1. Applying LoRA
1.1 Applying LoRA
# -------------------------------------------------------------------
# 1. 라이브러리 임포트
# -------------------------------------------------------------------
!pip install transformers datasets accelerate peft # 필요하면 설치
import torch
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, TrainingArguments, Trainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_model
# -------------------------------------------------------------------
# 2. 하이퍼파라미터 설정
# -------------------------------------------------------------------
LEARNING_RATE = 5e-5
BATCH_SIZE = 4 # 메모리에 따라 조정
EPOCHS = 3
rank_size = 2 # LoRA의 랭크 (colab 등에서는 1~4 정도가 적당)
# -------------------------------------------------------------------
# 3. 데이터셋 불러오기 (예시: SQuAD 형태 가정)
# 예시로 데이터 일부만 사용
# -------------------------------------------------------------------
dataset = load_dataset('squad') # 'train', 'validation' 내장
train_data = dataset['train'].select(range(0, 400))
val_data = dataset['validation'].select(range(0, 20))
# (참고) 실제로는 아래처럼 본인 데이터셋을 불러올 수도 있음:
# dataset = load_dataset('json', data_files={'train': 'train.json', 'validation': 'val.json'})
# train_data = dataset['train']
# val_data = dataset['validation']
# -------------------------------------------------------------------
# 4. 모델/토크나이저 로드
# -------------------------------------------------------------------
model_name = "bert-base-uncased" # 예시
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
# -------------------------------------------------------------------
# 5. 기존 모델 가중치 'freeze' (학습 불가 상태로)
# -> LoRA 모듈만 학습
# -------------------------------------------------------------------
for param in model.parameters():
param.requires_grad = False
# -------------------------------------------------------------------
# 6. LoRA 설정
# -------------------------------------------------------------------
lora_config = LoraConfig(
r=rank_size, # LoRA에서 사용될 rank
lora_alpha=16, # LoRA scaling (논문에서 주로 16 사용)
target_modules=["query", "value"], # 예: Transformer 내부 query/value 모듈에만 LoRA 적용
lora_dropout=0.1 # 과적합 방지를 위한 dropout
)
# LoRA를 적용한 모델 생성
model_with_lora = get_peft_model(model, lora_config)
# -------------------------------------------------------------------
# 7. 데이터 전처리 함수 예시 (질문+문맥 → 모델 입력)
# -------------------------------------------------------------------
def preprocess_function(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=384,
truncation=True,
padding="max_length"
)
# 여기서는 간단히 label 구간 생략 (정답 위치 태깅 등),
# 실제로는 start_positions, end_positions를 함께 계산해줘야 함
return inputs
# 실제 파인튜닝에 사용할 Dataset 객체 준비
train_dataset = train_data.map(preprocess_function, batched=True)
val_dataset = val_data.map(preprocess_function, batched=True)
# Trainer에 들어갈 feature 지정
train_dataset.set_format(type="torch", columns=list(train_dataset.features.keys()))
val_dataset.set_format(type="torch", columns=list(val_dataset.features.keys()))
# -------------------------------------------------------------------
# 8. TrainingArguments & Trainer 설정
# -------------------------------------------------------------------
training_args = TrainingArguments(
output_dir="./outputs",
evaluation_strategy="steps",
eval_steps=50,
save_steps=50,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
logging_steps=10,
remove_unused_columns=False
)
trainer = Trainer(
model=model_with_lora,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset
# compute_metrics=... (QA 스코어 계산 함수 등)
)
# -------------------------------------------------------------------
# 9. 학습 진행
# -------------------------------------------------------------------
trainer.train()
# -------------------------------------------------------------------
# 10. 추론 및 평가 예시
# -------------------------------------------------------------------
# 간단히 val_dataset 샘플을 뽑아 예측해보기
test_sample = val_dataset[0]
input_ids = torch.tensor([test_sample["input_ids"]])
attention_mask = torch.tensor([test_sample["attention_mask"]])
with torch.no_grad():
outputs = model_with_lora(input_ids, attention_mask=attention_mask)
# 예) start_logits, end_logits로부터 정답 토큰 구간 추출 후
# tokenizer.decode()로 실제 문자열 복원
# ...
print("Done!")
