0. Intro
Image Processing
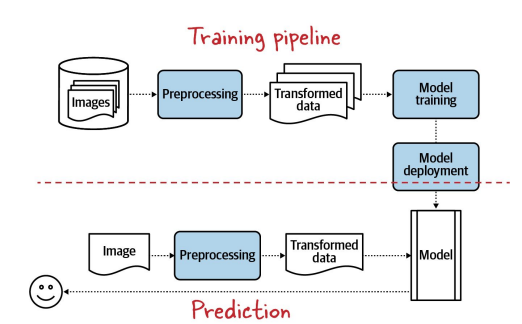
-> 의미있는 feature와 representation을 추출하는데 도움을 줌.,
1. Color Space
Color space : Image의 색 공간을 정의 -> 색을 디지털적으로 표현하고 해석하기 위해 정의된 수학적 모델
1.1 Color space 종류
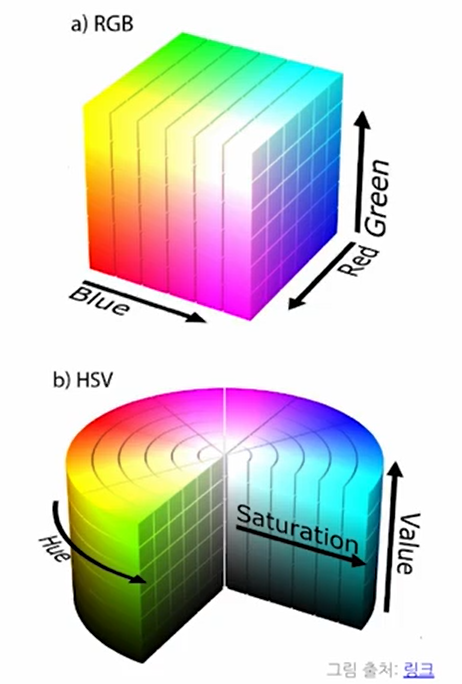
- RGB : Red, Green, Blue
- HSV : Hue(색상), Saturation(채도), Value(명도)
- Lab : L(Lightness), a(Green-Red), b(blue-Yellow)
- YCbCr
- Grayscale : 밝기
-> 컬러 정보다 필요하지 않는 명암 대비, 텍스처 분석.
1.2 OpenCV를 이용한 방법
opencv툴로 Color space를 바꿀 수 있다.(opencv는 기본이 RGB가 아니라 BGR임.)
#BGR -> HSV
img_hsv = cv.cvtColor(img_bgr, cv.COLOR_BGR2HSV)
#BGR -> Lab
img_lab = cv.cvtColor(img_bgr , cv.COLOR_BGR2LAB)1.3 Color Space Manipulation
- Historgram Smoothing
img_gray = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2GRAY)
img_equalized = cv2.equalizeHist(img_gray)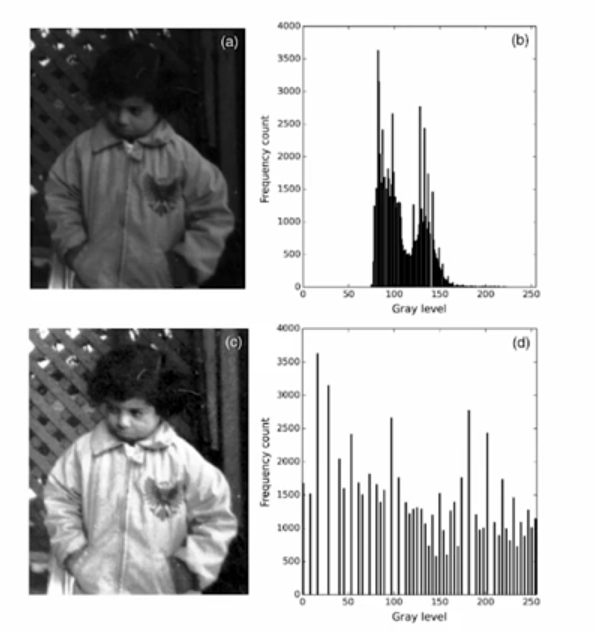
-> Histogram Equalization 은 밝기 분포를 재분배하여 대비를 향상시키고 대비가 낮은 이미지의 세부 사항을 더 잘 보이게 합니다.
- Color-based Segmentation(사람 피부 detection)
https://arxiv.org/pdf/1708.02694 (시간남으면 재미삼아 읽어보셈.)
2. Geometric Transform
Geometric Transform이란, Image를 변형하는 데 사용되는 다양한 수학적 기법이다.
- Translation, rotation, scaling , shearing , persperctive 등등
🤔 왜 중요할까?
👉 CNN은 아무런 input size도 다 받아들여지는데, Feature크기의 패턴을 찾는 방법을 학습함
-> 그렇다는 의미는 입력 이미지의 크기를 조정하면 학습 패턴의 크기가 변경됨.
CNN이 feature를 추출하는 예시
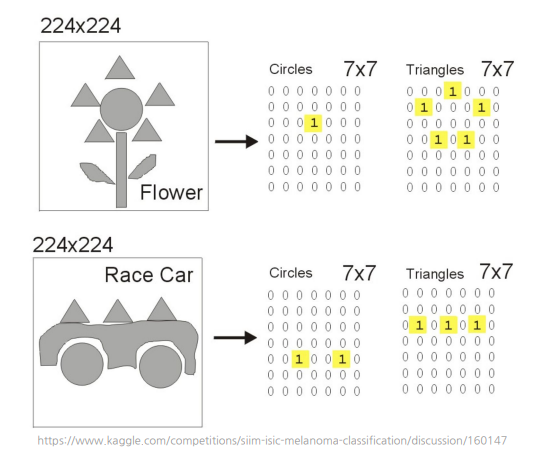
이렇게 Image 크기를 변경하면 Object를 찾을 수도 있고 못 찾을 수도 있다.
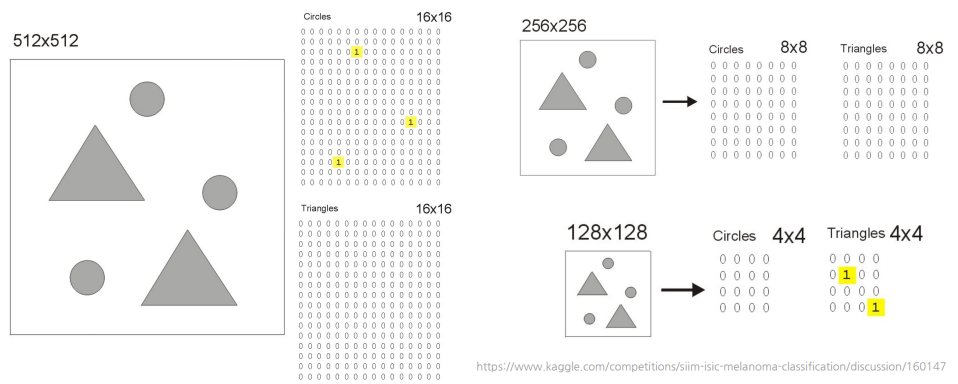
✍️Image의 변형을 통해 다양성을 부여
- CNN이 학습되면서 다양한 패턴을 학습한 커널이 만들어짐
- 다양하게 변형된 이미지가 주어진 문제에 잘 맞을지 생각해보고 검증이 필요함.
2.1 Translation
물제의 위치 이동

