1. Transfer Learning
1.1 Transfer Learning
Transfer Learning (전이학습)이란, 이미 학습이 완료된 모델을 새로운 작업의 시작점으로 모델을 재사용하는 기계학습 방법론
-> 특정 데이터셋을 이용해서 사전 학습된 모델의 가중치를 업데이트하는 것이 처음부터 훈련시키는것보다 빠르고 쉬움

ex) 기타를 처음부터 배우는 애보다, 피아노를 칠 줄 아는 애가 기타도 배우기 더 수월함.
1.2 Pre/Fine
Pre-training: 방대한 양의 데이터를 활용한 모델 사전 학습
Fine-tuning: 새로운 작업을 위한 특정 데이터로 모델 재학습
ex1) NLP: BERT를 QA 데이터로 재학습
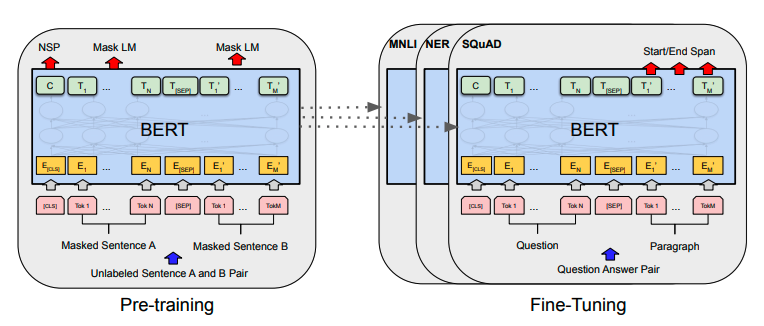
ex2) ImageNet 학습 모델 Medical 도메인 데이터로 재학습

Fine-tuning (미세조정)
- 보통 사전 학습 모델은 특정 작업에 특화된 모델이 아니라 문제 해결능력 부재.