2. Advanced PEFT
2.1 AdapterFusion
https://arxiv.org/abs/2005.00247
motivation: Adapter를 결합하여 여러 task를 해결하는 모델을 만들자
Adapter의 모듈화: Pre-trained model의 parameter를 공유한다는 점에서 Adapter만 바꾸면 특정 task에 대한 빠른 전환이 가능→ 전환 없이 Adapter를 결합하여 모델이 task를 선택하여 수행
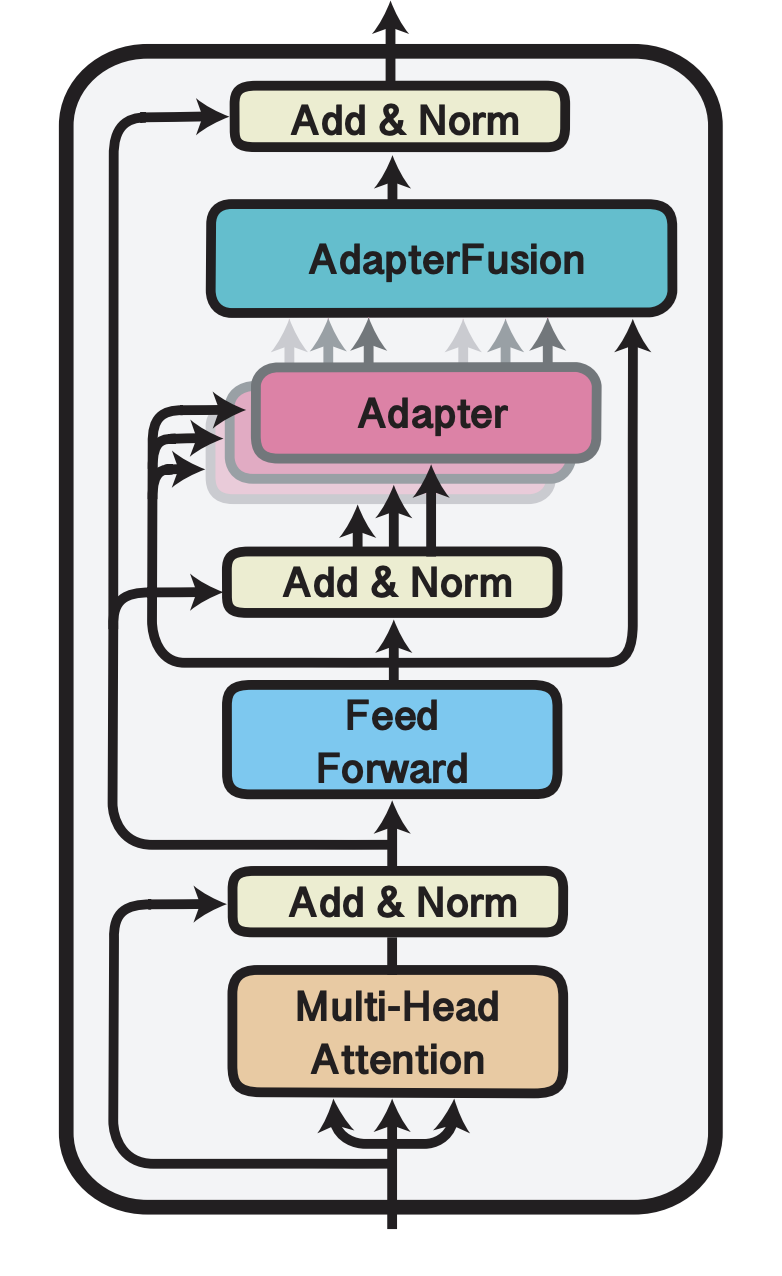
2-Stages algorithm
(1). Knowledge extraction: Specific task에 대한 Adapter parameter를 학습
: N개의 specific task에 대한 N개의 Adapter parameter를 개별적으로 학습
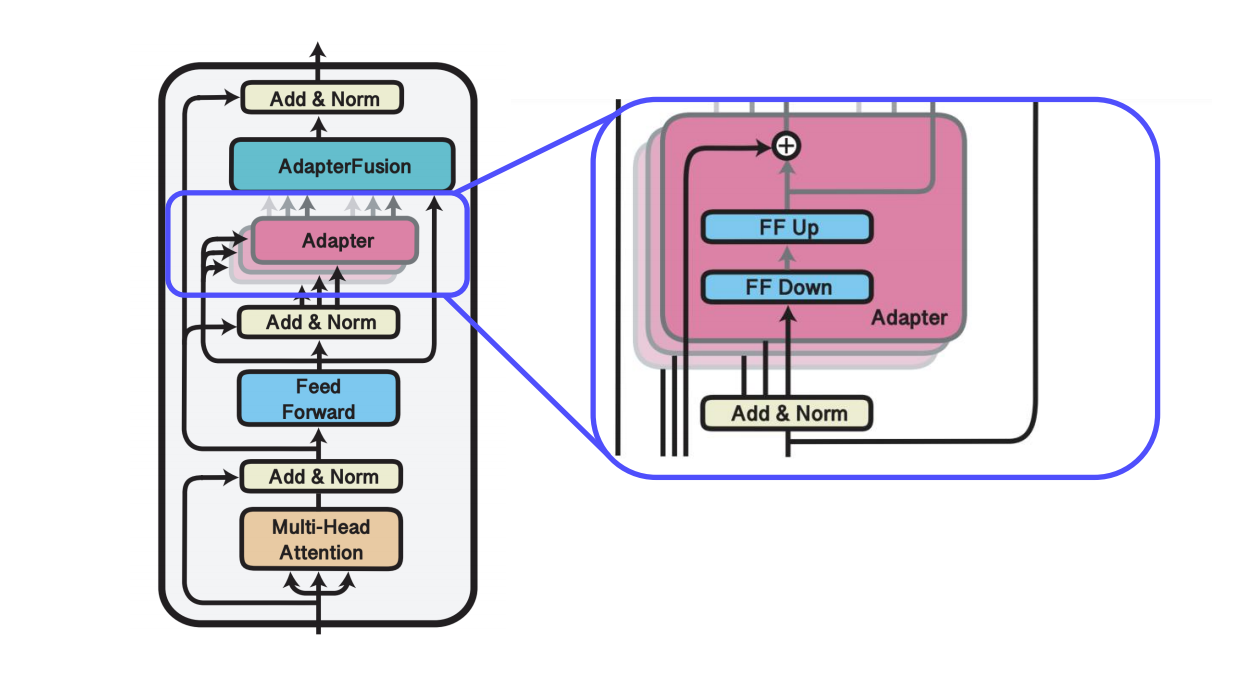
(2). Knowledge composition: Adapter를 결합하는 단계(입력에 따른 적절한 Adapter 결과를 선택해서 합치는 모듈 (Adapter의 가중합)
[Knowledge Composition 단계에선 사용자의 입력에 따라 가장 적합한 Adapter의 가중치를 측정하는 Attention 모듈만 재학습한다. 이 과정에서 이미 학습된 Adapter 및 모델의 파라미터는 고정한다.
해당 과정을 통해 학습된 Attention 모듈은 입력에 따라 각 Adapter의 중요도나 적합성을 측정하는 역할을 하고, 이를 통해 어떤 Adapter가 현재 사용자의 입력에 가장 적합한지를 판단하여 가중치를 계산한다]
...1) 병렬 Adapter 연산: 각 Adapter 값의 출력을 구하는 과정
- 전 단계에서 학습된 여러개의 Adapter를 병렬적으로 위치 시킴.
