1. Advanced Concepts
1.1 Matrix Sparsity
희소(sparse)행렬: 행렬의 대부분의 요소가 0인 행렬
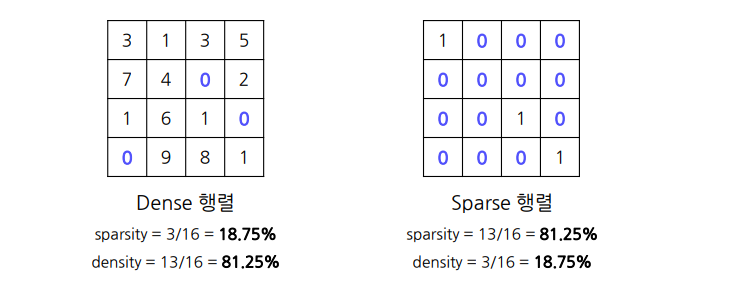
정확히 몇 퍼센트 이하면 희소하다 라는 개념은 아님.
아주 sparse 한 경우: Sparse Matrix Representation
메모리 효율
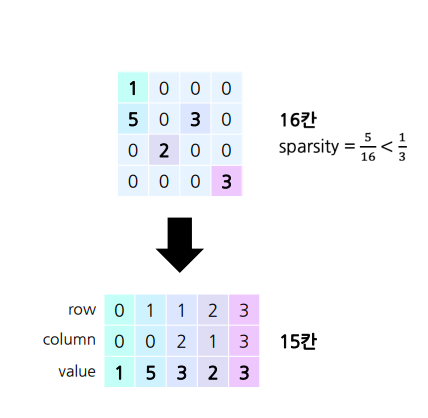
- 일반적인 n×m 행렬 필요 메모리 = nm
- sparse 행렬의 필요 메모리 = 최대 3k
- k는 0이 아닌 요소의 수
- sparsity = k/(nm) 이므로
- sparsity가 ⅓ 미만일때 더 효율적
- nm > 3k
- ⅓ > k/(nm)
연산 효율
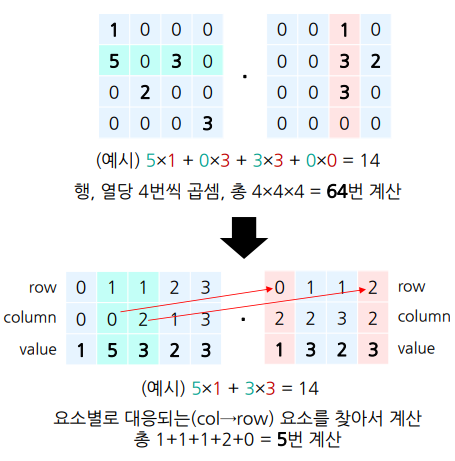
일반적인 n×m 행렬과 m×p 행렬의 행렬곱 계산량 = nmp에 비례
sparse 행렬이었을 경우 계산량
- = 최대 k₁p 혹은 k₂n에 비례
- 0이 아닌 요소 수가 각각 k₁, k₂
비슷하게, 충분히 sparse하면 훨씬 효율적
- k₁p < nmp, k₂n < nmp
- k₁/(nm) < 1, k₂/(mp) < 1
중간 정도로 sparse 한 경우: 전용 하드웨어 사용
중간 정도일 경우에는 전용 하드웨어 사용
• 곱셈 수행 전, 스캔을 통해 0의 위치를 파악(overhead 약간 발생)
• 해당 위치를 건너뛰고 계산되도록 조정
1.2 Sensitivity Analysis
Pruning Ratio
파라미터의 몇%를 제거 할 것인지 비율
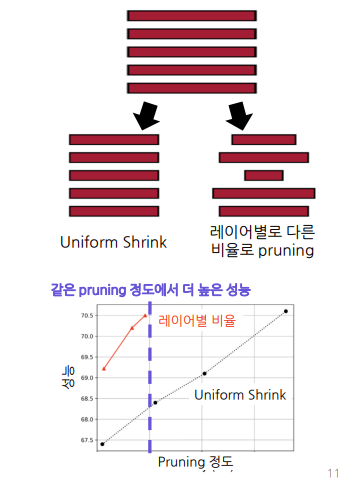
- Local: 레이어별로 동일하게 일정 비율을 제거
- 동일한 비율이라서 Uniform Shrink이라고도 함
-> 위 이미지의 성능을 보았을때 레이어별로 비율을 다르게 설정하는 것이 좋음.
