Necessity of Light-weighting and Acceleratio
전력사용 , 자율주행, on-device 모델에서는 경량화 모델이 필요함.
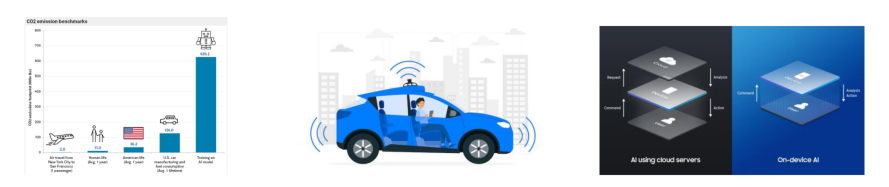
- AI 모델의 거대화로 인해 계산 자원량의 기하급수적 증가.
- 다양한 환경에서 이러한 거대 모델을 운영하기는 다양한 현실적인 문제들이 발생.

1. AI Model Lightweighting
모델 경량화
: AI 모델의 크기를 줄이고 계산 비용을 감소시키면서도, 필요한 모델의 성능을 최대한 유지하는 기술
주요 기법:
- Pruning - 가지치기
- Knowledge Distillation - 지식 증류
- Quantization 양자화

1.1 Pruning
학습된 모델에서 중요도가 낮은 뉴런이나 연결을 제거하여 모델의 크기와 계산 비용을 줄이는 기법.
- Structured Pruning: 뉴런, 채널, 혹은 레이어 전체를 제거하는 방식
- Unstructured Pruning: 연결된 가중치를 개별적으로 검증하여 독립적으로 제거하는 방식.
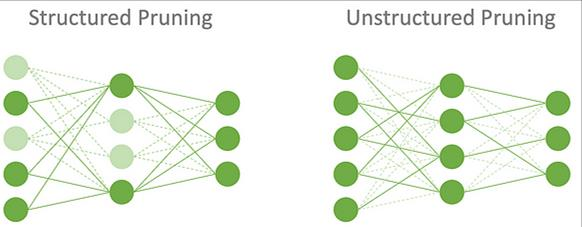
Pruning 결과

1.2 Knowledge Distillation
고성능의 Teacher 모델로부터 지식을 전달 받아서 Student 모델을 학습 시키는 기법