- 병렬적으로 각 Adapter 값의 출력 값을 구함
출력값: N개의 Adapter 의 각 출력값
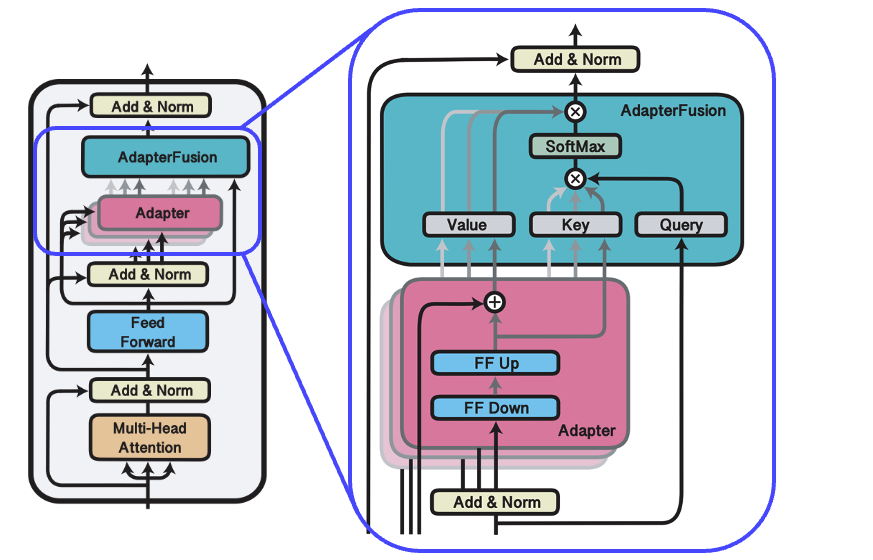
...2) Adapter-Attention: 각 Adapter 출력을 취합하여 최적의 출력 생성
- 사용자 입력에 맞는 Adapter의 가중치를 측정하는 Attention 모듈만 재학습
- 학습 시 이미 학습된 Adapter 및 모델의 파라미터는 고정
- Query: 사용자 입력의 Hidden state
- Value: 각 Adapter의 출력
- Key: 각 Adapter의 Key
출력값: 각 Adapter 출력의 가중합(weighted sum) 출력
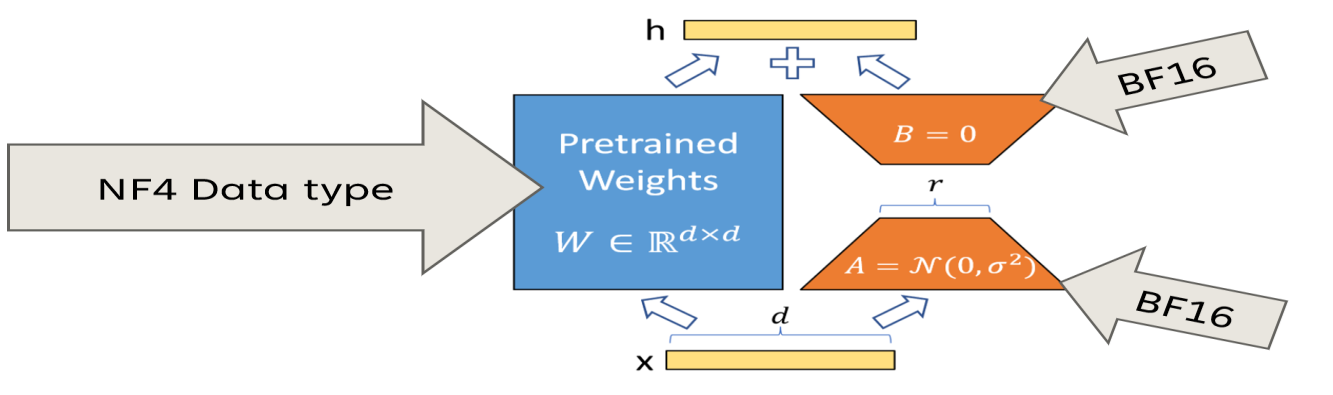
2.2 QLoRA(Efficient Fine Tuning of Quantized LLMs)
https://arxiv.org/abs/2305.14314
(1). 개요
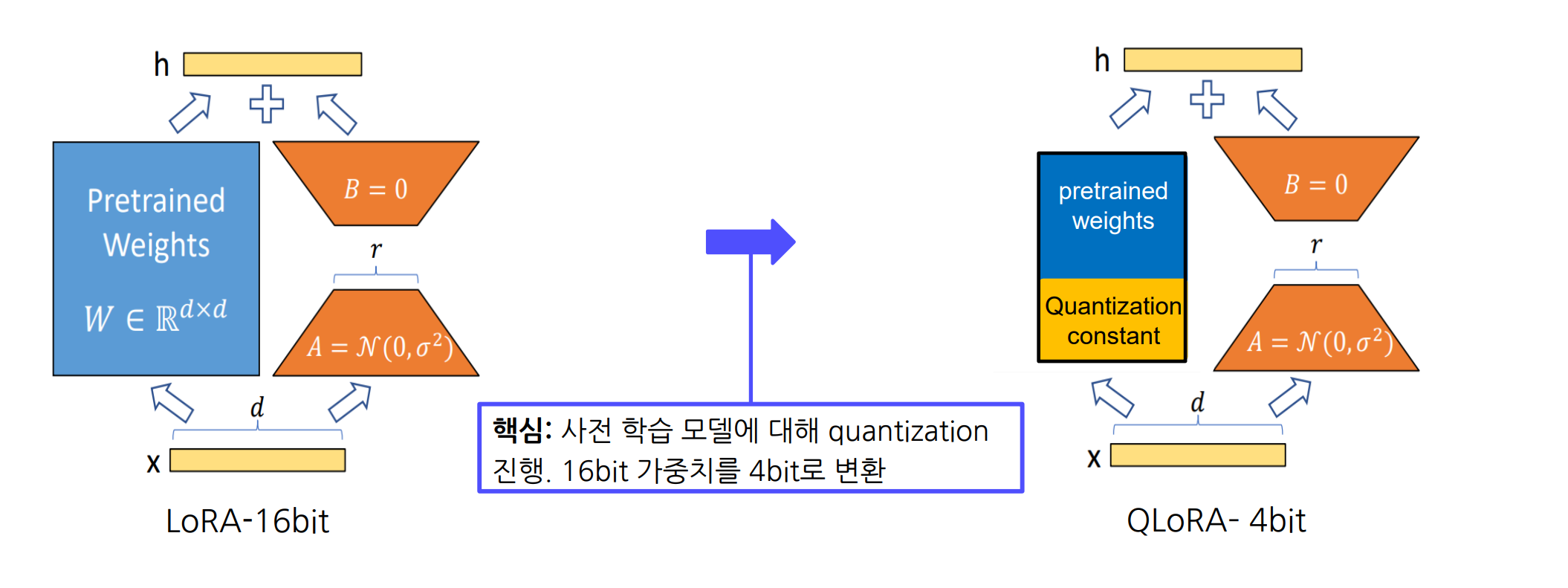
- QLoRA (Quantized LoRA): 미세조정(파인 튜닝) 시 메모리 사용량을 획기적으로 줄이기 위해, 사전 학습 모델의 가중치(16비트)를 4비트로 양자화(quantization)하고, 추가로 양자화 상수까지 2중 양자화(double quantization)하여 저장하는 기법
(2). 특징
- 4-bit Normal Float(NF4): 가중치를 4bit로 양자화하여 메모리 사용량을 줄인다.
- Double Quantization: 양자화 상수 자체를 추가적으로 양자화하여 메모리 절감 효과를 제공한다.