네트워크가 복잡하거나 / 층별 특성이 상이한 모델의 경우
각 레이어의 특성을 반영
- 민감도가 높은 부분은 덜 pruning
- 낮은 부분은 더 pruning
각 레이어의 pruning 비율을 설정하는 중요도를 측정하는 방법
실험을 통해 측정하는 empirical하고 practical한 방법
Sensitivity 측정: 파라미터/레이어의 민감도: 해당 파라미터/레이어를 pruning 했을 때의 성능 저하 정도 측정
sentivity 성능 비교
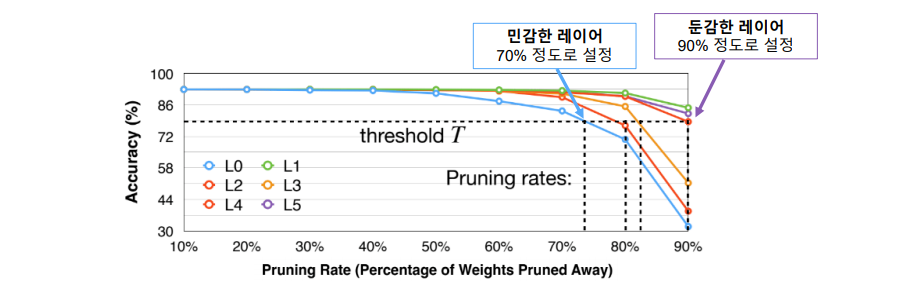
레이어 별로, 비율 별로 각각 측정
측정 한번에 pruning 전체 과정 1번 만큼의 iteration 소요.
2. Pruning in Practice
2.1 Pruning in CNNs
where to Prune?
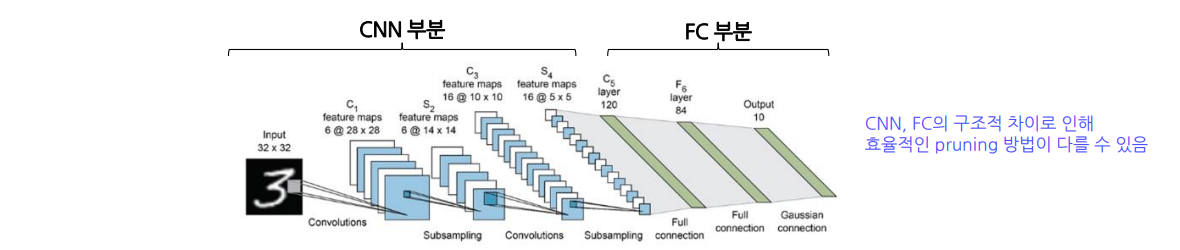
보통의 CNN모델은 CNN부분과 FC부분으로 나누어짐
대부분의 파라미터는 FN부분
그러나 연산 속도의 bottleneck은 CNN부분
-> 따라서 공간/시간 효율을 모두 챙기려면 각각 pruning이 필요함
Filter Pruning

이 중 중요도가 작은 filter를 제거하는 것이 CNN의 pruning
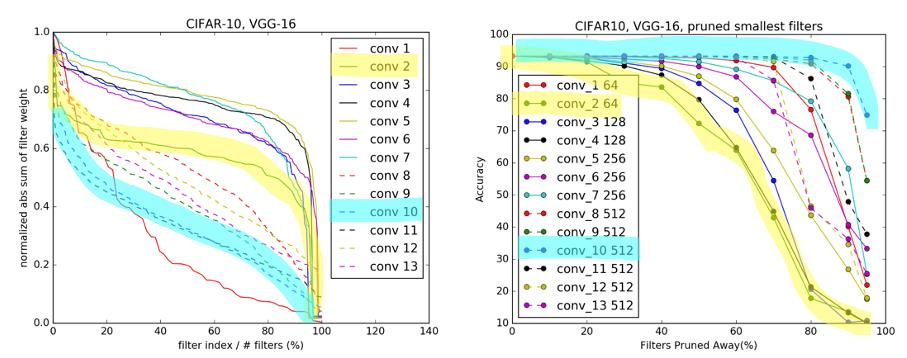
Sparse한 filter의 비율이 높은 레이어는 pruning을 많이 해도 성능 저하가 덜함. 파란색으로 칠한 곳을 잘 살펴보면 pruning 비율이 높음에도 불구하고 성능저하가 적음을 알 수 있다.
