1. 개발
python

Linux

clean code

2. 데이터엔지니어링
AI Engineer는 데이터모델링+데이터개발영역을 커버하길 원하는 추세

실시간 데이터처리 : Kafka,Apache Spark Streaming...
메세지 시스템: Kafka,Redis,AWSSQS,GCPPubSub,Celery
분산 처리: Ray,ApacheSpark
데이터 웨어하우스: GCPBigQuery,AWSRedshift
캐싱: Redis
BI(BusinessIntelligence): Superset,Redash,Metabase
ETL파이프라인: 어떻게구성할것인가?
| 구분 | Kafka | Redis |
|---|---|---|
| 주요 목적 | 대규모 실시간 스트림 데이터 처리, 메시지 큐 | 인메모리 기반 초고속 키-값 데이터 저장/캐시 |
| 아키텍처 | 토픽 기반 퍼블리시/서브스크라이브 구조, 디스크 기반 로그 저장 | 키-값, 리스트, 해시, 정렬된 집합 등 다양한 자료구조 인메모리 관리 |
| 데이터 영구성 | 디스크 기반 메시지 로그 유지 (보존 기간 설정 가능) | 주로 메모리에 저장, RDB/AOF 백업 가능하나 핵심은 캐싱/고속 접근 |
| 메시지 처리 모델 | 토픽 → 파티션 → 컨슈머 그룹, 오프셋 기반으로 독립적 소비 가능 | 기본 get/set, Pub/Sub 시 단순 중계(메시지 영구저장 X), Redis Streams 사용 시 유사한 스트림 처리 가능 |
| 확장성 | 파티션 단위로 확장 용이, 대규모 스트림 처리에 최적화 | 클러스터링/샤딩 지원으로 확장 가능하나, 주요 용도는 빠른 데이터 접근/캐시 |
| 주요 활용 사례 | 실시간 이벤트 스트림 처리, 로그 수집, 마이크로서비스 비동기 통신 | 캐시, 세션 스토리지, 실시간 랭킹, 빠른 읽기/쓰기 요구되는 데이터 관리 |
Kafka는 실시간 스트림 처리와 메시지 영구 저장, 높은 처리량, 소비자 그룹 관리에 특화된 분산 메시징 플랫폼입니다.
Redis는 인메모리 기반의 초고속 키-값 데이터 저장소로, 캐시나 세션 관리, 간단한 Pub/Sub 용도로 사용되며, 데이터 접근 속도에 초점을 맞춥니다.
Apache Spark은 분산 데이터 처리를 위한 오픈 소스 프레임워크이며 대규모 데이터 처리를 위한 분산 컴퓨팅 기능을 지원합니다. 이를 통하여 다양한 데이터 처리 작업을 수행하고 실시간 데이터 처리나 대화형 데이터 분석, 머신 러닝 등의 기능 구현에 적용할 수 있습니다. 관계형 데이터베이스 시스템과는 다른 개념입니다,
3. ComputerScience
네트워크
OS
자료구조
알고리즘
-> 지금 구매한 책만 읽어도 충분할 듯.
4. Cloud,Infra
어느정도 인프라에 대한 이해가 있을수록 인프라엔지니어와 이야기할 때 수월함

IaaC
GUI에서 클릭하면서 클라우드 서비스를 사용했으나,인프라를 코드로 관리할 수 있는 Terraform
https://www.44bits.io/ko/keyword/terraform
모니터링
Prometheus
https://github.com/prometheus/prometheus
Grafana
https://github.com/grafana/grafana
5. Database
데이터를 저장하는 곳은 Object Storage,NoSQL도 있지만
여전히 RDB에 저장을 많이 함
효율적으로 저장하려면 어떻게 해야 할까?
Index전략 등
저장한 데이터를 추출할 수 있도록 SQL
데이터웨어하우스로 데이터를 옮기기 위한 고민
6. Modeling
본인의 분야(CV,NLP,Rescyc)등 최신 SOTA 분야에서의 논문이 지속적으로 나올 것임.
-> 이를 꾸준히 읽고 하는 것이 중요함.
7. 추천컨텐츠-기술블로그&발표영상&논문
기술블로그 모음
https://github.com/seonggwonyoon/techblog
-> 자신이 관심있어하는 회사나 분야의 기술을 무엇을 썼는지 지속적으로 관심있게 보는 것이 필요함.
(이러한 어플을 하나 만들어보는게 어떨까생각함)
8. 대규모 시스템 설계