(tensor의 대부분의 값은 0이므로 0을 표현하지 못하게되면 정보의 손실이 커진다. 이를 방지하기 위해 4-bit Normal Float 양자화는 비대칭적인 표현을 유지하며 이는 0을 정확하게 표현하기 위함이다.)
2.1 4-bit Normal-Float Quantization
- 사전 학습 모델의 16비트 가중치를 4비트로 압축
- 양자화 시 양자화 상수(quantization constant)가 발생
- 4비트로 변환하여 메모리 사용량 대폭 절감
2.2 Double Quantization
- 4비트 양자화 후 생성되는 양자화 상수에 대해서도 추가로 양자화(2중 양자화)를 적용
- 양자화 상수를 높은 precision(예: 16비트 등)으로 저장하면 메모리 오버헤드가 증가
- 다시 한 번 양자화해 추가 메모리 사용량을 조금 더 절감
(3). 메모리 요구 사항
- 예) LLaMA 70B 모델 파인 튜닝 시
- 16비트 LoRA: 약 160GB
- 4비트 QLoRA: 약 48GB
- Double Quantization을 통해 양자화 상수 또한 줄이므로 추가 메모리 절감 효과
(4). 요약
QLoRA는 사전 학습 모델의 가중치를 4비트로 변환하고, 이때 발생하는 양자화 상수 역시 다시 양자화함으로써 메모리 사용량을 최적화하는 기법!! 비록 양자화 상수를 2중 양자화함으로써 절약되는 부분이 전체 대비 크지는 않지만, 대용량 모델에서 조금이라도 더 메모리를 아낄 수 있다는 점에서 의미가 있다.
3. 참고사항
AdapterFusion: Non-Destructive Task Composition for Transfer Learning
https://arxiv.org/abs/2005.00247
QLoRA: Efficient Finetuning of Quantized LLMs
https://arxiv.org/abs/2305.14314