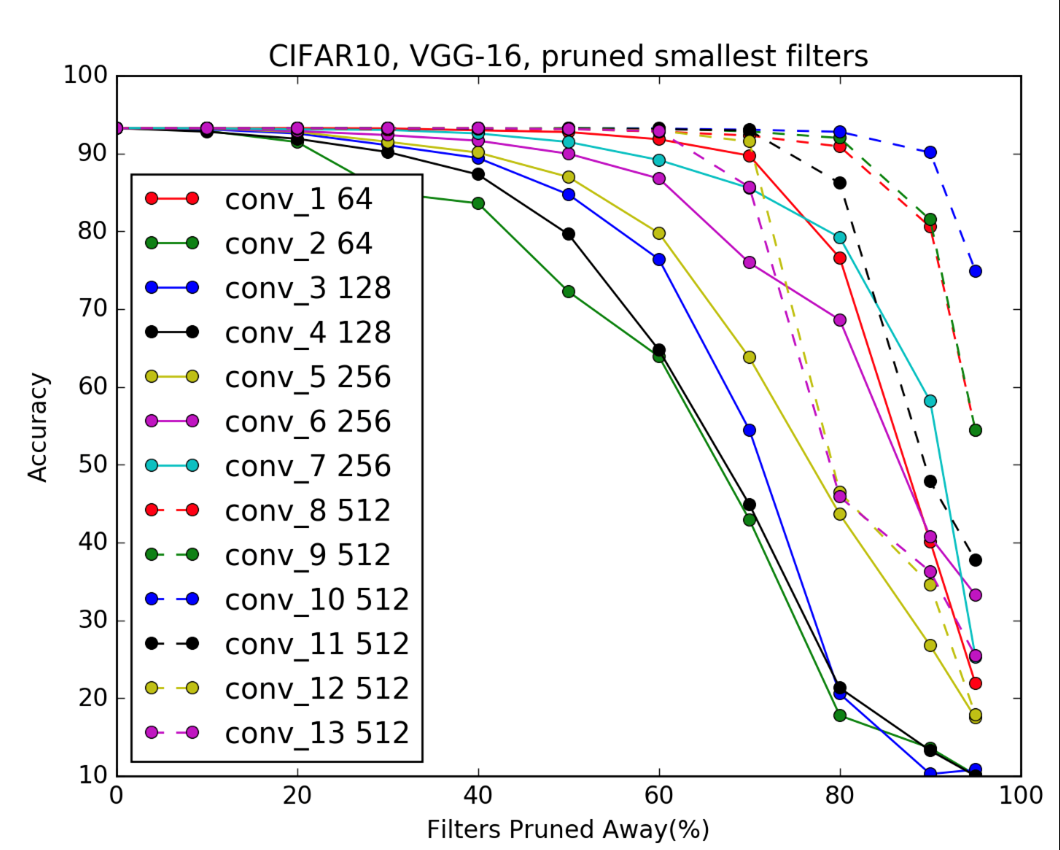
Sensitivity analysis에 따르면
- 뒤쪽 레이어가 덜 민감함 (점선들)
- 일부 레이어는 90%씩 삭제해도 문제 없음(큰 형태는 다양성이 비교적 적기 때문)
- 반면, 앞쪽 레이어는 너무 많이 제거하면 모델이
이미지를 파악 할 수 없음( 작은 형태는 다양성이 크기 때문)
👉 따라서 CNN을 pruning 할 때엔 전체 제거 비율을 레이어 별로 나눠서 분배해야함
CNN Pruning Summary
CNN 파트, FC 나눠서 진행
Structure
• Structured Pruning
• 레이어 별 filter 단위로 prune
Scoring
