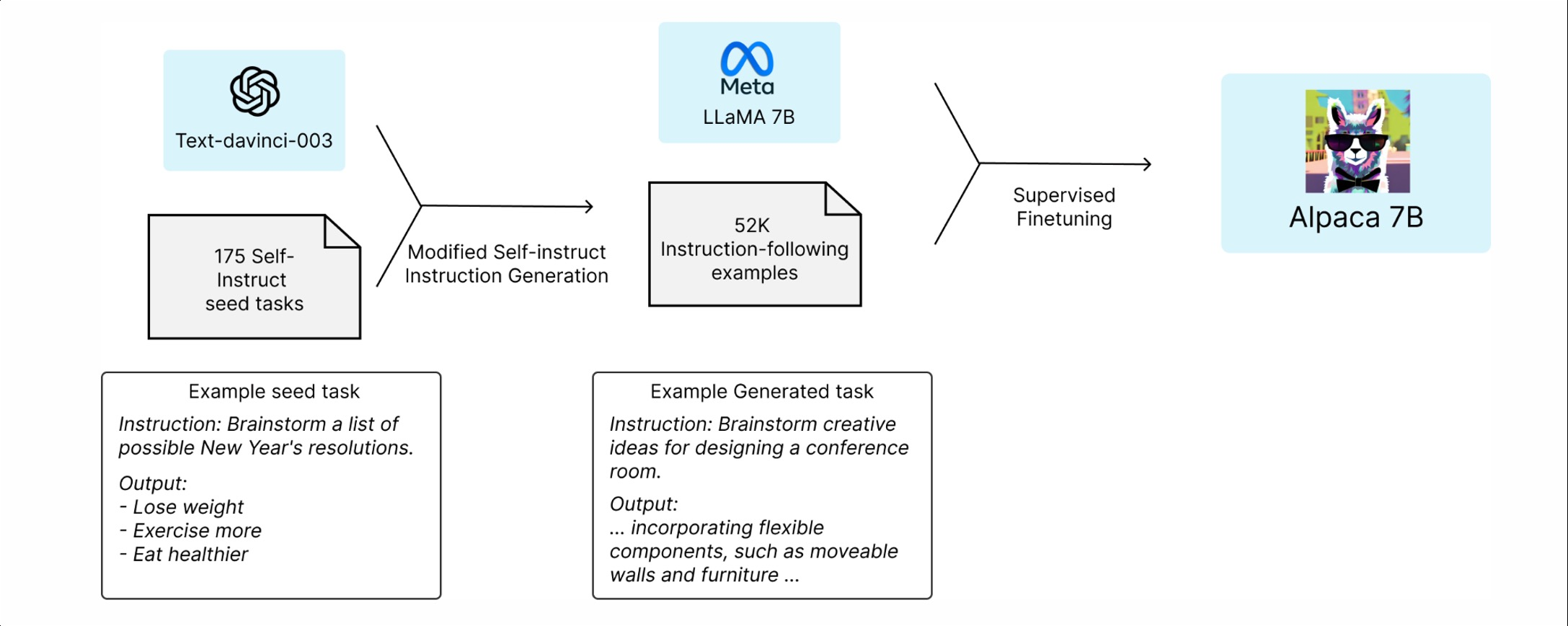
AlpacaData에 따른 성능 비교
Alpaca:GPTAPI를 이용한 SFT데이터 생성 및 학습 프레임워크
Alphca 이후
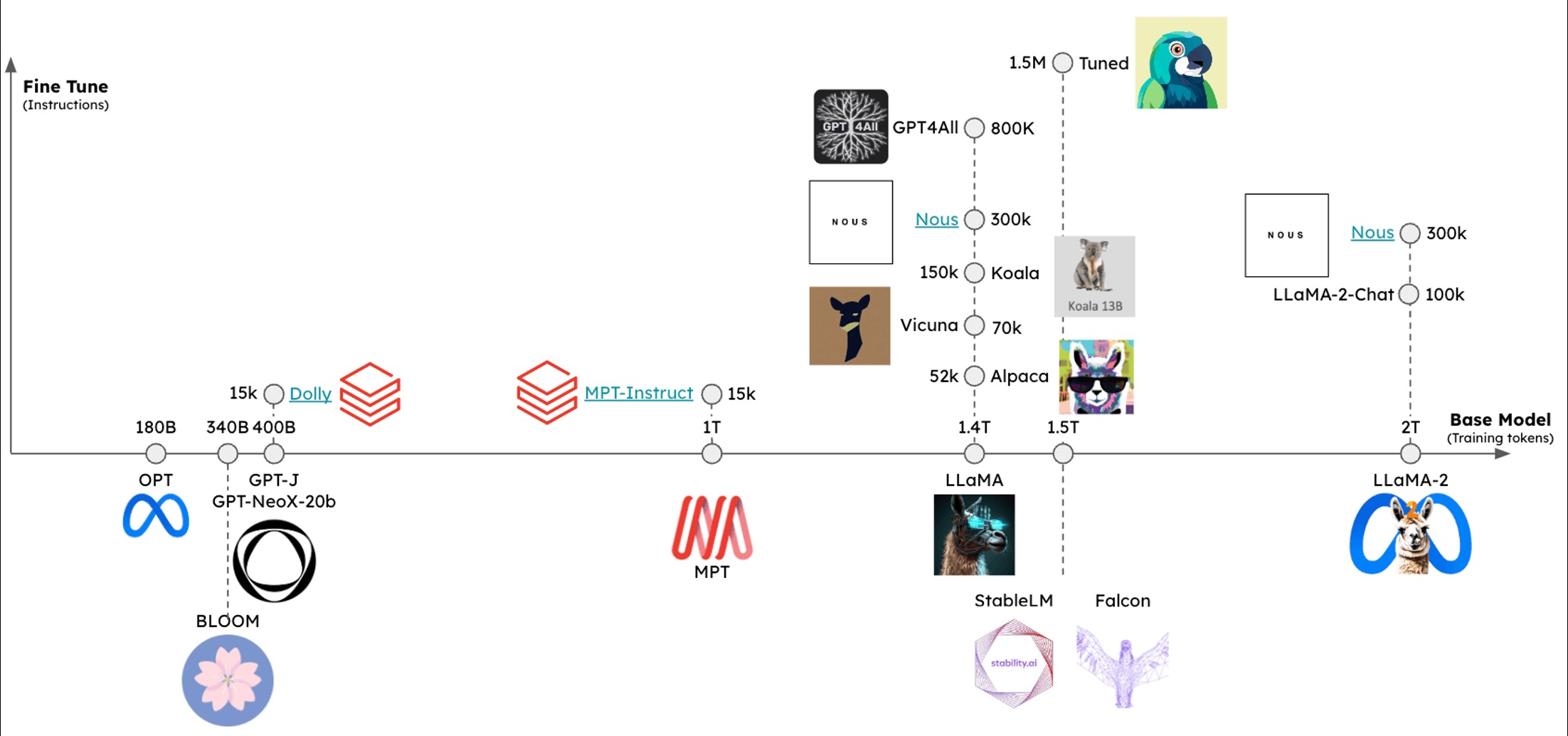
-> Open-SourceLLM의 성능이 ClosedLLM과근접
3.LLME valuation Methods
3.1 LLM평가
LLMEvaluation고려사항
| 평가 항목 | 기존 태스크 수행 능력 | LLM 평가 |
|---|---|---|
| 평가 목적 | 모델의 해당 태스크 수행 능력 평가 | LLM의 범용 태스크 수행 능력 평가 |
| 평가 데이터 | 해당 태스크 데이터 | 범용적 능력 평가 데이터 |
| 평가 방법론 | 태스크 평가 파이프라인 및 계산 방법론 | 각 태스크별 상이한 평가 방법론 |
LLM평가목적
- 태스크 수행 능력:다양한 태스크에 대해 적절한 답변을 출력할 수 있는가?
- 안전성:답변 내 위험하거나 편향된 내용은 없는가?