👉 미세조정(Fine-tuning)은 모델이 새로운 작업에서의 문제 해결 능력을 얻기 위해 새로운 데이터로 사전학습 모델을 재학습 하는 과정을 지칭
이는 큰 모델일수록 학습 비용이 기하급수적으로 증가하는 문제점을 가지고 있음.
따라서 큰 모델이라고 하더라도 학습비용이 적게 들면서 finetuning 하는 방법이 PEFT!
2. PEFT(Parameter-Efficient Fine-Tuning)
2.1 PEFT
PEFT: 모델의 전체 parameter를 학습하는 FT과 다르게 필요한 일부분을 학습하도록 하는 방법
학습 파라미터, 학습 소요시간을 줄이는 효율적인 방법.
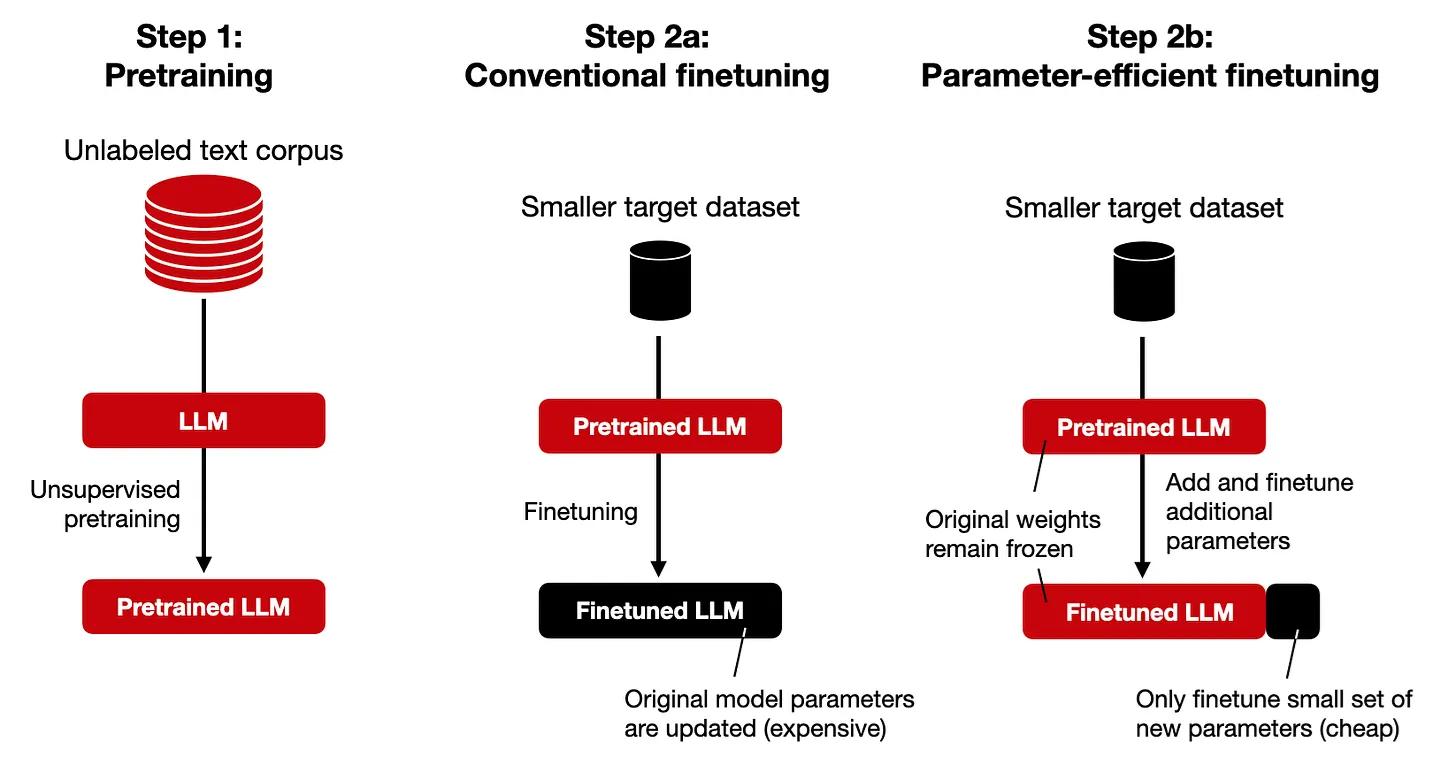
PEFT 방법론
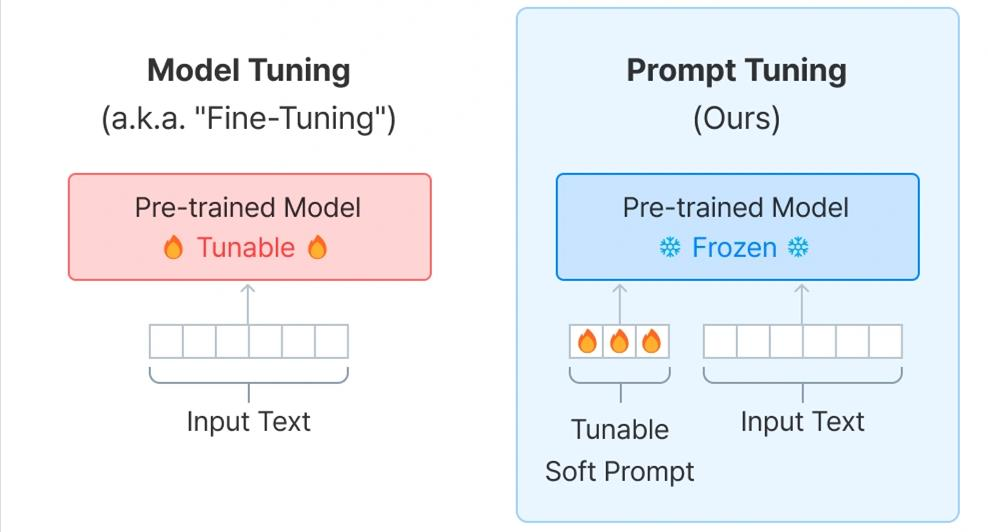
프롬프트 튜닝방식
프롬프트 튜닝은 모델의 원래 파라미터를 변경하지 않고도 모델의 출력을 원하는 방향으로 유도하는 방식
파라미터 삽입방식
모델의 특정 위치에 추가적인 학습 가능한 파라미터를 삽입하여 모델을 미세 조정
우리는 파라미터 삽입방식 두가지(Adapter와 LoRA에 대해서 배울 것)
Why PEFT?