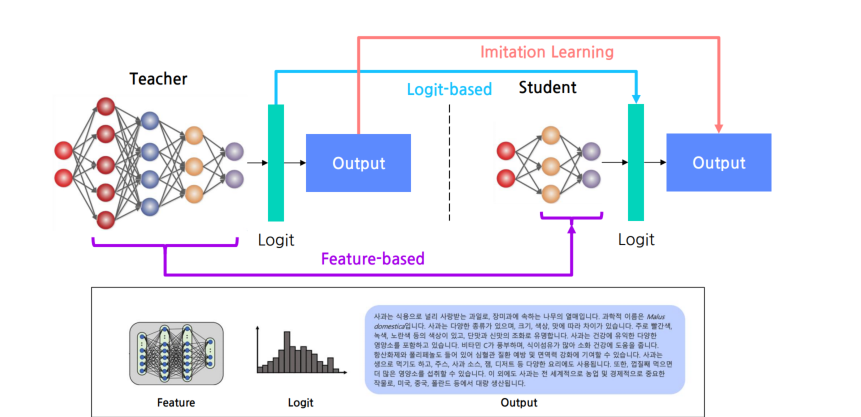
-
White-box KD: LLaMA와 같이 공개된 모델을 교사모델로 활용하여 학습하는 경우
ex)Logit-based KD, Feature-based KD -
Black-box KD: ChatGPT와 같이 비공개 모델을 교사모델로 활용하여 학습하는 경우
ex) Imitation Learning

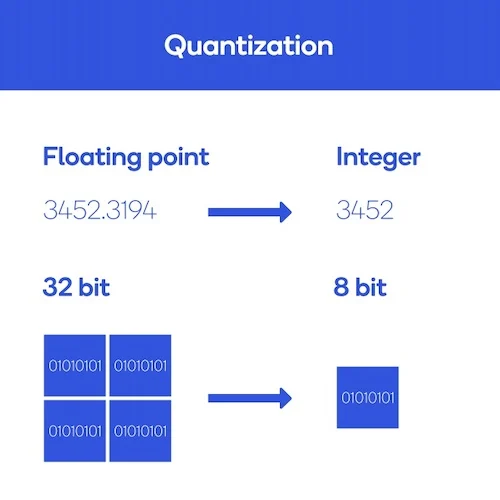
1.3 Quantization
모델의 가중치와 활성화를 낮은 비트 정밀도로 변환하여 저장 및 계산 효율성을 높이는 기법. 예를 들어 32비트 부동소수점을 8비트 정수로 변환
2. AI Model Lightweight Re-training
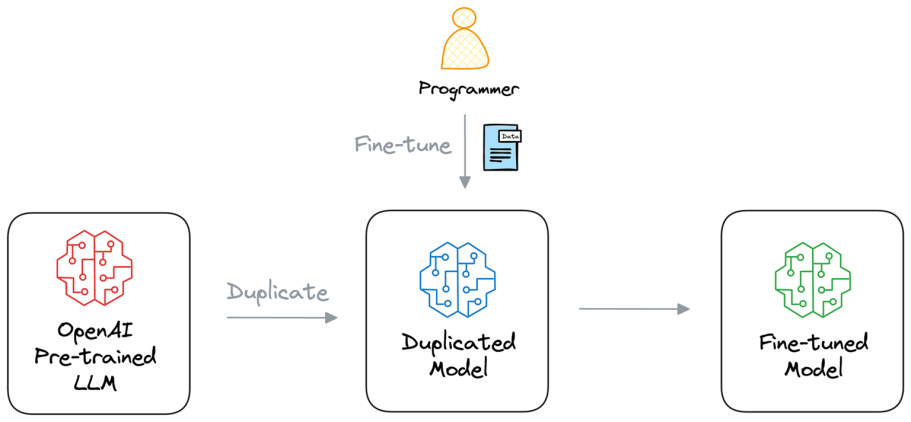
Fine-tuning은 모델의 모든 파라미터를 업데이트하는 방법
-> 하지만 이는 큰 모델일수록 학습비용이 매우 크게 됨.
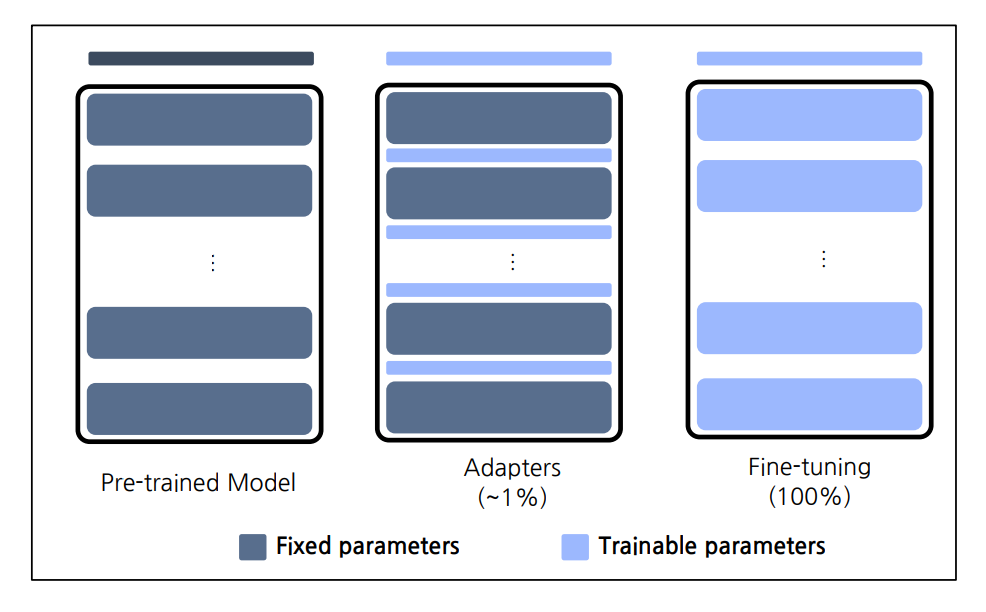
파라미터 효율적인 전이 학습 (Parameter-Efficient Fine-Tuning - PEFT)
PEFT기법은 훈련된 모델을 자원 효율적인 방식으로 재학습하는 방식을 통칭함.