9.이런것들을 학습해야 하는 이유
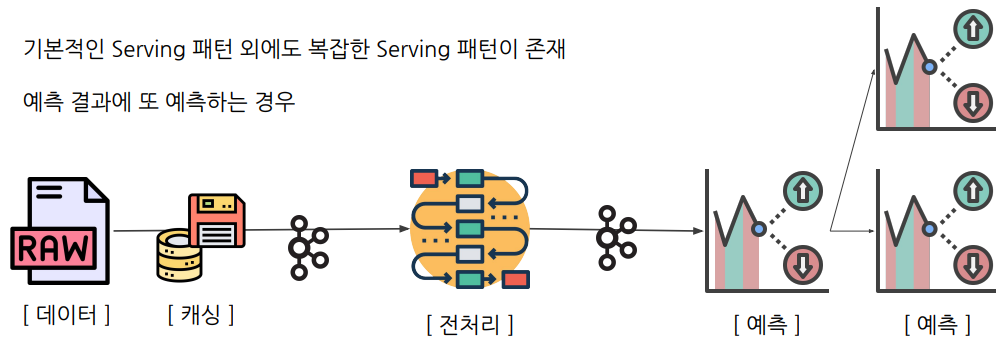
머신러닝 디자인패턴
https://mercari.github.io/ml-system-design-pattern/

디자인패턴의 코드구현
https://github.com/shibuiwilliam/ml-system-in-actions
10. 자신에 대한 고찰.
당장 내년에 졸업반임
-> 취업이나 창업 등 갖가지 문제가 있는데 가장 큰 문제는 "돈"임.
무엇을 하더라도 남는게 있는 걸 해야함. 여기서 "남는게"라는 말은, 실패해도 배우고 하는게 있다는 것임. 실패를 바탕으로 더 갈 수 있는게 있다는 말임.
고시같은 것은 실패하면 0으로 남는게 없음.
나는 이런거에 도박하면 안됨. 이제는 시간이 별로 없음.
실패하더라도 기술이 남고 IT기술에 접목할 수 있고 AI의 기술을 발전시켜서 기술 진입장벽의 높이를 남길 수 있는게 필요함.
나는 금융 + 투자 + IT + AI + Computer Vision에 흥미가 많음.
이를 바탕으로 어플리케이션 만들 수도 있고 그외의 것도 있을 수 있음
먼저 flutter + java 등을 통해서 어떻게 프론트와 백엔드를 구성할지를 고민해 보는게 좋을거 같음.
그 두 가지 기술을 익히고 발전시켜서 졸업할때 9,10월에는 적어도 10개 이상의 웹과 어플을 출시해봐야함.
그리고 후에 시장같은것도 조사해서 스타트업에 들어가서 근무경력을 쌓는것도 좋다고 생각함.
11. quiz 로 배운것
Asynchronous Serving은 예측 작업을 서버의 백그라운드에서 처리하므로 클라이언트는 결과를 기다리지 않고 다른 작업을 계속할 수 있습니다. 이 방식은 서버 부하를 분산시키고 사용자 경험을 향상시키는 데 유용합니다.
XComs은 작업 간 데이터 공유에 사용되며, 민감한 정보의 경우 암호화를 적용하여 보안을 강화할 수 있습니다. Helm Chart 는 쿠버네티스 패키징 파일 컬렉션이며, Variable 은 Airflow 에서 사용되는 전역 변수입니다. Sensor 는 Airflow Task 실행 조건을 정의할 수 있는 오퍼레이터이고, Kubenetes Executor 는 Kubernetes 환경을 활용해 Worker 를 실행하는 Executor 입니다.
Airflow Celery Executor 는 메시지 큐 시스템 기반으로 Task를 병렬로 실행하도록 지원하며 HA 구성과 Scale-Out 설정에 용이합니다. 즉 문제에서 언급한 Broker는 Task를 전달하는 역할을 담당합니다. RabbitMQ, Redis, Apache Kafka 등으로 설정이 가능합니다
REST API에서 PUT 메서드는 기존 리소스의 전체를 업데이트할 때 사용됩니다. 이 메서드는 기존 데이터를 완전히 대체하며, 해당 리소스가 존재하지 않을 경우 새로 생성할 수도 있습니다. 반면 PATCH 메서드는 리소스를 부분적으로 업데이트할 때 쓰입니다.
Dependency Injection은 FastAPI에서 재사용 가능한 컴포넌트를 효율적으로 관리하고 코드의 유지 보수를 용이하게 하는 데 사용됩니다. 이는 코드의 모듈성과 유연성을 높여 줍니다
Middleware는 FastAPI에서 클라이언트의 요청을 받고 응답하기 전과 후에 수행되는 중간 단계의 작업을 의미합니다. 이는 로깅, 인증, 데이터 처리 등의 작업에 사용됩니다.