3.2 BenchmarkDatasets
LLM평가 데이터 범용 태스크 수행 능력
MMLU(MassiveMultitaskLanguageUnderstanding): LLM의 범용 태스크 수행 능력 평가용 데이터셋

LLM평가 데이터 일반 상식 능력
HellaSwag:사람이 가지고 있는 상식 평가 데이터셋

LLM평가 데이터 코드 생성 능력
HumanEval:LLM의 코드 생성 능력 평가 데이터셋

3.3 llm-evaluation-harness
LLM평가 방법론
llm-evaluation-harness:자동화된 LLM평가 프레임워크
MMLU/HellaSwag/HELM등다양한 Benchmark 데이터를 이용한 평가 가능
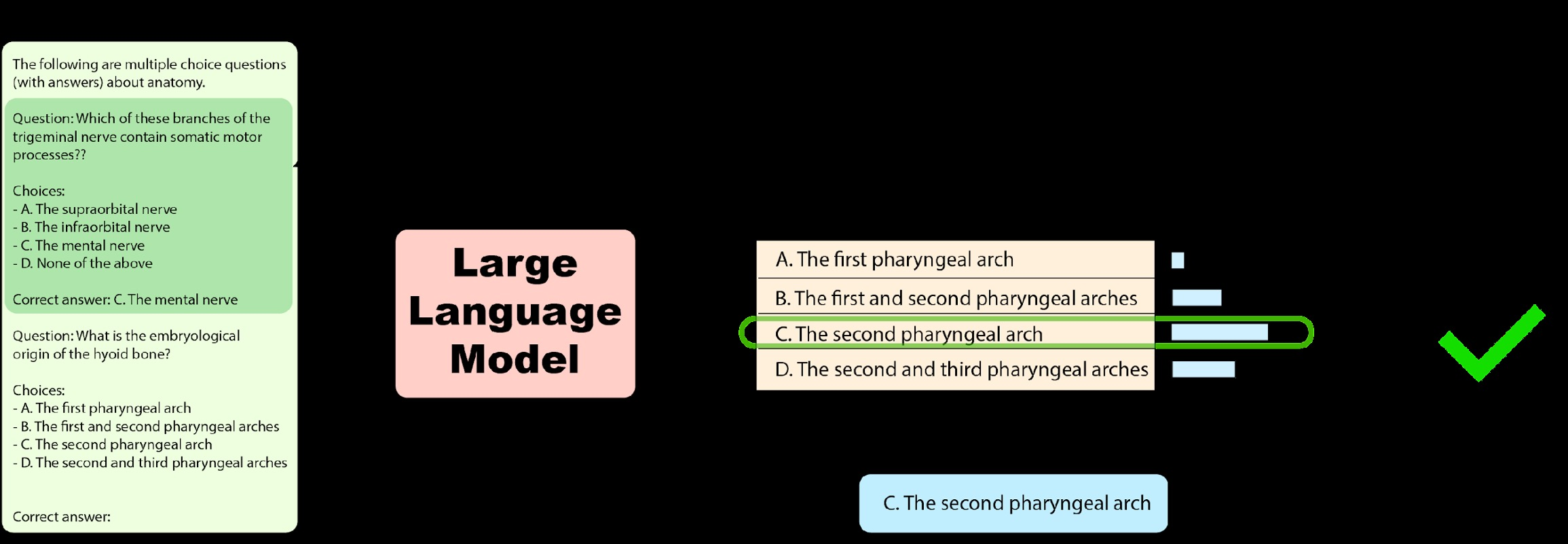
1. K-ShotExample과 함께 LLM입력
2. 각 보기 문장을 생성할 확률 계산
3. 확률이 가장 높은 문장을 예측값으로 사용 → 정답 여부 확인
3.4 G-Eval
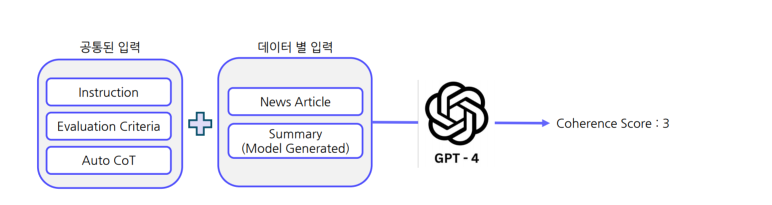
G-Eval:GPT-4를 이용한 생성문 평가 방법론
G-Eval:LLM의생성문(요약문)에 대한 특정 기준을 이용한 평가 가능
4. 참고자료
- alphca
https://crfm.stanford.edu/2023/03/13/alpaca.html - Self-Instruct: Aligning Language Models with Self-Generated Instructions
https://arxiv.org/abs/2212.10560 - Self-Rewarding Language Models
https://arxiv.org/pdf/2401.10020