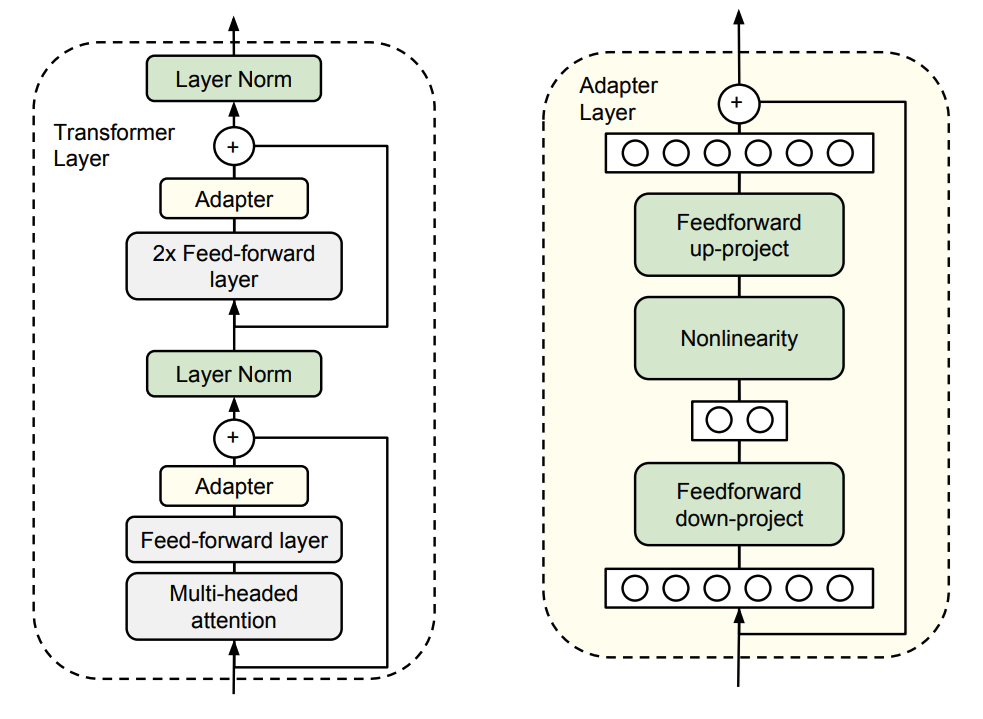
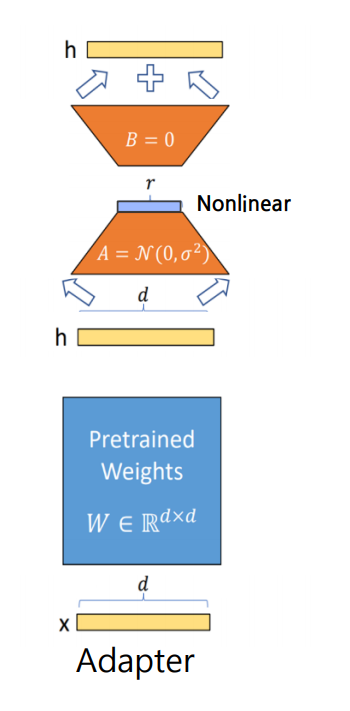
2.1 Adapter
기존 네트워크의 가중치는 고정한 채로 레이어 사이에 새로운 layer를 추가하여 해당 부분만 학습
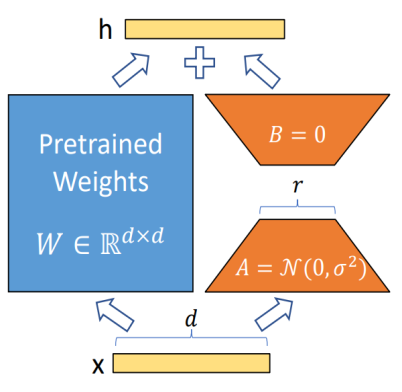
2.2 Low-Rank Adaptation(LoRA)
병렬적으로 처리하는 방식을 활용함.