• Filter의 sparsity를 중요도로 사용
• Practical 하게는 L2-norm
• 레이어 별로 비율을 다르게 설정
2.2 Pruning in BERT
BERT: Bidirectional Encoder Representations from Transformer
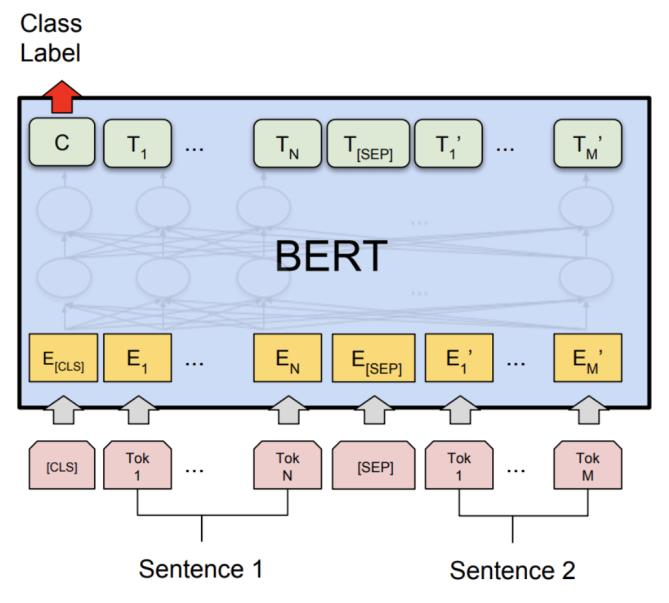
Layers of BERT
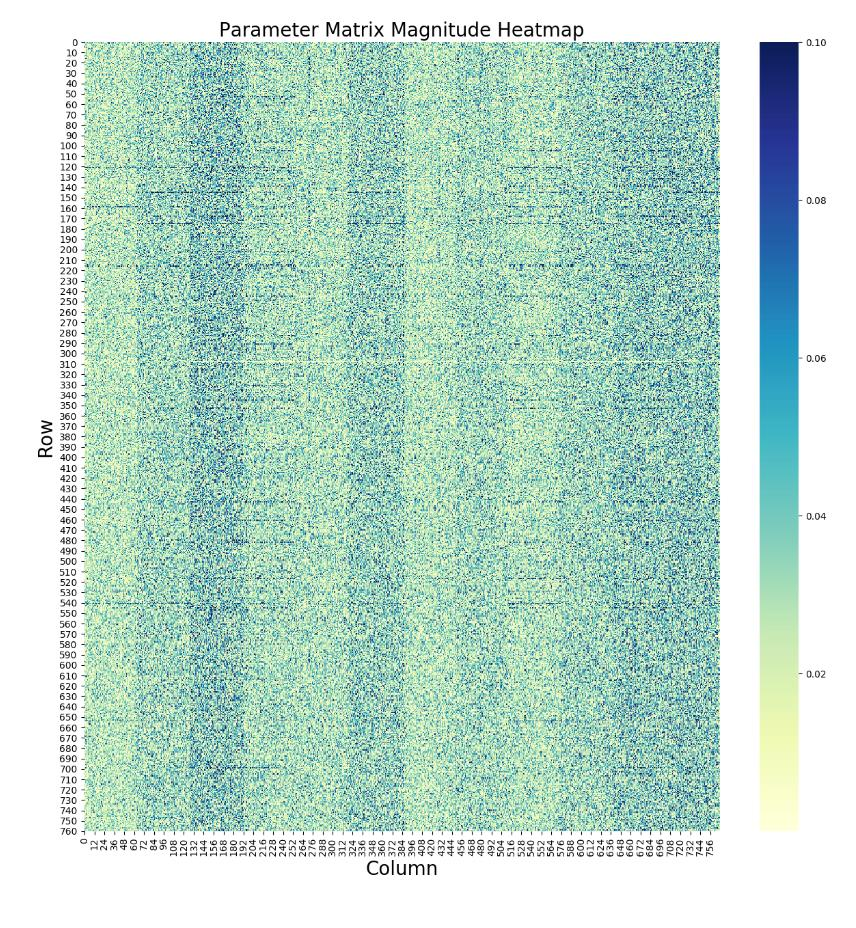
언어 모델 보통 앞쪽 레이어는 작은 형태(단어) 뒤쪽 레이어는 큰 형태(문장 등) -> 그러나 레이별 sparsity가 비일관적임
-> 따라서 global pruning 은 부적절하고 structured pruning도 위험함.