대형 모델 파인튜닝의 어려움
-> 거대한 파라미터 수의 모델을 한정된 GPU 자원으로도 학습을 가능하게 함

모듈화를 통한 높은 활용도
-> PEFT는 서로 다른 작업에 대해 별도의 파라미터 세트를 유지하여 재사용 가능
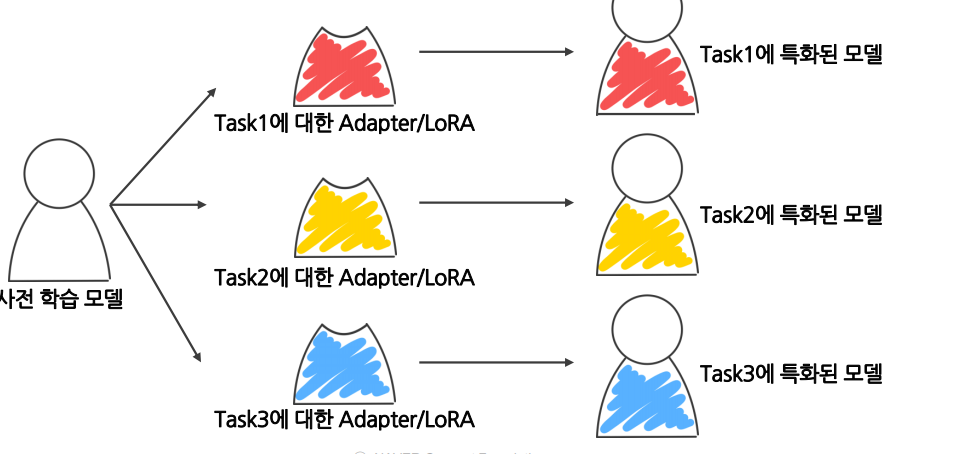
2.2 Adapter
https://arxiv.org/pdf/1902.00751
(1). 개념 요약
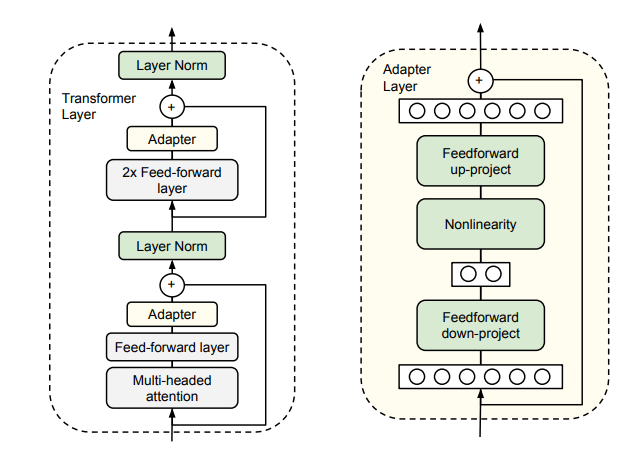
- Adapter는 기존 사전학습(Pretrained) 모델의 레이어 사이에 삽입하여, 극도로 적은 파라미터로도 성능을 유지/개선할 수 있는 모듈
- 원 논문에서는 BERT 레이어 사이에
Adapter 모듈을 끼워 넣는 구조 제안
→ Fine-tuning 대비 약 3.6%의 파라미터만 사용해도 유사한 성능 달성
(2). Bottleneck 구조
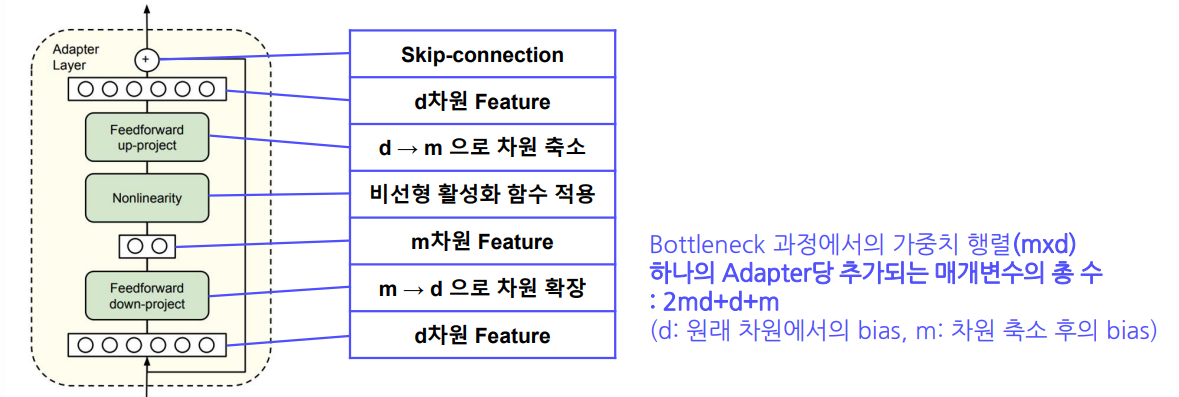
- Adapter 모듈은 Feedforward 단계를 두 번 거치며, 사이에 Nonlinearity를 적용하는 Bottleneck 구조
- Down-projection: 입력 차원(
m) → 저차원(r)으로 축소 - Up-projection: 다시 저차원(
r) → 원래 차원(m)으로 확장
- Down-projection: 입력 차원(
- 이렇게 차원을 축소했다가 복원하는 과정을 통해 학습 파라미터 수를 대폭 감소시킬 수 있음
예시
-
입력 feature가 6차원이라고 가정
- 6 → 2 (down)
- (비선형성)
- 2 → 6 (up)
-
여기서
r=2와 같이 작은 수를 고정하면, 파라미터 수도 이에 비례해 감소
(3). Skip-connection
- Bottleneck 구조로 인해, 입력 정보가 압축/복원되는 과정에서 손실이 발생할 수 있음