3. AI Model Memory Optimization
3.1 Parallel Computation
모델을 여러 개의 GPU에로 분산.
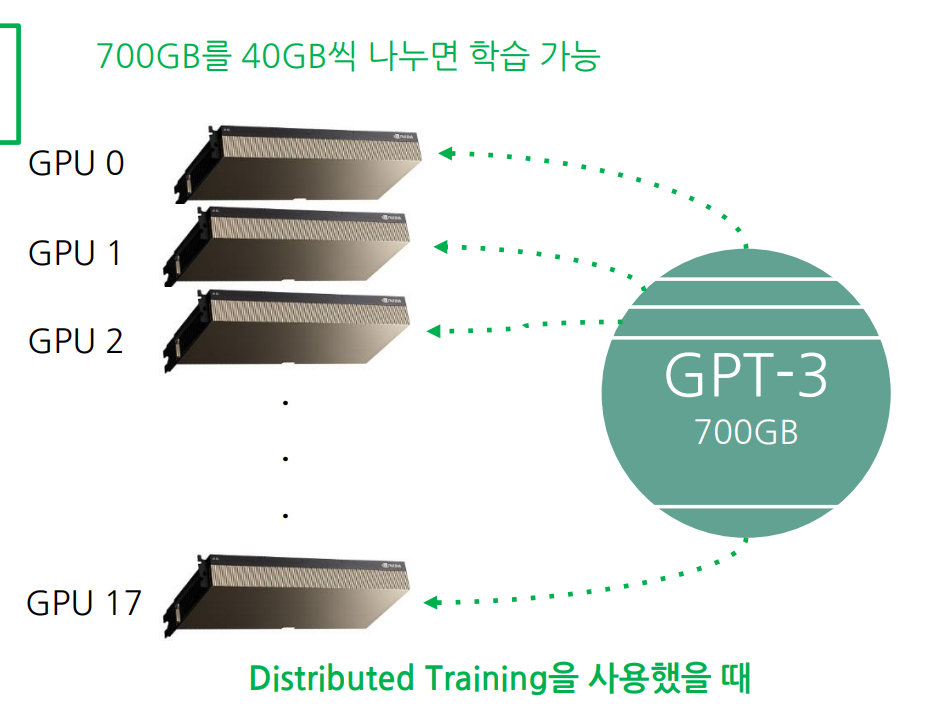
Distributed Training
여러 GPU간에 데이터를 분할하거나 모델 자체를 분할하여 여러 GPU에 걸쳐 훈련 프로세스를
병렬(Parallelism)화하는 학습 기법