그렇기 때문에 local + 절대값 기준 pruning이 적절할 것으로 보임.
First Layer
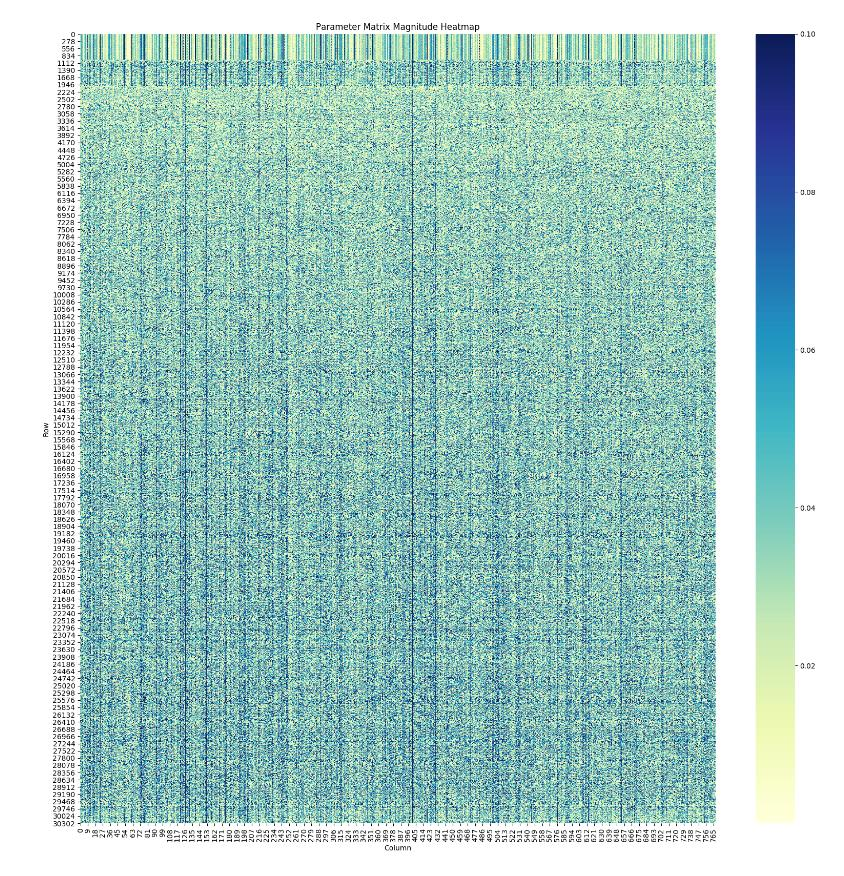
단어의 모음인 vocabulary, 이 vocabulary가 첫번째 레이어를 담당.
짧은 단어일수록 벡터가 더 sparse함 따라서,Local Pruning을 하면, 짧은 단어 위주로 pruning을 하기 때문에 유효
Pruning Result

3. PyTorch Example
3.1 Sample Code
깃헙 추가.