- 이를 보완하기 위해 Skip-connection(잔차 연결)을 추가:
- Down/up-projection 후 최종 결과에 입력(
x)을 다시 더해 줌 - 이렇게 하면 표현력과 안정성이 향상됨
- Down/up-projection 후 최종 결과에 입력(
(4). Reparameterization Trick
- Adapter 내부에서 FNN의 가중치(Weight)
W를 두 개의 작은 행렬로 분해하여 파라미터를 줄이는 방식- 예)
- ,
- 입력 (크기: ) → → → →
- 이렇게
m→r→m과정을 거치면 실제로 학습해야 할 파라미터가m*r + r*m로 줄어듦
- 예)
(5). Adapter 구조 정리
- Bottleneck:
Down-projection+Nonlinearity+Up-projectionr(bottleneck 차원) 크기에 따라 파라미터 수 직접 조절 가능
- Skip-connection:
- Bottleneck 출력에 입력을 다시 더해주는 구조
- 결과:
- 학습해야 할 파라미터 수를 제한하면서도 성능 유지를 위한 표현력 확보
- 기존 모델 대비 적은 양의 파라미터로도 충분한 미세조정이 가능
• Adapter module은 Bottleneck과 Skip-connection으로 구성
2.3 LoRA(Low-Rank Adaptation of Large Language Models)
https://arxiv.org/abs/2106.09685
LoRA(Low-Rank Adaptation)는 대규모 사전학습된 모델(Pretrained Model)에서 추가적인 파라미터를 매우 적은 양으로 삽입하여, 모델 전체를 재학습하지 않고도 특정 태스크에 맞춰 효율적인 파인튜닝을 진행할 수 있게 해주는 방법
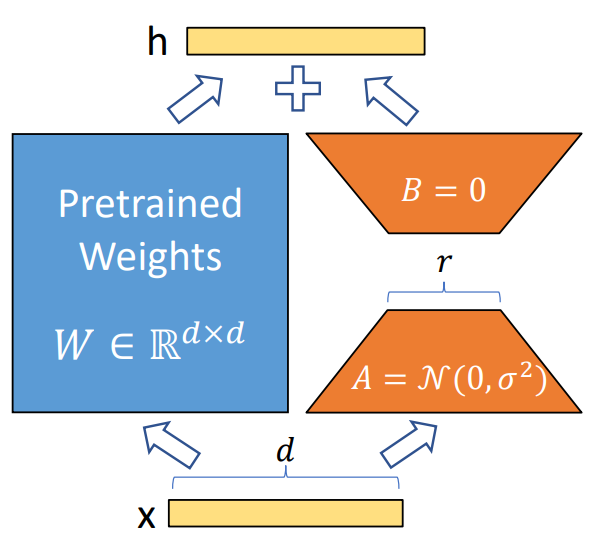