import numpy as np
import cv2 as cv
img = cv.imread("img.jpg")
rows, cols = img.shape[:2]
M = np.float32([1,0,100],[0,1,50],[0,0,1]) #이미지를 x축으로 100, y축으로 50만큼 이동시키는 변환을 정의함.
dst = cv.warpPerspective(img, M, (cols, rows)) ## 정의된 변환 행렬 M을 이용해 원본 이미지를 변환.
# # 변환된 이미지를 dst에 저장, 이미지 크기는 원본과 동일하게 설정 (cols, rows).2.2 rotation
각도 만큼 이동
import numpy as np
import cv2 as cv
img = cv.imread("img.jpg")
rows, cols = img.shape[:2]
M = cv.getRotationMatrix2D((col/2,rows/2),90,1)
M = np.vstack([M,[0,0,1]])
dst = cv.warpPerspective(img, M, (cols,rows))2.3 Scaling
이미지의 크기 조정
import numpy as np
import cv2 as cv
img = cv.imread("img.jpg")
rows, cols = img.shape[:2]
M = np.float32([[2,0,0],[0,2,0],[0,0,1]])
dst = cv.warpPerspective(img, M, (2*cols,2*rows))2.4 Perspective Transformation
import numpy as np
import cv2 as cv
img = cv.imread("img.jpg")
rows, cols = img.shape[:2]
pst1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pst2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv.getPerspectiveTransform(pst1,pst2)
dst = cv.warpPerspective(img,M,(300,300))perspective ex)