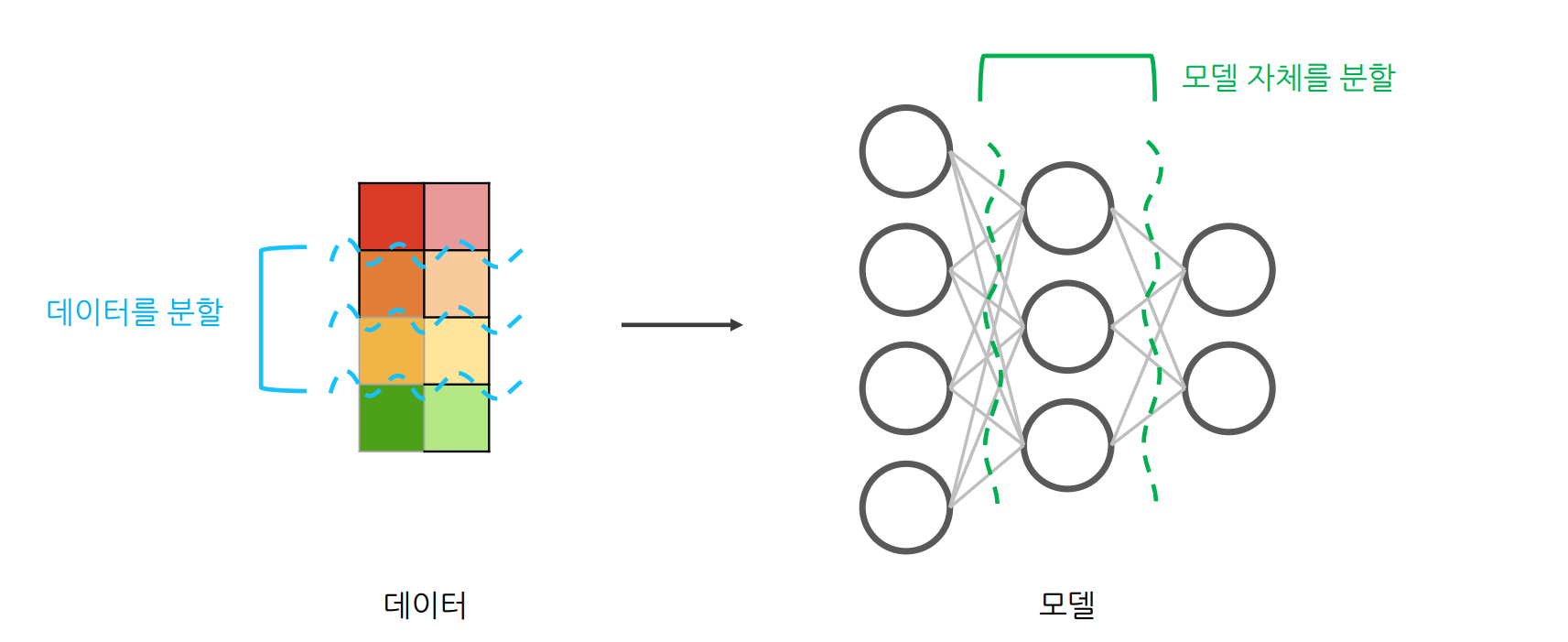
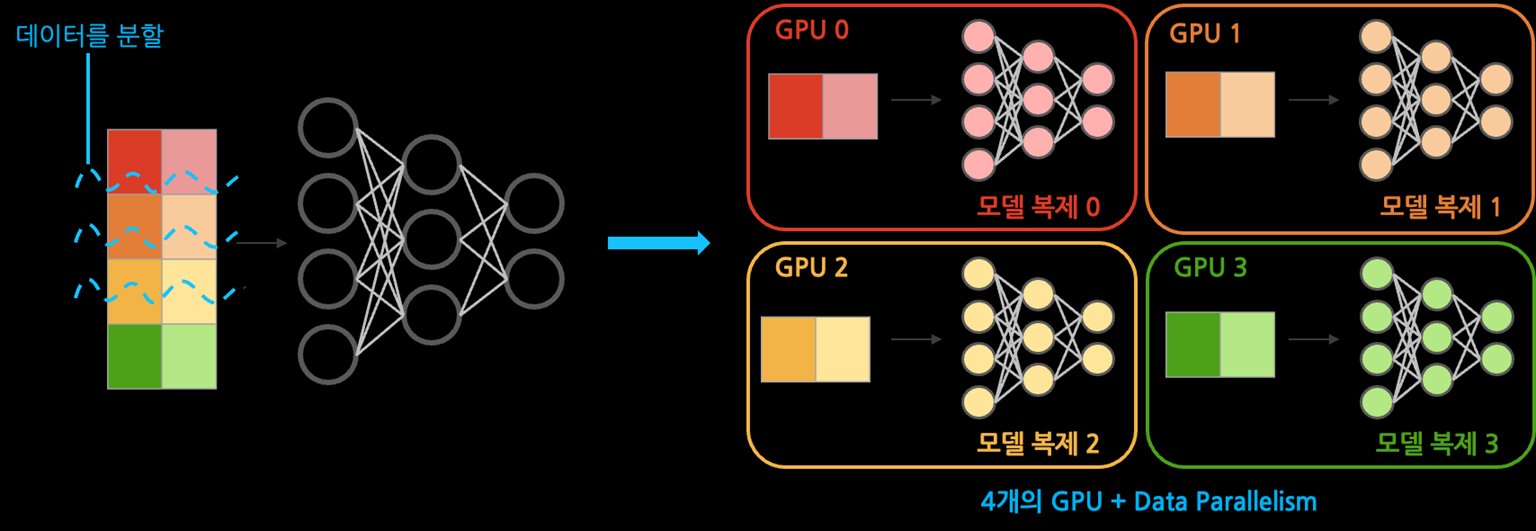
Data Parallelism
큰 데이터를 여러 GPU들에 분할하여 동시에 처리함으로써 학습 속도를 높임
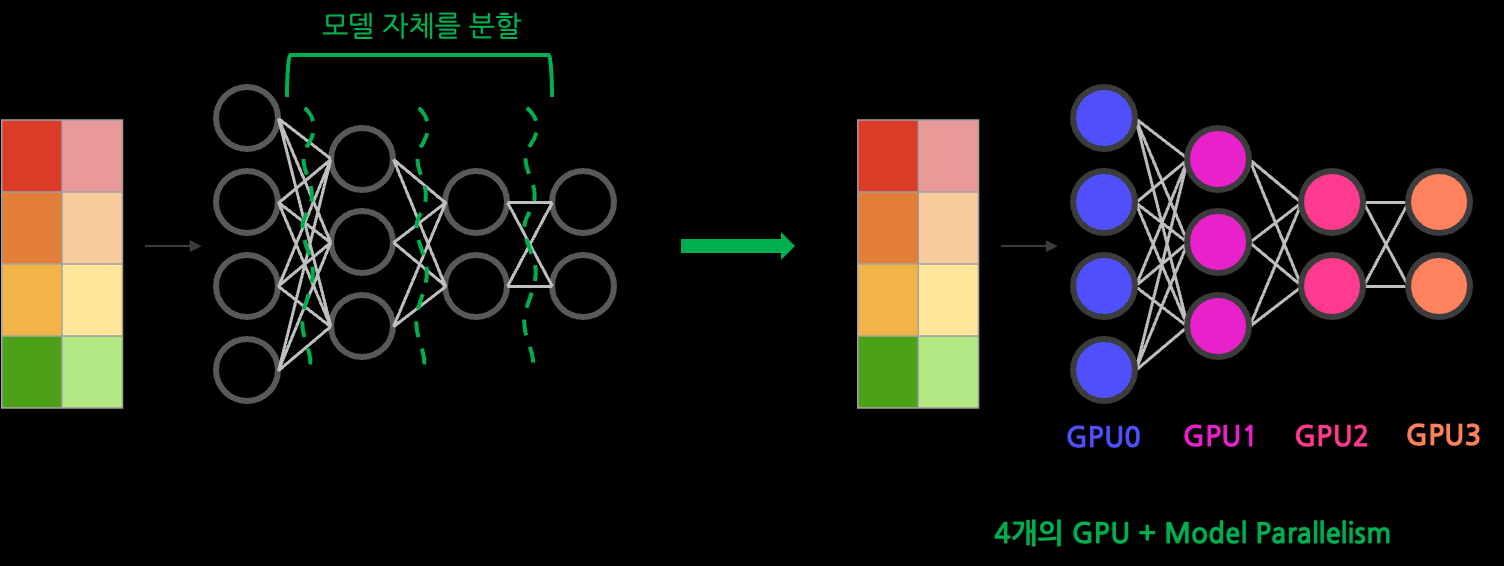
Model Parallelism
큰 모델을 여러 GPU들에 분할함으로써 하나의 GPU로는 처리할 수 없는 대형 모델도 처리 가능
4. 참고사항
Rethinking the Value of Network Pruning
https://arxiv.org/abs/1810.05270
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
https://arxiv.org/abs/1712.05877