(이때 은 랭크 크기의 행렬 를 평균0 분산 으로 정규분포로 초기화한다는 뜻. -> 학습전 초기값A를 무작위로 뽑아 세팅
반면에 은 랭크 크기의 또 다른 행렬 B를 처음에는 전부 0으로 두고 시작 )
사전 학습 모델 가중치는 고정한 채로, 트랜스포머 아키텍처의 각 층에 랭크 분해 행렬을 병렬적으로 위치시켜 추가적인 추론의 지연이 발생하지 않음
- 비선형 함수를 사용하지 않음
- Bias 파라미터를 학습하지 않음
(1) 기본개념
- 저랭크(저차원) 분해 기법을 이용해, 기존 모델의 가중치 에 대한 저차원 보정(Delta Weight) 를 학습.
- 즉, 형태로 분해하여 파라미터 수를 줄임.
- 추가 파라미터: 와 두 행렬에 한정 (랭크 크기의 작은 행렬).
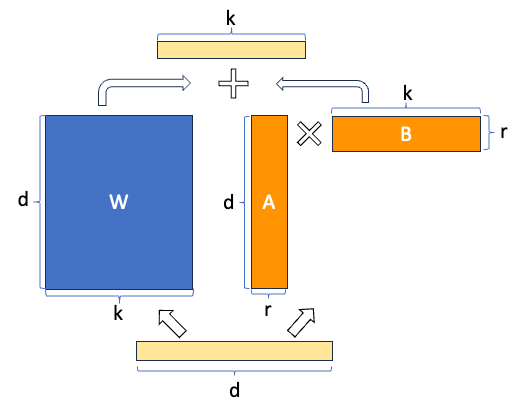
(2) 수식으로 보는 LoRA
LoRA에서는 기존 가중치 와 추가 학습 가중치 를 더해 최종적으로 아래와 같이 계산합니다:
- 는 입력 벡터, 는 출력 벡터.
- 여기서 는 임베딩 차원, 는 입력 혹은 출력 차원, 은 LoRA에서 설정하는 랭크(작은 값).
(3) Adapter와 비교
- Adapter 모듈은 보통 Sequential한 구조로, 예:
- 비선형 활성함수 와 바이어스 항이 추가된 형태로, 다소 복잡한 구조.
(4) LoRA
- LoRA 모듈은 Adapter와 유사하게 Reparameterization Trick을 활용하지만, 병렬(Parallel) 구조로 계산됨.
- 기본적으로 이미 비선형 모델(Transformers 등)에 부가로 붙기 때문에, 추가적인 활성함수 나 바이어스 항을 두지 않고도 충분한 표현력을 얻을 수 있음.
- 를 형태로 구성하고, 이 두 행렬에만 학습을 집중하여 파라미터 수를 크게 절약.