3. Data Augmentation
3.1 Data Augmentation이란?
견고한(robust) 모델 학습을 위해 입력 Image의 다양성을 증가시킬수 있는 기법으로,주어진 데이터를 인위적으로 늘리는 것.
3.2 Common Augmentation
- Flip(horizontal, vertical)
- Rotations
- Crops(random, center)
- Color jitter

(귀엽다..!)
3.3 Augmentation Library
- Albumentation
- Torchvision
- Imgaug
import albumentations as A
transform = A.compose([
A.HorizontalFlip(p =0.5),
A.RandomBrightnessContrast(p =0.2),
A.RandomCrop(height = 224, weight = 224)]
)자동으로 Augmentation 해주는 Technique
① AutoAugment : 데이터셋에 맞춘 최적의 augmentation정책을 자동으로 검색 (강화학습을 하고 함 -> 그래서 컴퓨테이싱이 많이 듬)

② RandAugment : 랜덤한 크기로 augmentation 의 하위집합 무작위로 적용

4. Normalization
4.0 Normalization 하는 이유
빠르게 학습하고 경사하강법을 최적으로 적용하기 위함
4.1 Image Min-Max Normalization
이미지 데이터를 [0,1] 범위로 스케일링
4.2 Z-score Normalization(standardization)
-> 딥러닝 프레임워크 코드
transforms.Nomalize()4.3 Batch Normalization
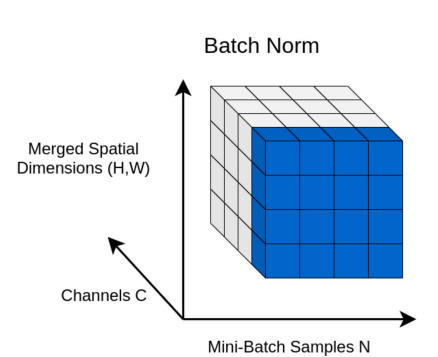
mini-batch 단위로 입력 데이터를 정규화
- Internal covariate shift문제를 개선
- Initialization 에 대한 민감도 감소
(Internal covariate shift: 학습 시 파라미터가 업데이트 되면서 입력분포가 변화하는 현상.)
4.4 Normalization 과 ToTensor순서
코드 순서가 다르므로 조심하자.
Pytorch Transform
from torchvision import transforms transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize( mean = [0.485,0.456,0.406], std = [0.229, 0.224,0.225] ) ]) # ToTensor로 먼저 텐서로 바꾸고 나서 한다.
Albumentations
import albumentations as A from albumentations.pytorch import ToTensorV2 transform = A.Compose([ A.Normalize( mean = [0.485,0.456,0.406], std = [0.229, 0.224,0.225], ToTensorV2() ) ])
⚠️ transform 라이브러리는 정책에 따라 바뀔수 있으므로 조심.
5. 참고 논문
-
A survey on Image Data Augmentation for Deep learning
: https://journalofbigdata.springeropen.com/articles/10.1186/s40537-019-0197-0 -
AutoAugment: Learning Augmentation Policies from Data
: https://arxiv.org/abs/1805.09501 -
RandAugment: Practical automated data augmentation with a reduced search spac
: https://arxiv.org/abs/1909.13719