(5) LoRA의 장점
- 매우 적은 파라미터 증가
- 랭크 (r)을 적절히 설정해주면, Adapter에 비해 훨씬 적은 수의 파라미터로도 모델 성능을 확보가능
- 병렬 계산 구조
- Adapter처럼 순차적으로 추가 계산(비선형 변환 등)을 하지 않고, 기존 가중치 계산과 동시에 병렬 형태로 계산
- 결과적으로 추가 연산 비용이 작고, 인퍼런스 속도 면에서도 이점
- 기존 가중치를 수정하지 않음
- 는 그대로 두고 만 학습하므로, 원본 모델을 그대로 유지하면서 확장할 수 있음.
(6). 전체 프로세스 정리
-
기존 사전학습 모델(Pretrained Weights, ) 고정
-
모듈을 삽입**
- 랭크 을 설정 (예: 4, 8, 16 등)
- , 인 행렬을 초기화
-
LoRA 모듈만을 학습
- 추가되는 파라미터: (편의상 라고 하면)
- 전체 파라미터 양이 작으므로 메모리 및 학습 비용이 대폭 감소
-
인퍼런스 시
- 형태로 사용
- 추론 과정에서의 연산량 증가도 최소화.
(6). 결론 및 요약
- LoRA는 저랭크 분해 기법을 활용해 적은 파라미터로도 기존 모델을 커스터마이징할 수 있는 효율적인 파인튜닝 방법
- Adapter 대비 병렬 구조로 더 단순하고 빠른 인퍼런스를 제공하며, 기존 모델의 파라미터를 그대로 보존하므로 모델 유지보수에 유리
- 추가되는 파라미터가 적다는 점에서 메모리 사용량, 학습 비용, 추론 비용이 절감되는 효과가 큼.
✅ LoRA의 핵심 아이디어
- 기존 모델의 가중치(W)는 고정해 둔 채,
- 작은 크기의 행렬 를 추가로 학습해서 업데이트해야 할 가중치(ΔW)를 근사하는 방식.
- 즉, 로 표현되는 저차원 보정 행렬만 학습.
🔷 LoRA가 작동하는 방식 (단계별로)
1️⃣ 기존 모델의 가중치 는 그대로 둠
- 원래 Transformer 모델의 W 행렬을 직접 수정하지 않음.
2️⃣ LoRA 모듈(저차원 행렬) 삽입
- 작은 랭크(rank) 을 설정. (예: 4, 8, 16 같은 작은 값)
- 두 개의 작은 행렬 , 를 추가.
3️⃣ LoRA 모듈만 학습
- 만 학습하고, 기존 는 업데이트하지 않음.
- 이렇게 하면 전체 가중치를 업데이트할 필요 없이 적은 파라미터로도 모델을 Fine-tuning 가능.
4️⃣ 인퍼런스 시에는 사용
- 즉, 기존 가중치 + LoRA 보정값을 더해서 최종 결과를 냄.
- 병렬 계산이 가능해서 추론 속도도 빠름! 🚀
3. Adapter vs LoRA
3.1 Adapter vs LoRA

🔷 LoRA vs Adapter 차이점
| LoRA | Adapter | |
|---|---|---|
| 학습 구조 | 기존 가중치 고정 + 저차원 보정 행렬(병렬) | 추가적인 MLP 모듈 삽입(순차적) |
| 비선형성 | ❌ 없음 (Linear) | ✅ 있음 (활성함수 사용) |
| 추가 파라미터 | 아주 적음 (O(2dr)) | LoRA보다 많음 |
| 추론 속도 | 빠름 (병렬 구조) | 비교적 느림 (추가 레이어 계산) |
| 저장 공간 | 적음 (작은 행렬만 저장) | 비교적 많음 |
4. 참고사항
Parameter-Efficient Transfer Learning for NLP
https://arxiv.org/pdf/1902.00751
Prompt tuning & Prefix tuning (parameter tuning말고 다른 tuning 기법도 참고
PyTorch: Transfer Learning for Computer Vision Tutorial
https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
